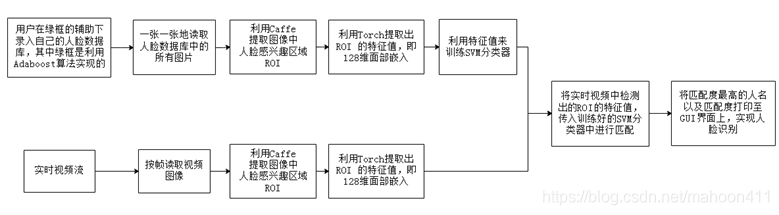
1. 系统流程图
2. 关键函数说明
注:详细的代码以及程序流程图请参见博客:
一、视频流人脸识别系统的系统函数的构建
二、构建人脸识别数据库
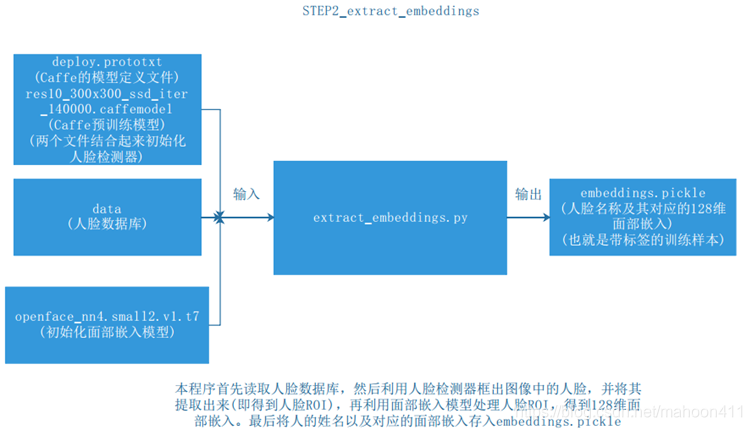
三、提取人脸的面部嵌入
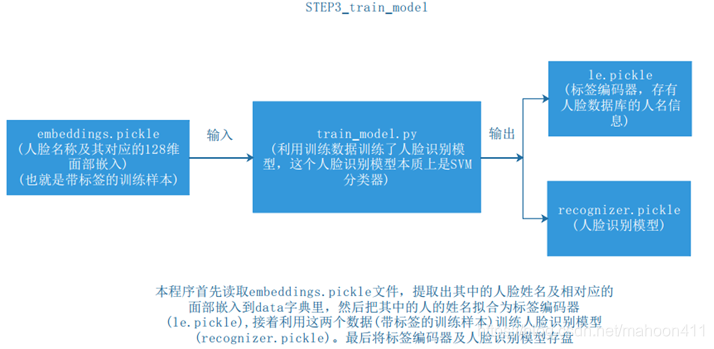
四、训练SVM分类器
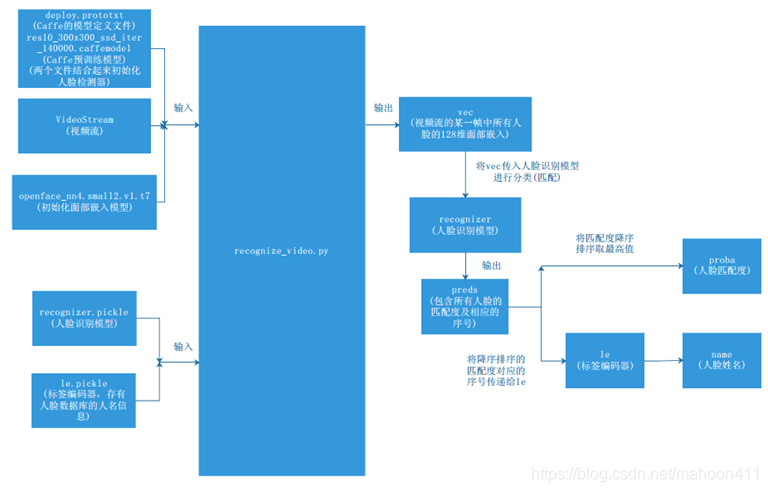
五、视频流人脸识别的实现
3. 面试问题
3.1 请简单介绍一下你的毕业设计项目
我的毕业设计题目是使用深度学习的人脸识别系统实现。程序的编程语言使用的是Python。
首先我讲解一下我的系统的使用方法。第一次使用本系统的人,需要先通过GUI界面点击“信息登记”录入若干张人脸数据,用于人脸数据库的建立。若之前已经录入过人脸数据库的则可直接点击“人员识别”进行人脸识别。识别过程中,GUI界面会出现识别者的姓名以及相应的匹配度,匹配度高于设定值则显示验证成功!匹配度低于设定值则显示查无此人!
