1. 代码部分
此代码块为recognize_video.py内的代码
# USAGE
# python recognize_video.py --detector face_detection_model \
# --embedding-model openface_nn4.small2.v1.t7 \
# --recognizer output/recognizer.pickle \
# --le output/le.pickle
# v4_v1解决了多线程中的Exception in thread Thread-7:UnboundLocalError:
# local variable 'name' referenced before assignment
# 加载必要的包
from imutils.video import VideoStream
from imutils.video import FPS
import numpy as np
import imutils
import pickle
import time
import cv2
import os
import tkinter as tk
import threading
def recognize_video():
## 创建识别窗口
win_rec = tk.Tk()
win_rec.title('人脸识别')
win_rec.geometry('300x320')
var_name = tk.StringVar()
var_proba = tk.StringVar()
var_ans = tk.StringVar()
## 创建画布用于切换图片
canvas1 = tk.Canvas(win_rec, height = 129, width = 183)
canvas2 = tk.Canvas(win_rec, height = 129, width = 183)
stop = tk.PhotoImage(file = 'stop.gif')
welcome = tk.PhotoImage(file = 'welcome.gif')
canvas1.create_image(0,0, anchor = 'nw', image = stop)
canvas2.create_image(0,0, anchor = 'nw', image = welcome)
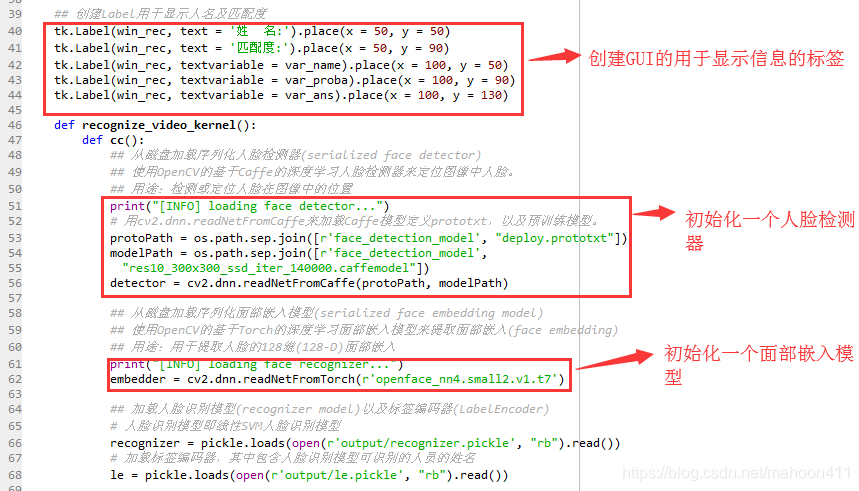
## 创建Label用于显示人名及匹配度
tk.Label(win_rec, text = '姓 名:').place(x = 50, y = 50)
tk.Label(win_rec, text = '匹配度:').place(x = 50, y = 90)
tk.Label(win_rec, textvariable = var_name).place(x = 100, y = 50)
tk.Label(win_rec, textvariable = var_proba).place(x = 100, y = 90)
tk.Label(win_rec, textvariable = var_ans).place(x = 100, y = 130)
tk.Label(win_rec, text = '人脸识别系统v6').place(x=175, y=300)
def recognize_video_kernel():
def cc():
## 从磁盘加载序列化人脸检测器(serialized face detector)
## 使用OpenCV的基于Caffe的深度学习人脸检测器来定位图像中人脸。
## 用途:检测或定位人脸在图像中的位置
print("[INFO] loading face detector...")
# 用cv2.dnn.readNetFromCaffe来加载Caffe模型定义prototxt,以及预训练模型。
protoPath = os.path.sep.join([r'face_detection_model', "deploy.prototxt"])
modelPath = os.path.sep.join([r'face_detection_model',
"res10_300x300_ssd_iter_140000.caffemodel"])
detector = cv2.dnn.readNetFromCaffe(protoPath, modelPath)
## 从磁盘加载序列化面部嵌入模型(serialized face embedding model)
## 使用OpenCV的基于Torch的深度学习面部嵌入模型来提取面部嵌入(face embedding)
## 用途:用于提取人脸的128维(128-D)面部嵌入
print("[INFO] loading face recognizer...")
