前言
大家好,牧码心今天给大家推荐一篇Elasticsearch系列(一)—全文检索的文章,在实际工作中有很多应用场景,希望对你有所帮助。内容如下:
- 背景
- 什么是全文检索
- 为什么使用全文检索
- 什么时候使用全文检索
- 全文检索的流程
- 主流开源框架:Lucene,Solr,ElasticSearch
背景
谈到搜索引擎,大家都会联想到百度,谷歌等商业搜索工具。各大垂直网站,如电商,新媒体,汽车等行业网站也都有搜索功能。搜索引擎在互联网的方方面面都有应用。什么是搜索引擎呢?百度百科定义:
搜索引擎是指根据一定的策略、运用特定的计算机程序从互联网上采集信息,在对信息进行组织和处理后,为用户提供检索服务,将检索的相关信息展示给用户的系统。搜索引擎是工作于互联网上的一门检索技术,它旨在提高人们获取搜集信息的速度,为人们提供更好的网络使用环境。从功能和原理上搜索引擎大致被分为全文搜索引擎、元搜索引擎、垂直搜索引擎和目录搜索引擎等四大类。
通俗的说,搜索,就是在特定场景下,通过语音或文字输入关键词来寻找需要的信息。
什么是全文检索
全文检索是搜索引擎的原理之一,在网络上的大部分搜索服务都用到了全文检索技术。什么是全文检索?百度百科定义:
全文搜索引擎是目前广泛应用的主流搜索引擎。它的工作原理是计算机索引程序通过扫描文章中的每一个词,对每一个词建立一个索引,指明该词在文章中出现的次数和位置,当用户查询时,检索程序就根据事先建立的索引进行查找,并将查找的结果反馈给用户的检索方式。这个过程类似于通过字典中的检索字表查字的过程。
为了更好的理解全文检索,先从常见的数据类型说起。常见的数据类型总体可分为:结构化数据和非结构化数据。
- 结构化数据:指具有固定格式或有限长度的数据,如数据库,元数据等。
- 非结构化数据:非结构化数据又可称为全文数据,指不定长或无固定格式的数据,如邮件,文档,视频等。
- 半结构化数据:如定义好的xml,json等结构的数据,根据需要可按结构化数据来处理,也可抽取出纯文本按非结构化数据来处理。
对于结构化数据,我们一般都是可以通过关系型数据库(mysql,oracle等)的方式存储和搜索,也可以建立索引。
对于非结构化数据,主要有两种方法:顺序扫描法,全文检索
- 顺序扫描法
