这里不多说线程和进程的区别了,直接看线程在Java中如何使用。
1、线程的创建和启动方式
1.1 继承Thread类创建线程类
让一个类继承Thread,并重写其中的run()方法,该run()方法中定义的就是线程需要做的事。所以run()方法是线程执行体。
以上是定义一个线程类,要让线程类执行还需要创建这个类的实例,并执行实例的start()方法启动该线程。定义和启动的示例代码如下。
public class FirstThread extends Thread{
private int i;
public void run(){
for(; i < 20; i++){
System.out.println(this.getName() + " " + i);
}
}
public static void main(String[] args) {
for(int j = 0; j < 100; j++){
System.out.println(Thread.currentThread().getName() + " " + j);
if(j == 20){
new FirstThread().start();
new FirstThread().start();
}
}
}
}
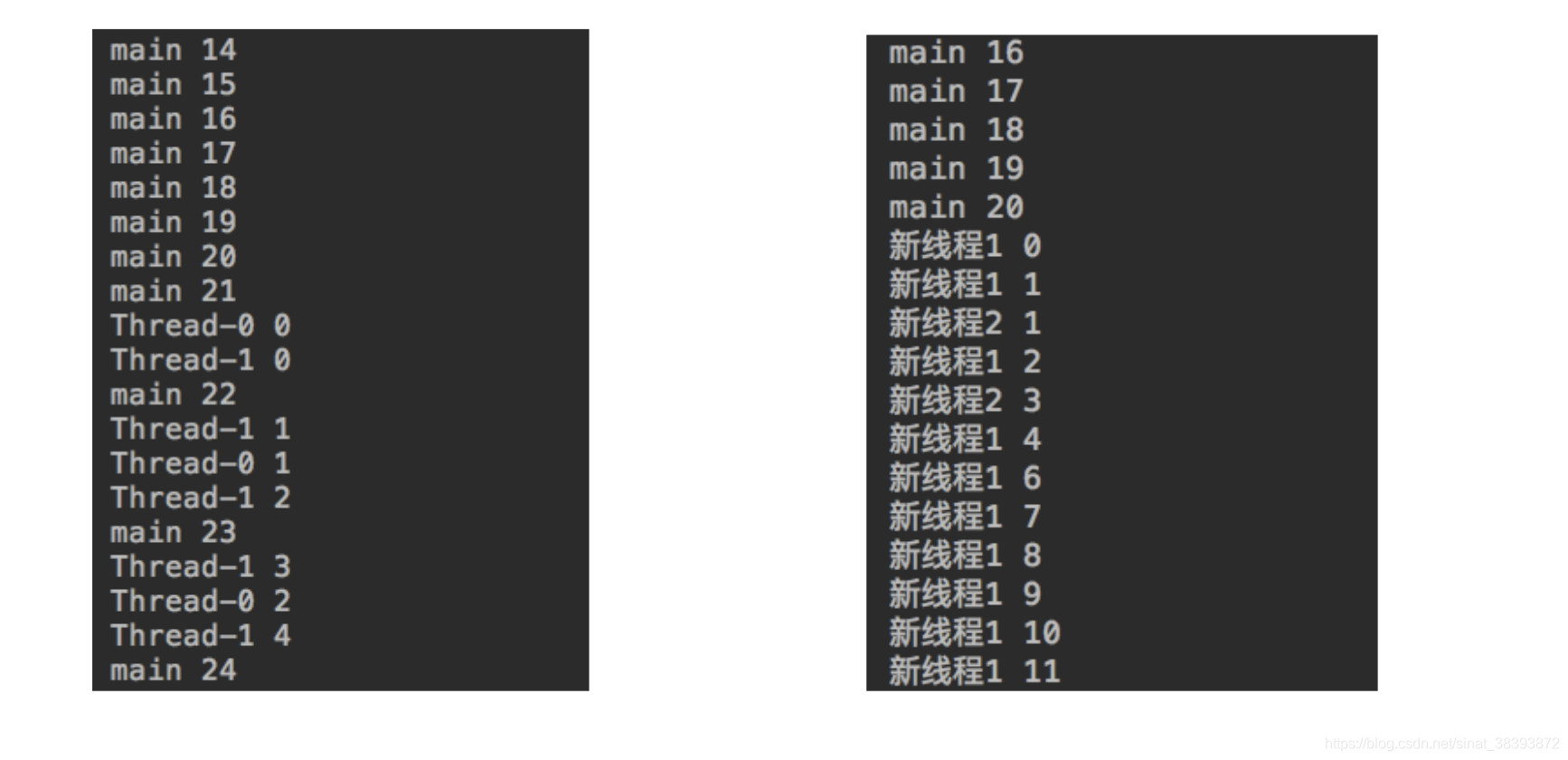
这段代码的输出如下

这段代码的入口是main函数。main函数开始运行时就启动了一个主线程,从上图中可以看出主线程的名字是main。主线程启动后就开始循环输出j。当j=20时,主线程就会开启两个线程。当然这两个线程开启后不一定会马上开始执行,于是主线程和另外两个线程开始随机执行。
上面的代码中涉及到了两个方法,可能比较常用。
- Thread.currentThread():这是Thread的静态方法,用来返回当前正在执行的线程对象。
- getName():该方法是Thread的实例方法,返回该线程的名字。默认情况下,主线程名字是main,其它线程创建顺序不同名字依次是Thread-0,Thread-1…等。
虽然同一个进程中的子线程是可以共享变量的,但是继承于Thread类的线程类A,我们多次调用A的start()方法,即启动了多个线程,这些线程的成员变量不是共享的,每个线程各自拥有属于自己的成员变量。就像上面例子中Thread-1和Thread-0的i不是共享的。
1.2 实现Runnable接口创建线程类
实现Runnable接口,并重写其中的run()方法,该run()方法和继承Thread类中的一样。
创建该类的实例,然后将实例作为参数放到Thread类的构造函数中构造出新的线程,然后调用线程的start()方法启动线程。示例代码如下。
public class FirstThread implements Runnable{
private int i;
public void run(){
for(; i < 20; i++){
System.out.println(Thread.currentThread().getName() + " " + i);
}
}
public static void main(String[] args) {
for(int j = 0; j < 100; j++){
System.out.println(Thread.currentThread().getName() + " " + j);
if(j == 20){
FirstThread runnable = new FirstThread();
new Thread(runnable, "新线程1").start();
new Thread(runnable, "新线程2").start();
}
}
}
}
代码的执行结果如下