embedder = cv2.dnn.readNetFromTorch(r'openface_nn4.small2.v1.t7')
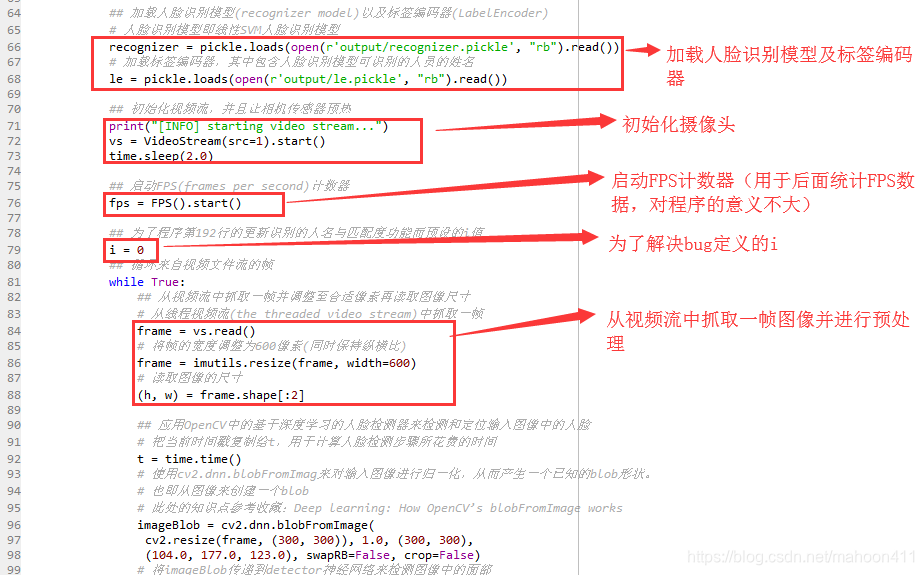
## 加载人脸识别模型(recognizer model)以及标签编码器(LabelEncoder)
# 人脸识别模型即线性SVM人脸识别模型
recognizer = pickle.loads(open(r'output/recognizer.pickle', "rb").read())
# 加载标签编码器,其中包含人脸识别模型可识别的人员的姓名
le = pickle.loads(open(r'output/le.pickle', "rb").read())
## 初始化视频流,并且让相机传感器预热
print("[INFO] starting video stream...")
vs = VideoStream(src=1).start()
time.sleep(2.0)
## 启动FPS(frames per second)计数器
fps = FPS().start()
## 为了程序第192行的更新识别的人名与匹配度功能而预设的i值
i = 0
## 循环来自视频文件流的帧
while True:
## 从视频流中抓取一帧并调整至合适像素再读取图像尺寸
# 从线程视频流(the threaded video stream)中抓取一帧
frame = vs.read()
# 将帧的宽度调整为600像素(同时保持纵横比)
frame = imutils.resize(frame, width=600)
# 读取图像的尺寸
(h, w) = frame.shape[:2]
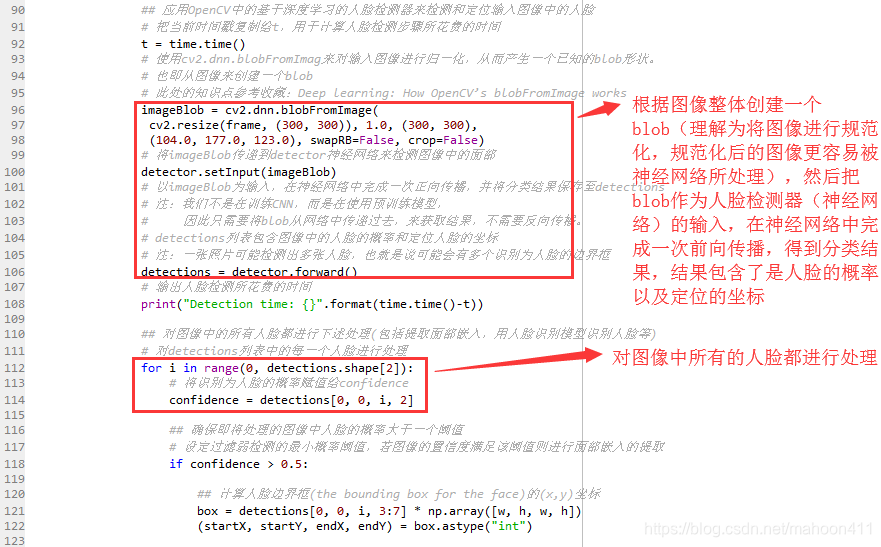
## 应用OpenCV中的基于深度学习的人脸检测器来检测和定位输入图像中的人脸
# 把当前时间戳复制给t,用于计算人脸检测步骤所花费的时间
t = time.time()
# 使用cv2.dnn.blobFromImag来对输入图像进行归一化,从而产生一个已知的blob形状。
# 也即从图像来创建一个blob
# 此处的知识点参考收藏:Deep learning: How OpenCV’s blobFromImage works
imageBlob = cv2.dnn.blobFromImage(