所谓顺序扫描,比如要找内容包含某一个字符串的文件,就是一个文档一个文档的看,对于每一个文档,从头看到尾,如果此文档包含此字符串,则此文档为我们要找的文件,接着看下一个文件,直到扫描完所有的文件。如利用windows的搜索也可以搜索文件内容,只是相当的慢 - 全文检索
对非结构化数据顺序扫描很慢,我们是否可以进行优化?,我们可将非结构化数据中的一部分信息提取出来,重新组织,使其变得有一定结构,然后对此有一定结构的数据进行搜索,从而达到搜索相对较快的目的。这部分从非结构化数据中提取出的然后重新组织的信息,我们称之索引。
例如:书籍,书籍中包含大量的文本,图片等非结构化数据,如果需要找其中某个词或段,甚至章节,在没有目录和页码的前提下,需要在整个书籍中一个一个词顺序的去扫描。而目录则可优化检索效率,我们将数据分为章节,段落,并标识出对应的页码,从而达到结构化处理。我们检索时,根据页码定位到需要查找的非结构化数据。这种先建立索引,再对索引进行搜索的过程就叫全文检索(Full-text Search)。
为什么使用全文检索
我们平时接触到mysql,oracle等关系型数据库里都提供了查询检索或者聚合分析功能,我们大部分的查询功能都可以通过数据库查询获得,如果查询效率低下,还可以通过建数据库索引,优化SQL等方式进行提升效率,甚至通过引入缓存来加快数据的返回速度。如果数据量更大,就可以分库分表来分担查询压力。那为什么还需要全文检索的搜索引擎呢?我们主要从以下几个方面分析:
- 数据类型
全文索引搜索支持非结构化数据的搜索,可以更好地快速搜索大量存在的任何单词或单词组的非结构化文本。
例如 Google,百度类的网站搜索,它们都是根据网页中的关键字生成索引,我们在搜索的时候输入关键字,它们会将该关键字即索引匹配到的所有网页返回;还有常见的项目中应用日志的搜索等等。对于这些非结构化的数据文本,关系型数据库搜索不是能很好的支持。 - 索引维护
一般关系型数据库,全文检索都实现的很鸡肋,因为一般也没人用数据库存文本字段。进行全文检索需要扫描整个表,如果数据量大的话即使对SQL的语法优化,也收效甚微。建立了索引,但是维护起来也很麻烦,对于 insert 和 update 操作都会重新构建索引。
什么时候使用全文检索
- 搜索的数据对象是大量的非结构化的文本数据。
- 文件记录量达到数十万或数百万个甚至更多。