Thread的构造函数可以对线程命名,如代码所示。
这里有一点是需要注意到的,就是我们通过继承Thread类定义一个线程类A后,多次调用A的start()方法,即创建多个线程。那么这些线程之间是不会共享实例变量的,所以继承Thread类的线程类的输出结果如图一所示,两个线程的i并不是同一个i。而实现Runnable接口的线程类的实例之间是互相共享实例变量的,所以右图中的输出两个线程的i是连续的
1.3使用Callable和Furture创建线程
Callable可以看成是Runnable的增强版。Callable提供了一个call()方法作为线程执行体,并且call()方法可以有返回值并且可以抛出异常。call()方法对于Callable而言就是Runnable中的run()方法,call()方法里定义线程的逻辑。
刚刚说call()方法可以有返回值。Callable是个泛型接口,Callable,T就是call()方法的返回值的类型。
但Callable并不能像Runnable那样直接作为Thread的参数构造出新线程。Callable想要构造出新线程必须通过FutureTask类。下面来看看FutureTask如何构造一个线程。FutureTask实现接口Future。
创建线程之前先定义一个FutureTask实例。
FutureTask类的其中一个构造函数如下图所示
Callable是函数式接口,并且唯一的抽象方法call()就是定义线程逻辑,所以为了简单点写代码,我们用Lambda表达式实例化FutureTask。(有关Lambda表达式和函数式接口可以看这篇文章)
FutureTask<Integer> futureTask = new FutureTask((Callable<Integer>) () -> {
int i = 0;
for(; i < 100; i++){
System.out.println(Thread.currentThread().getName() + "的i的值是" + i);
}
return i;
});
有了FutureTask实例后,就可以像Runnable那样启动一个线程,所以整个线程的demo如下所示
FutureTask<Integer> task = new FutureTask((Callable<Integer>) () -> {
int i = 0;
for(; i < 100; i++){
System.out.println(Thread.currentThread().getName() + "的i的值是" + i);
}
return i;
});
for(int i = 0; i < 100; i++){
System.out.println(Thread.currentThread().getName() + "的i的值是" + i);
if(20 == i){
//新建线程并启动
new Thread(task, "有返回值的线程").start();
}
}
执行结果如下图所示

前面说了线程是有返回值的,Future接口提供了好几个方法来控制它关联的Callable任务,其中就包括获取返回值。
- V get():返回Callable任务里的call()方法的返回值。调用该方法会导致程序阻塞,必须等到子线程结束后才会得到返回值。
2、线程的生命周期
线程的生命周期是:新建、就绪、运行、阻塞、死亡。
2.1 新建和就绪
当new一个线程时,该线程就处于新建状态,和其它普通Java对象一样,Java虚拟机只是给它分配内存并初始化成员变量的值。这时的线程并没有表现出线程的动态特征。
线程对象调用start()方法后,线程就处于就绪状态,Java虚拟机会为其创建方法调用栈和程序计数器。处于这个状态的线程还没运行,但随时可能进入运行状态,具体情况要看Java虚拟机的调度。