cv2.resize(frame, (300, 300)), 1.0, (300, 300),
(104.0, 177.0, 123.0), swapRB=False, crop=False)
# 将imageBlob传递到detector神经网络来检测图像中的面部
detector.setInput(imageBlob)
# 以imageBlob为输入,在神经网络中完成一次正向传播,并将分类结果保存至detections
# 注:我们不是在训练DNN,而是在使用预训练模型,
# 因此只需要将blob从网络中传递过去,来获取结果,不需要反向传播。
# detections列表包含图像中的人脸的概率和定位人脸的坐标
# 注:一张照片可能检测出多张人脸,也就是说可能会有多个识别为人脸的边界框
detections = detector.forward()
# 输出人脸检测所花费的时间
print("Detection time: {}".format(time.time()-t))
## 对图像中的所有人脸都进行下述处理(包括提取面部嵌入,用人脸识别模型识别人脸等)
# 对detections列表中的每一个人脸进行处理
for i in range(0, detections.shape[2]):
# 将识别为人脸的概率赋值给confidence
confidence = detections[0, 0, i, 2]
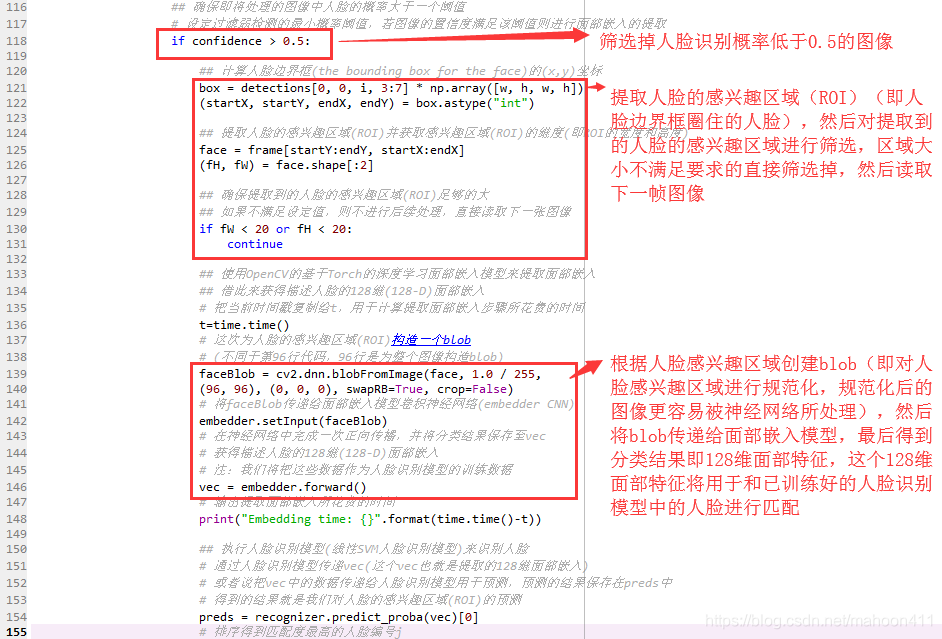
## 确保即将处理的图像中人脸的概率大于一个阈值
# 设定过滤弱检测的最小概率阈值,若图像的置信度满足该阈值则进行面部嵌入的提取
if confidence > 0.5:
## 计算人脸边界框(the bounding box for the face)的(x,y)坐标
box = detections[0, 0, i, 3:7] * np.array([w, h, w, h])
(startX, startY, endX, endY) = box.astype("int")