- 支持大量基于交互式文本的查询。
- 需求非常灵活的全文搜索查询。
- 对高度相关的搜索结果的有特殊需求,但是没有可用的关系数据库可以满足。
- 对不同记录类型、非文本数据操作或安全事务处理的需求相对较少的情况。
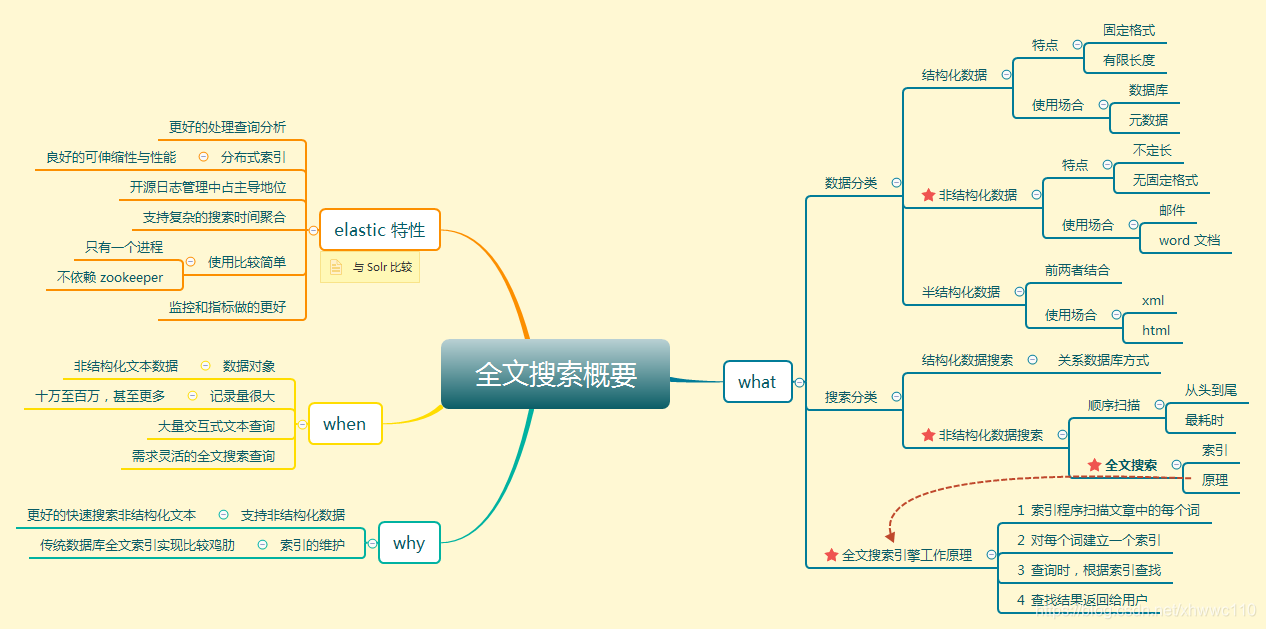
全文检索的流程
我们先梳理下全文检索的流程,流程如图所示:
1.绿色表示索引过程,对要搜索的原始内容进行索引构建一个索引库,索引过程包括:
确定原始内容即要搜索的内容->采集文档->创建文档->分析文档->索引文档;
2.红色表示搜索过程,从索引库中搜索内容,搜索过程包括:
用户通过搜索界面->创建查询->执行搜索,从索引库搜索->渲染搜索结果;
整个过程分为:
- 创建索引
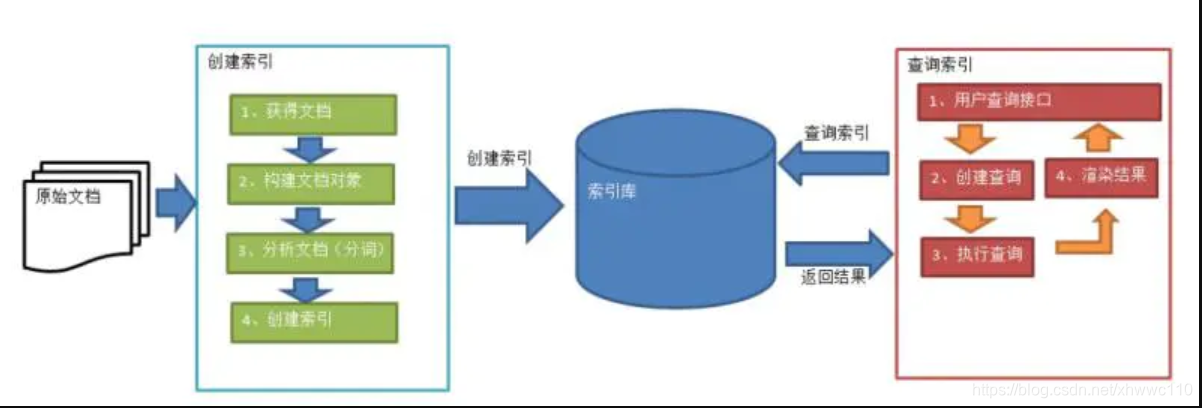
创建索引也就是对文档索引的过程,将用户要搜索的文档内容进行索引,索引存储在索引库(index)中。需要对语汇单元索引,通过词语找文档,这种索引的结构就叫做叫倒排索引结构。
倒排索引结构是根据内容(词语)找文档,如下图:
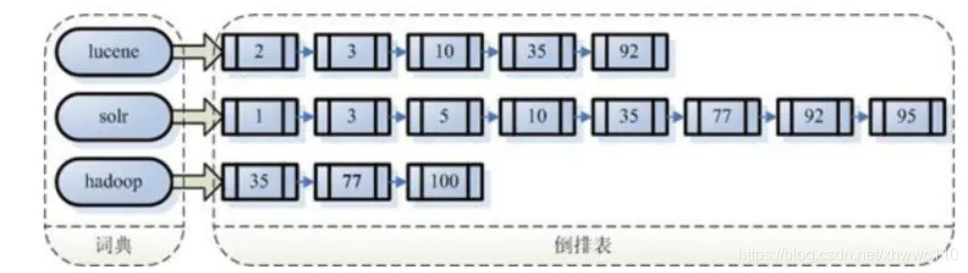
倒排索引结构也叫反向索引结构,包括索引和文档两部分,索引即词汇表,它的规模较小,而文档集合较大。
有倒排索引,则也有正向索引。 正向索引其实就是顺序扫描所有文件,这样本身效率是极低的。 - 查询索引
查询索引也是搜索的过程。搜索就是用户输入关键字,从索引(index)中进行搜索的过程。根据关键字搜索索引,根据索引找到对应的文档,从而找到要搜索的内容。
比如我们使用百度搜索全文检索时,为我们展示的是相关网页地址,再根据地址找到具体的文档内容。
主流开源框架:Lucene,Solr,ElasticSearch
-
Lucene
Lucene是一个Java全文搜索引擎,完全用Java编写。Lucene不是一个完整的应用程序,而是一个代码库和API,可以很容易地用于向应用程序添加搜索功能。
但是Lucene的API过于底层,并不简单易用,而且缺乏企业级的管理工具对其进行监控管理,于是企业级的全文检索引擎就应运而生了,目前最流行的两个就是:Solr和ES。他们都是建立在Lucene之上的。 -