注意是使用start()方法启动线程,而不是run()。而且一旦直接调用了 run()方法,那这个线程对象就只会被看成是普通对象,即使之后再调用start()方法也没用了。
2.2运行和阻塞
一个CPU在同一时间只能有一个线程处于运行状态。
发生以下情况时,线程会发生阻塞。
- 线程调用sleep()方法主动放弃占有的资源。
- 线程调用了阻塞式的I/O方法,在方法返回之前,线程被阻塞。
- 线程试图获取一个同步监听器,而这同步监听器正被其它线程锁持有。
- 线程在等待某个通知(notify)。
- 程序调用了线程的suspend()方法将线程挂起。但这个方法容易引起死锁,所以应该尽量避免使用该方法。
正在执行的程序被阻塞之后会在何时的时间进入就绪状态。针对上面的几种情况,发生以下的事件会让线程进入就绪状态。
- 调用sleep()的线程经过了指定时间。
- 线程调用的阻塞式I/0方法已经返回。
- 线程成功地获取了试图取得的同步监视器。
- 线程正在等待某个通知时,其它线程发出了一个通知。
- 处于挂起状态的线程调用了resume()回复方法。
2.3线程死亡
当发生下面三种情况时,线程会死亡。
- run()或call()方法执行完成,线程正常结束。
- 线程抛出一个为捕获的Exception或Error。
- 直接调用该线程的stop()方法来结束该线程,但这方法容易引起死锁。
为了测试某个线程是否已经死亡,可以调用线程对象的isAlive()方法,当线程处于就绪,运行,阻塞三种状态时,该方法返回true;当线程处于新建,死亡两种状态时,方法返回false。
对于已死亡的线程和已经启动的线程,若再次调用start()方法,会抛出IllegalThreadStateException异常。
3、控制线程
这一节讲的是如何控制控制线程的状态,比如让某个线程获得更多的执行机会(设置优先级),线程中断以后处理方式等等。
3.1 线程的 join()方法:暂停,让我先行
Thread提供了让一个线程等待另一个线程的方法,join()方法。当一个线程A的执行体中新建了另一个线程B,并启动线程B的start()方法,然后执行线程B的join()方法,那线程A会一直等待线程B执行完毕后,才会开始重新执行未完成的代码。
注意,以上的过程必须是按顺序的,线程B要先执行start()方法后才能执行join()方法。
另外,关于执行体的解释需要详细说一下。这里的执行体在代码中是指两个地方:一是主函数的psvm代码块,二是线程的run()方法里。
第一种是主程序中定义了一个线程A,执行这个线程A的join()方法时,主程序的执行会暂停,一直等到线程A结束后才开始执行。网上的很多例子介绍线程的join()方法时,举的例子都是第一种情况。
但第二种情况很少见,我担心线程A的run中执行线程B的join()方法时,出现的结果不符合预期,于是我做了以下测试。
public class Test {
public static void main(String[] args) {
new Thread(() -> {
for(int i = 0; i < 20; i++){
System.out.println("子线程A " + i);
if(i == 10){
Thread thread = new Thread(() -> {
for(int j = 0; j < 20; j++){
System.out.println("子线程B " + j);
}
}, "子线程B");
thread.start();
try{
thread.join();
} catch(Exception e){}
}
}
}, "子线程A").start();
}
}
输出结果如下,线程B在线程A中执行join()方法后,线程A就立刻暂停。直到线程B执行结束以后,线程A才开始执行。