3.2 GUI界面是通过什么制作的呢?
我是通过Python的tkinter库制作的。
3.3 可以简要地讲解一下人脸数据库是如何建立的吗?
首先,用户点击“信息登记”按钮,系统会提示输入姓名以及证件,完成录入后,将跳转到视频页面进行人脸录入。我利用AdaBoost算法来实现对视频流中的人脸的检测,并用绿框框出人脸,在绿色方框的协助下,按下键盘‘k’,调整人脸角度、改变光线强弱等,将每一幅图像录入到人脸数据库。完成人脸录入后,按下键盘‘q’,退出视频窗口。注意的是,在录入人脸数据库时,视频中只能出现一个人的人脸。
3.4 为什么只能出现一个人的人脸,如果有多个人同时出现在视频中会出现什么情况?
当有多个人出现在视频中,并且用户将这张图片录入到人脸数据库后,会出现意想不到的后果。系统在后续提取人脸数据库中这位用户的这张图片时,将会把这张图片中最可能为人脸的图片认定为用户的人脸,但这张人脸可能并不是用户自己的。这将使后面的人脸识别的成功的概率降低。
也正因为这个原因,我在用户录入人脸数据库时设计了人脸检测绿框,用户应该在屏幕中有且仅有一个绿框,且这个绿框框住的是自己的人脸的时候,按下“k”键,完成一张人脸图片的录入。
3.5 人脸识别的步骤是怎样的?请简单介绍一下。
首先要提取人脸数据库中所有人的所有照片的128维面部嵌入,再把这128维面部嵌入和它对应的人的姓名连接起来,形成一个后缀名为.pickle的文件。用这个文件来训练SVM分类器,训练后得到的结果是存有人名的标签编码器和人脸识别模型。这时就可以利用这两个文件进行人脸识别了。
读取实时视频流中的每帧图像,然后提取图像中人脸的128维面部嵌入,然后将128维面部嵌入传入训练好的SVM分类器中进行匹配,输出的结果就是实时图像中的人脸和人脸数据库中的所有人脸的匹配度及其对应的人名。将匹配度最高的人名和对应的匹配度打印至GUI上。在实时识别视频中用红框框出检测到的人脸,并在红框边上写上识别人姓名及相应匹配度,这样就实现了人脸识别。
3.6 你说的128维面部嵌入是什么?是怎么得到的?
这个128维面部嵌入也就是一张人脸的128维特征值,它可以用来代表这张人脸。
首先利用Caffe提取出人脸数据库中图像的人脸感兴趣区域ROI。然后通过Torch提取出ROI的128维面部嵌入。
3.7 SVM分类器是什么?你怎么使用SVM分类器?
SVM就是支持向量机。SVM分类器是一套基于统计学提出的监督学习方法,SVM分类器通过找到超平面来把数据分类,并使数据到平面的距离最大。在训练部分,利用提取到的128维面部嵌入来训练SVM分类器,使之具有学习能力。在识别部分,SVM分类器将待检测人脸的128维面部嵌入与数据库中人脸的128维面部嵌入进行对比判断,从而验证身份。
3.8 实时视频中的检测人脸的红框是怎么实现的?
运用Caffe检测出实时视频流中每一帧图像的ROI并用红色方框框出。
3.9 为什么构建人脸数据库时用Haar特征分类器,实时视频流又用Caffe呢?
因为我想尝试利用多种方法来实现对人脸的检测。
3.10 你所制作的系统可以优化吗?优化的点在哪?
对于SVM分类器的核函数选取问题我进行过实验优化。实验测试中,我分别选用两种核函数——“径向基核函数”、“线性核函数”进行测试。经过测试后,线性核函数匹配精度更高,故而本系统的设计采用线性核函数。
3.11 你的系统有什么缺点吗?
我的系统每次点击人员识别按钮时都需要重新训练一次模型。而且一个人如果要识别成功的话,大概需要录入四十张左右的有效图片。