## 提取人脸的感兴趣区域(ROI)并获取感兴趣区域(ROI)的维度(即ROI的宽度和高度)
face = frame[startY:endY, startX:endX]
(fH, fW) = face.shape[:2]
## 确保提取到的人脸的感兴趣区域(ROI)足够的大
## 如果不满足设定值,则不进行后续处理,直接读取下一张图像
if fW < 20 or fH < 20:
continue
## 使用OpenCV的基于Torch的深度学习面部嵌入模型来提取面部嵌入
## 借此来获得描述人脸的128维(128-D)面部嵌入
# 把当前时间戳复制给t,用于计算提取面部嵌入步骤所花费的时间
t=time.time()
# 这次为人脸的感兴趣区域(ROI)构造一个blob
# (不同于第96行代码,96行是为整个图像构造blob)
faceBlob = cv2.dnn.blobFromImage(face, 1.0 / 255,
(96, 96), (0, 0, 0), swapRB=True, crop=False)
# 将faceBlob传递给面部嵌入模型卷积神经网络(embedder CNN)
embedder.setInput(faceBlob)
# 在神经网络中完成一次正向传播,并将分类结果保存至vec
# 获得描述人脸的128维(128-D)面部嵌入
# 注:我们将把这些数据作为人脸识别模型的训练数据
vec = embedder.forward()
# 输出提取面部嵌入所花费的时间
print("Embedding time: {}".format(time.time()-t))
## 执行人脸识别模型(线性SVM人脸识别模型)来识别人脸
# 通过人脸识别模型传递vec(这个vec也就是提取的128维面部嵌入)
# 或者说把vec中的数据传递给人脸识别模型用于匹配,匹配的结果保存在preds中
# 得到的结果就是我们对人脸的感兴趣区域(ROI)的匹配结果
preds = recognizer.predict_proba(vec)[0]
# 排序得到匹配度最高的人脸编号j
j = np.argmax(preds)
# 读取被识别人j的匹配度
proba = preds[j]
# 查询标签编码器,得到被识别人j的姓名,并将其赋值给name
name = le.classes_[j]