后台线程:
后台线程是用来服务其它线程的,比如JVM就是典型的后台线程。后台线程有个特征:所有的前台线程死亡后,后台线程才会自动死亡。
前台线程创建的线程是前台线程,后台线程创建的线程是后台线程。
主线程默认是前台线程,所以我们平时创建的线程都是前台线程。
将一个线程设置为后台线程的方法是通过线程实例的setDaemon(true)方法。判断一个线程是不是后台线程可用isDaemon()方法,返回true则为后台线程,反之为前台线程。
线程一旦进入就绪状态,即执行start()之后,就不能再更改线程属性,即不能条用setDaemon()方法,否则会引起IllegalThreadStateException异常。所以线程的setDaemon()方法必须在start()方法之前执行。
线程睡眠
sleep()方法可让当前正在执行的线程进入阻塞状态。下面是sleep()方法的文档
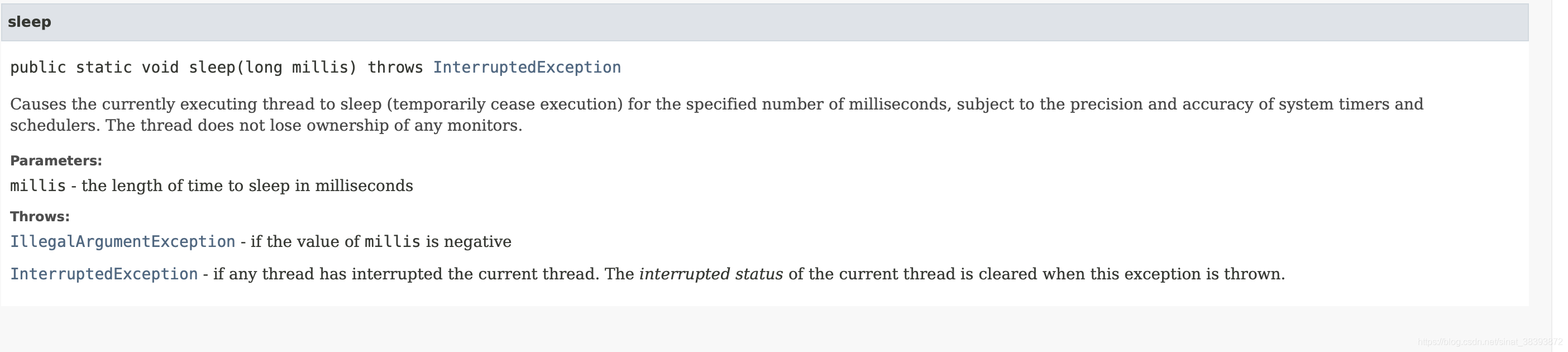
要注意到sleep()是静态方法不是实例方法,所以它的功能是让当前正在执行的方法进入阻塞状态
线程让步
yield()和sleep()方法类似,两者都是静态方法,并且都是让现正在运行的线程暂停。不过不同的是,sleep()是让线程进入阻塞状态,而yield()是让线程进入就绪状态。
所以执行yield()后,即使当前执行的线程转入就绪状态,但下一个瞬间它还是有可能被选中继续执行。
改变线程优先级
每个线程具有一定的优先级,优先级高的线程会获得更高的执行机会。
Thread类提供了setPriority(int newPriority)和getPriority()两个实例方法来设置线程的优先级和获取线程的优先级。优先级是int类型,从1到10,数字越大优先级越高。Thread有三个静态变量表示优先级,
- MAX_PRIORITY:值为10。
- MIN_PRIORITY:值为1。
- NORM_PRIORITY:值为5。
当然,不同的操作系统的优先级不一定都是1到10,比如Windows 2000就只提供了7个优先级,所以编程时要避免直接为线程指定数字的优先级,而要用上面三个静态变量确保高移植性。
主线程的优先级默认是5,子线程的优先级默认与父线程的优先级相等,所以平时我们创建的子线程默认优先级为5。
中断线程
3、线程的同步
多线程环境下,一个线程的执行随时会被另一个线程打断。一般情况下这没什么,等会再继续执行呗。但是如果是多个线程同时访问操作一个公共资源,那就很可能出现问题。学过操作系统的都知道,多个线程同时读一个资源完全不会有事,但只要涉及到写,那就会出现隐患,无论是同时写还是同时读写。
同步解决的就是多线程访问操作同一公共资源时可能出现的问题。解决方式是加锁,一个线程想要访问操作一个资源时,就必须先取得关于这个资源的锁才能继续。当线程取得锁,完成相关操作后,才会将锁还回去,其他线程才有机会获得锁。
Java中加锁是通过synchronized和lock,下面一一讲解。
3.1 synchronized
synchronized有两种使用方法,一种是同步代码块,另一钟是同步方法,两者的主要区别是加锁的对象不同。
3.1.1同步代码块
先说说同步代码块,同步代码块的语法是
synchronized(obj){
···
}
其中的obj是线程之间的共享变量,如果这个变量是线程独有的,那加这个锁毫无意义。
这个语法的含义是,在线程执行括号包含的代码之前,必须先获得关于obj这个公共资源的锁后才能执行。而且obj同一时间内只能被一个线程锁住,而且只有这个线程执行完之后才会将锁释放,然后别的线程才能进入这个代码块执行。
3.1.2同步方法
同步方法的语法是在方法(必须是实例方法),代码如下
public synchronized void test(){
...