Solr
Solr是一个基于名为Lucene的Java库构建的开源搜索平台。它以用户友好的方式提供Apache Lucene的搜索功能。作为一个行业参与者近十年,它是一个成熟的产品,拥有强大而广泛的用户社区。它提供分布式索引,复制,负载平衡查询以及自动故障转移和恢复。如果它被正确部署然后管理得好,它就能够成为一个高度可靠,可扩展且容错的搜索引擎。很多互联网巨头,如Netflix,eBay,Instagram和亚马逊(CloudSearch)都使用Solr,因为它能够索引和搜索多个站点。 -
ElasticSearch
ElasticSearch是一个实时的,可扩展的分布式RESTful搜索引擎,它可以用于全文搜索,结构化搜索以及分析。由于Lucene过于复杂,不方便使用。Elasticsearch使用Lucene作为内部引擎,使用Elasticsearch做搜索引擎时,只需要使用统一的API就可以,而不需要了解复杂的Lucene原理。
分布式搜索引擎包括可以划分为分片的索引,并且每个分片可以具有多个副本。每个Elasticsearch节点都可以有一个或多个分片,其引擎也可以充当协调器,将操作委派给正确的分片。
Elasticsearch提供功能,包括主要功能列表包括:- 分布式搜索
- 多租户
- 分析搜索
- 分组和聚合
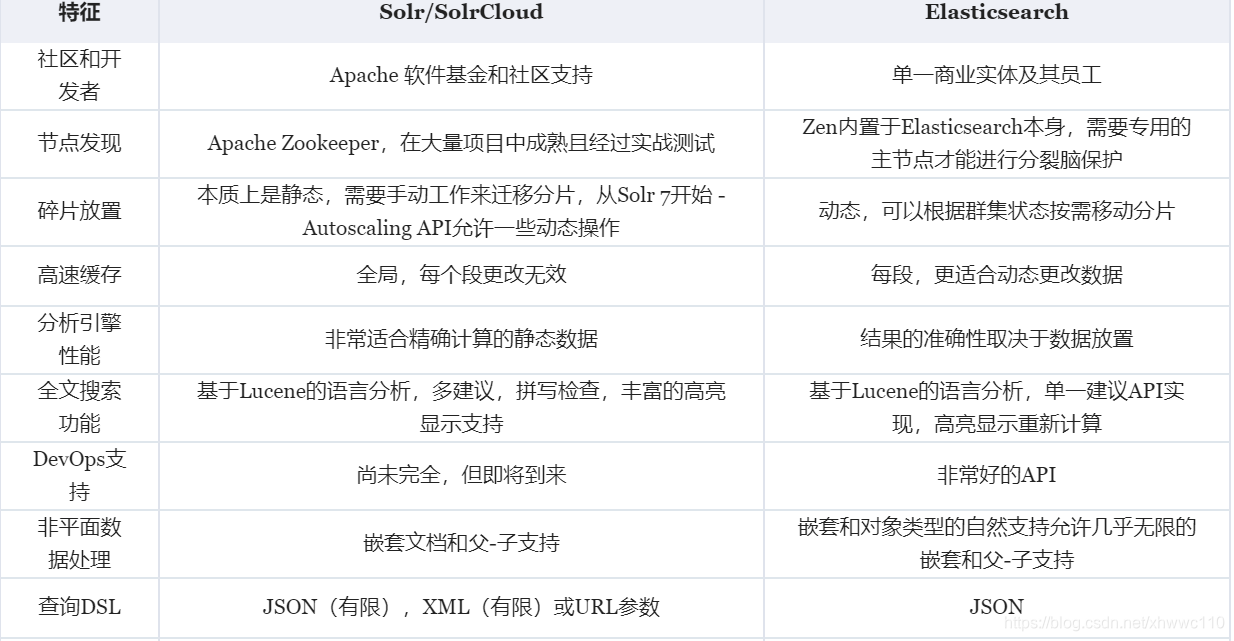
Solr、ElasticSearch 对比
由于Lucene的复杂性,一般很少会考虑它作为搜索的第一选择,排除一些公司需要自研搜索框架,底层需要依赖Lucene。所以这里我们重点分析 Elasticsearch 和 Solr。
Elasticsearch vs. Solr。哪一个更好?他们有什么不同?你应该使用哪一个?具体看如下图比较:了解更多
总结
本文主要介绍了搜索引擎背景,全文检索和主流的开源框架对比。总的来说ElasticSearch在近几年已经发展很迅速,基于ElasticSearch的生态圈也在扩大,如:kibana,logstash,beats等。相信ElasticSearch未来会成为搜索引擎的主流开源框架。
参考地址
- https://www.cnblogs.com/jajian/p/9801154.html