## 在人脸周围绘制一个边界框并且显示人名及其匹配度
# 定义显示的文本信息,包括人名及其对应的匹配度
text = "{}: {:.2f}%".format(name, proba * 100)
y = startY - 10 if startY - 10 > 10 else startY + 10
# 在人脸周围绘制边界框
cv2.rectangle(frame, (startX, startY), (endX, endY),
(0, 0, 255), 2)
# 在边界框上显示人名和相应的匹配度
cv2.putText(frame, text, (startX, y),
cv2.FONT_HERSHEY_SIMPLEX, 0.45, (0, 0, 255), 2)
print(text)
## 更新fps计数器
fps.update()
# 显示用于输出视频的frame
cv2.imshow("Frame", frame)
key = cv2.waitKey(1) & 0xFF
# 如果按下'q'键,则退出while循环
if key == ord("q"):
break
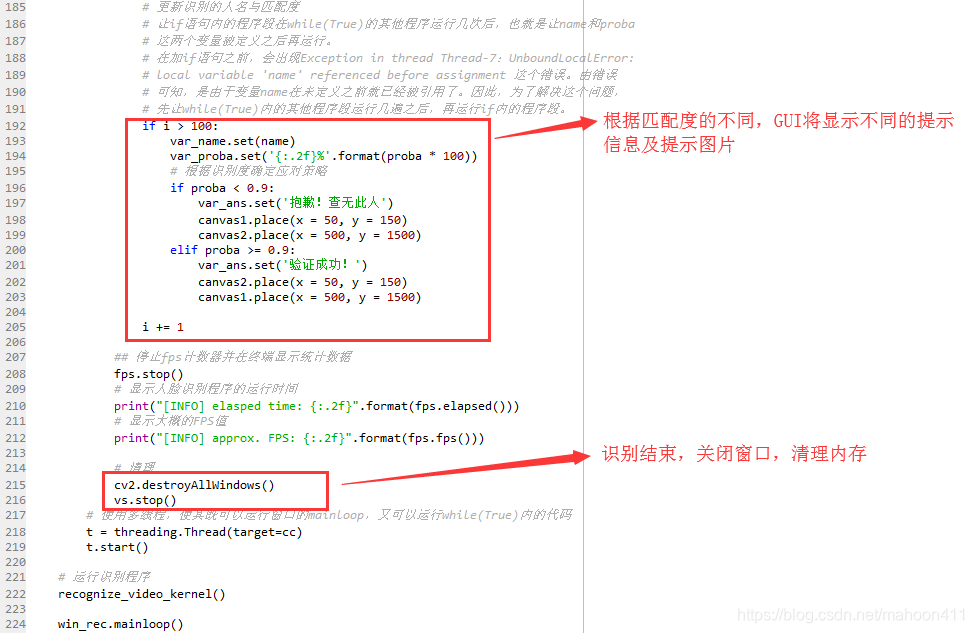
# 更新识别的人名与匹配度
# 让if语句内的程序段在while(True)的其他程序运行几次后,也就是让name和proba
# 这两个变量被定义之后再运行。
# 在加if语句之前,会出现Exception in thread Thread-7:UnboundLocalError:
# local variable 'name' referenced before assignment 这个错误。由错误
# 可知,是由于变量name在未定义之前就已经被引用了。因此,为了解决这个问题,
# 先让while(True)内的其他程序段运行几遍之后,再运行if内的程序段。
if i > 100:
var_name.set(name)
var_proba.set('{:.2f}%'.format(proba * 100))
# 根据识别度确定应对策略
if proba < 0.70:
var_ans.set('抱歉!查无此人')