}
只要将synchronized 放在限定词之后,返回值之前就行了。要记住,同步方法是对this加锁,也就是这个方法的调用者,而不是对这个方法加锁。
一个类A有两个方法,一个加锁一个不加,代码如下
class A{
public synchronized void a(){...}
public void b(){...}
}
生成两个线程和A的实例对象,线程1执行实例的a方法,线程2执行实例的b方法。因为a方法加上了锁,所以线程1在执行a方法前,要先取得关于实例对象的锁;而方法b没加锁,所以线程2随时可以执行b方法。
于是写了下面的代码
class A{
public synchronized void a(){
int i = 0;
for (; i < 20; i++){
System.out.println("方法a:" + i);
}
}
public void b(){
int i = 0;
for (; i < 100; i++){
System.out.println("方法b:" + i);
}
}
}
public class Test {
public static void main(String[] args) throws Exception{
A a = new A();
FutureTask<Integer> task1 = new FutureTask<>(() -> {
//对象a的a方法没加锁,即访问a方法需要获得关于a对象的锁
a.a();
return;
});
FutureTask<Integer> task2 = new FutureTask<>(() -> {
//对象a的a方法没加锁,即访问a方法需要获得关于a对象的锁
a.a();
return;
});
FutureTask<Integer> task3 = new FutureTask<>(() ->{
//对象a的b方法没加锁,即访问b方法不需要获得关于a对象的锁
a.b();
return;
});
//线程1
new Thread(task1).start();
//线程2
new Thread(task2).start();
//线程3
new Thread(task3).start();
}
}
根据上面的分析,线程1和线程2会争夺锁。因为线程1先得到锁,所以线程2必须等到线程1释放锁以后(上面的例子中线程1释放锁就相当于线程1执行完成),才能有机会获得锁。所以预测线程2要等到线程1执行完成之后才会开始执行a方法。
而线程3调用的b方法不需要获得锁,所以线程3会随机执行。
运行上面的代码,执行结果验证了以上的分析。

可以看到,线程1和线程2是交替执行的。
但是如果把方法b也加上锁
//其余代码不变
public synchronized void b(){
int i = 0;
for (; i < 100; i++){
System.out.println("方法b:" + i);
}
}
//其余代码不变
那么执行结果就变成了严格的顺序执行,而两个线程访问的是不同方法,所以同步方法是对this加锁,而不是对方法加锁。

3.1.3锁释放的时间
- 当线程的同步区的代码执行完自动释放锁。
- 当同步区的代码出现return或break使程序跳出同步区,则锁自动释放。
- 当同步区的代码出现为处理的Error或Exception导致同步区代码结束时,锁自动释放。
- 当同步区代码执行时,出现线程的wait()操作,则线程被暂停并释放锁
要注意,以下的操作并不会释放锁。
- 程序调用了Thread.sleep()和Thread.yield()使线程暂停时,线程不会释放锁
- 程序调用suspend()方法时,线程也不会释放锁。
3.2 Lock锁
Lock是一个更强大的同步机制,它的锁样式较多,甚至可允许一定程度的并发操作。synchronized就比较暴力,原本多线程对同一资源只读不写是完全没问题的,但是synchronized的锁不允许这种情况出现,而Lock则可以。
待续·······
4、线程通信
线程的执行虽然是由系统来决定怎么调度,但我们还是有一些权利来影响系统的决策。如何影响就是线程通信。
4.1 传统的线程通信
传统的线程通信是通过Object类提供的wait()、notify()、notifyAll()三个方法。上面提到synchronized有两种使用方法,一种是同步代码块,另一种是同步方法。这两者加锁的对象分别是synchronized括号里的对象和this。我们就调用被锁住的对象的wait()、notify()、notifyAll()三个方法即可实现线程通信。
这三个方法的效果如下
- wait():使占用该锁的线程等待,等待会让该线程放弃对锁的占用,并且等待(也就是阻塞)不是就绪状态,线程在唤醒之前都不会再次占用锁。其它线程调用该锁的notify()方法或者notifyAll()通知唤醒该线程。该方法有两种重载形式:不带参数,线程无线等待;带参数的,有毫秒和毫微秒级别的参数。
- notify():唤醒在这个锁上处于等待状态的一个线程。如果有多个线程,那是选择任意一个线程唤醒。
