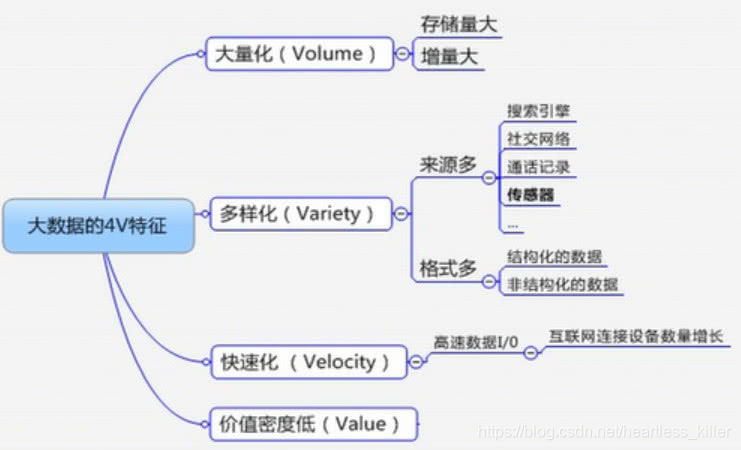
大数据四大特征或4V特征
Volume:体量大
Variety:样式多
Velocity:速度快
Valueless:价值密度低
价值密度低:
去IOE:
I:ibm 小型机
O:oracle 数据库
E:EMC 共享存储设备
hadoop基本概念
Hadoop 是一个分布式系统基础架构,它可以使用户在不了解分布式底层细节的情況下开发分布式程序,充分利用集群的威力进行高速运算和存储。
从其定义就可以发现,它解決了两大问题:大数据存储、大数据分析。也就是 Hadoop 的两大核心:HDFS 和 MapReduce。
- HDFS是可扩展、容错、高性能的分布式文件系统,异步复制,一次写入多次读取,主要负责存储。
- MapReduce 为分布式计算框架,包含map(映射)和 reduce(归约)过程,负责在 HDFS 上进行计算。
Hadoop 是一个能够让用户轻松架构和使用的分布式计算的平台。用户可以轻松地在 Hadoop 发和运行处理海量数据的应用程序。其优点主要有以下几个:
(1) 高可靠性 : Hadoop 按位存储和处理数据的能力值得人们信赖。
(2) 高扩展性 : Hadoop 是在可用的计算机集簇间分配数据并完成计算任务的,这些集簇可以方便地扩展到数以干计的节点中。
(3) 高效性 : Hadoop能够在节点之间动态地移动数据,并保证各个节点的动态平衡,因此处理速度非常快。
(4) 高容错性 : Hadoop能够自动保存数据的多个副本,并且能够自动将失败的任务重新分。
(5) 低成本 : 与一体机、商用数据仓库以及 QlikView、 Yonghong Z- Suites 等数据集市相比,Hadoop 是开源的,项目的软件成本因此会大大降低。
Hadoop 带有用 Java 语言编写的框架,因此运行在 linux 生产平台上是非常理想的, Hadoop 上的应用程序也可以使用其他语言编写,比如 C++。
适合
-
大规模数据
-
流式数据(写一次,读多次)
-
商用硬件(一般硬件)
不适合
- 低延时的数据访问
- 大量的小文件
- 频繁修改文件(基本就是写1次)
Hadoop架构
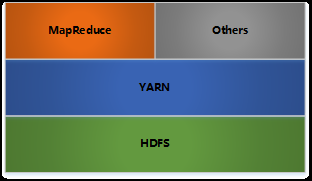
HDFS: 分布式文件存储
YARN: 分布式资源管理
MapReduce: 分布式计算
Others: 利用YARN的资源管理功能实现其他的数据处理方式
内部各个节点基本都是采用Master-Woker架构