canvas1.place(x = 50, y = 150)
canvas2.place(x = 500, y = 1500)
elif proba >= 0.70:
var_ans.set('验证成功!')
canvas2.place(x = 50, y = 150)
canvas1.place(x = 500, y = 1500)
i += 1
## 停止fps计数器并在终端显示统计数据
fps.stop()
# 显示人脸识别程序的运行时间
print("[INFO] elasped time: {:.2f}".format(fps.elapsed()))
# 显示大概的FPS值
print("[INFO] approx. FPS: {:.2f}".format(fps.fps()))
# 清理
cv2.destroyAllWindows()
vs.stop()
# 使用多线程,使其既可以运行窗口的mainloop,又可以运行while(True)内的代码
t = threading.Thread(target=cc)
t.start()
# 运行识别程序
recognize_video_kernel()
win_rec.mainloop()
# 运行此py文件时,if内语句才会运行。其他文件调用此py时,if内语句不会被执行。
if __name__ == '__main__':
recognize_video()
2. 函数结构说明
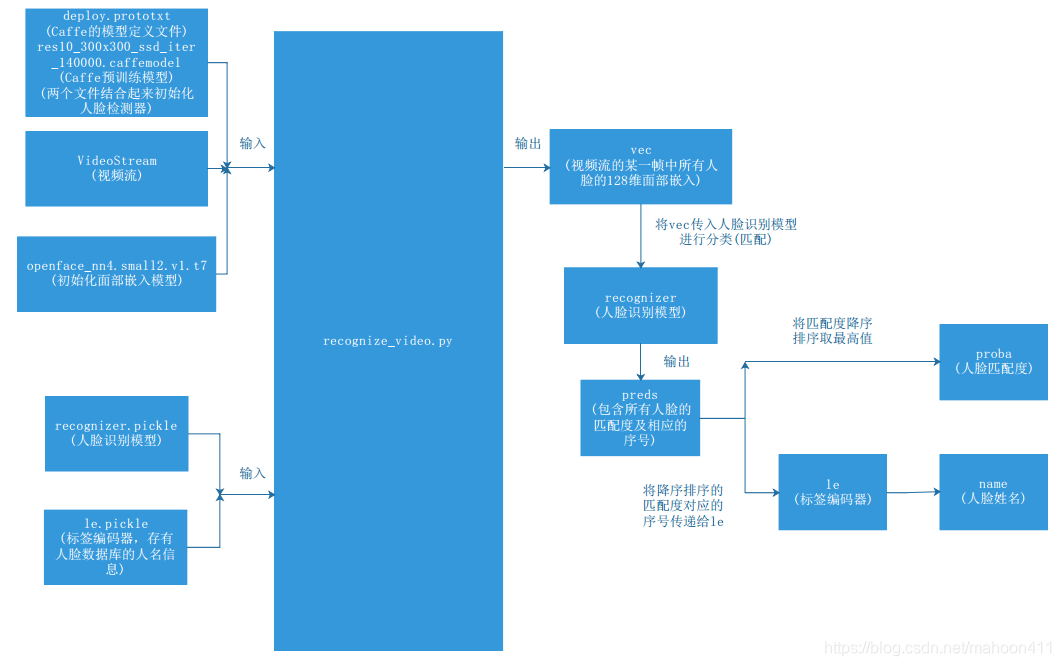
3. 程序流程图
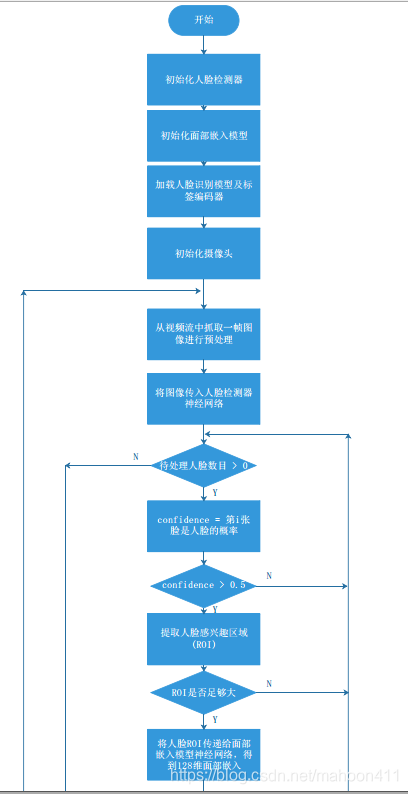
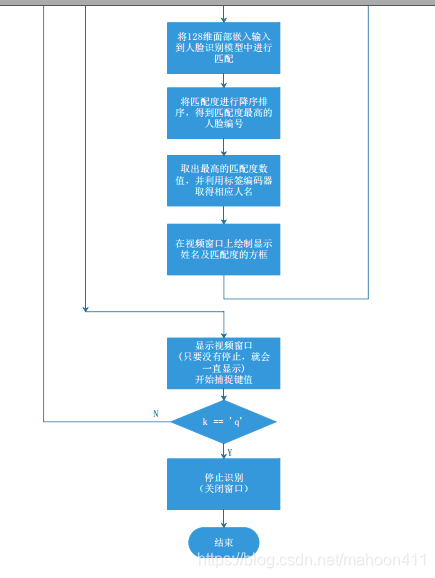
4. 函数图解
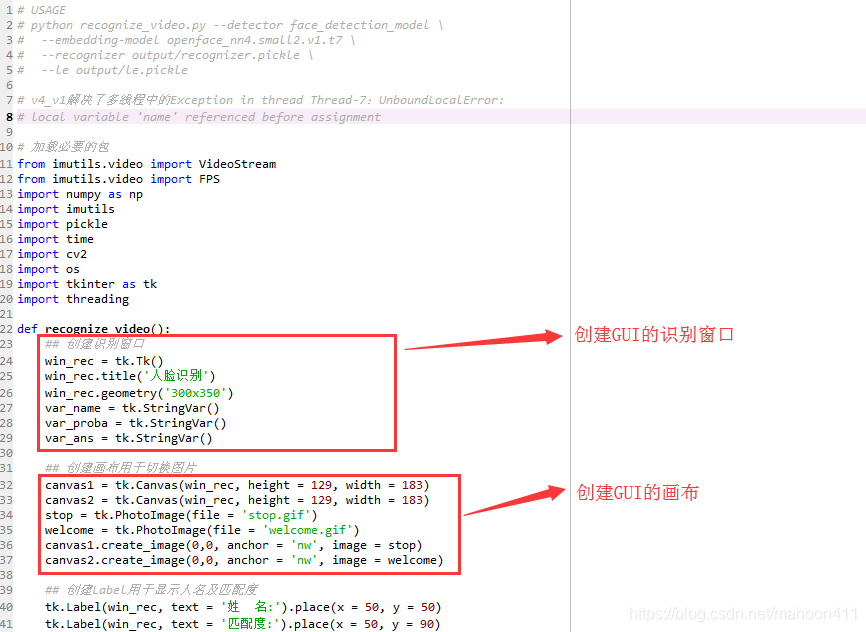

5. 使用说明
本函数需搭配视频流人脸识别系统一起使用。
视频流人脸识别系统的系统函数见此博客:一、视频流人脸识别系统的系统函数的构建(Python)
文中用到的deploy.prototxt、res10_300x300_ssd_iter_140000.caffemodel、openface_nn4.small2.v1.t7文件在此处下载:人脸识别集成包