- nofityAll():唤醒在这个锁上等待的所有线程。
4.2 使用Condition控制线程通信
如果系统不适用synchronized来保证同步,而是用Lock来保证同步,因为系统没有隐式的同步监视器,那我们就不能用传统的方法来控制线程通信。这时候我们就用Condition来控制线程通信。
使用Condition的话,Lock就相当于同步方法或同步方法块,Condition就相当于同步监视器。
Condition实例被绑定在一个Lock对象上,要获得特定的Lock实例的Condition实例,调用Lock对象的newCondition()即可。Condition提供了下面三个方法
- await():相当于wait()方法,等待的线程直到其它的线程调用该Condition的signal()方法或signalAll()方法才能被唤醒。await()也有多个重载形式,和wait()一样。
- signal():和notify()方法一样。
- signalAll():和notifyAll()一样。
4.3 阻塞队列控制线程通信
Java5提供了一个BlockingQueue接口,虽然该接口是Queue的子接口,但它的主要作用并不是作为一个容器,而是一个线程通信的工具。
阻塞队列有这样一个特征:当生产者试着想阻塞队列中放入元素时,如果队列已满,则生产者线程阻塞;当消费者试图从阻塞队列中获取元素时,如果队列为空,则消费者线程阻塞。
放入元素和获取元素分别对应着以下几个方法
- 在队列尾部插入元素:add(E e),offer(E e)和put(E e)。正常情况下,这三个方法效果相同。但队列已满时,这三个方法分别会抛出异常,返回false,阻塞队列。
- 在队列头部取出元素:remove(),poll()和take(),正常情况下,这三个方法效果相同。但队列为空时,这是哪个方法分别会抛出异常,返回false,阻塞队列。
BlockingQueue以及其实现类如下图所示

- ArrayBlockingQueue:基于数组实现的BlockingQueue队列。
- LinkedBlockingQueue:基于链表实现的BlockingQueue队列。
- PriorityBlockingQueue:这并不是个标准的阻塞队列。和PriorityQueue类似,该队列调用remove()、poll()和take()方法来取出元素时,并不是取出队列中存在试驾最长的元素,而是队列中最小的元素。对于大小的判定是根据元素实现的Conparable接口来判断。
- SynchronousQueue:同步队列。该队列的存取操作必须交替执行。
- DelayQueue:他是特殊的BlockingQueue,底层基于PriorityBlockingQueue实现。但是DelayQueue要求集合元素都实现Delay接口(接口里有一个long getDelay()方法),DelayQueue根据集合元素的getDelay()方法的返回值进行排序。
4.4 线程组和未处理的异常
Java可以以组为单位来管理线程,使用ThreadGroup。我们直接对ThreadGroup进行操作,就相当于对属于这个组的所有线程进行相同的操作。
我们创建的线程其实都属于某一个线程组,及时我们没有显式指定。默认情况下,子线程属于父线程的组,这个逻辑和设置后台线程的逻辑差不多。
显式设置线程所属的组只能通过线程的构造函数,所以,线程一旦被创建,那线程所属的组就永远不能被改变。下面是唯一的三个为线程指定线程组的方法。
- Thread(ThreadGroup group, Runnable target):以target的run()方法作为线程执行体创建新线程,属于group线程组。
- Thread(ThreadGroup group, Runnable target, String name):以target的run()方法作为线程执行体创建新线程,属于group线程组,线程名为name。
- Thread(ThreadGroup group, String name):创建新线程,线程名为name,属于group线程组。
我们可以通过getThreadGroup()来获取线程所属的线程组。
线程组有两个构造器,ThreadGroup(String name)和ThreadGroup(ThreadGroup parentGroup, String name)。这第一个构造器很容易理解,第二个构造器是创建一个输入parentGroup的子线程组,子线程组的名字为name。
线程组创建后不允许改名,只能通过getName()获取名字。
线程组有以下几个常用方法
- int activeGroup():返回此线程组中活动线程的数目。
- interrupt():中断该线程中的所有线程。
- isDaemo():判断该线程组是否是后台线程组。
- setDaemon(boolean daemon):把该线程组设置成后台线程组,当后台线程组的最后一个线程执行结束或被销毁后,后台线程自动销毁。
setMaxPriority(int pri):设置线程组的最高优先级。