k-means算法是无监督学习算法(非监督学习算法)。
1.聚类
聚类分析是没有划分类别的情况下,根据样本相似度进行样本分组的一种方法分监督学习算法。聚类的输入是一组未被标记的样本,聚类根据自身的距离或者相似度划分为若干组,划分的原则是组内距离最小化,而组间距离最大化。
2.k-means
k-means算法是一种简单的迭代型聚类算法,采用距离作为相似性指标,从而发现给定数据集中k个类,且每个类的中心是根据类中所有值的均值得到,每个类用聚类中心来描述。对于给定的一个包含n个d维数据点的数据集X以及分得的类别k,选取欧式距离作为相似度指标,聚类目标是使得各类的距离平方和最小,即最小化:
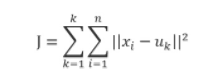
结合最小二乘法和拉格朗日原理,聚类中心为对应类别的平均值,同时为了使得算法收敛,在迭代过程中,应使最终的聚类中心尽可能的不变。
3.算法的原理(算法的流程)
k-means算法是一个反复迭代的过程,算法分为四个步骤:
1)选取数据空间中的k个对象作为初始中心,每个对象代表一个聚类中心;
2)对样本中的数据对象,根据它们与这些聚类中心的欧式距离,按距离最近的准则将它们分到距离它们最近的聚类中心所对应的类;
3)更新聚类中心:将每个类别中所有对象所对应的均值作为该类别的聚类中心,计算目标函数的值;
4)判断聚类中心和目标函数的值是否发生改变,若不变,则输出结果,若改变,则返回2)
4.k如何选择
不同的聚类方法有不同的评价指标,这里我们不深入探讨。
1)肘部法则-Elbow method
k-means是以最小化样本与质点平方误差作为目标函数,将每个簇的质点与簇内样本点的平方距离误差和称为畸变程度(distortions),那么,对于一个簇,它的畸变程度越低,代表簇内成员越紧密,畸变程度越高,代表簇内结构越松散。 畸变程度会随着类别的增加而降低,但对于有一定区分度的数据,在达到某个临界点时畸变程度会得到极大改善,之后缓慢下降,这个临界点就可以考虑为聚类性能较好的点。 基于这个指标,我们可以重复训练多个k-means模型,选取不同的k值,来得到相对合适的聚类类别。

横轴:k值,聚类数
纵轴:平均畸变程度
2)轮廓系数-Silhouette Coefficient
对于一个聚类任务,我们希望得到的簇中,簇内尽量紧密,簇间尽量远离,轮廓系数便是类的密集与分散程度的评价指标,公式表达如下(某个样本点Xi的轮廓系数):
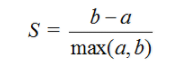
其中,a是Xi与同簇的其他样本的平均距离,称为凝聚度,b是Xi与最近簇中所有样本的平均距离,称为分离度。而最近簇的定义是
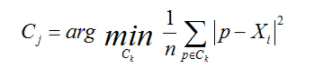
其中p是某个簇Ck中的样本。事实上,简单点讲,就是用Xi到某个簇所有样本平均距离作为衡量该点到该簇的距离后,选择离Xi最近的一个簇作为最近簇。
求出所有样本的轮廓系数后再求平均值就得到了平均轮廓系数。平均轮廓系数的取值范围为[-1,1],且簇内样本的距离越近,簇间样本距离越远,平均轮廓系数越大,聚类效果越好。那么,很自然地,平均轮廓系数最大的k便是最佳聚类数。

可以看到,轮廓系数最大的k值是2,这表示我们的最佳聚类数为2。但是,值得注意的是,从k和SSE的手肘图可以看出,当k取2时,SSE还非常大,所以这是一个不太合理的聚类数,我们退而求其次,考虑轮廓系数第二大的k值4,这时候SSE已经处于一个较低的水平,因此最佳聚类系数应该取4而不是2。
但是,讲道理,k=2时轮廓系数最大,聚类效果应该非常好,那为什么SSE会这么大呢?在我看来,原因在于轮廓系数考虑了分离度b,也就是样本与最近簇中所有样本的平均距离。为什么这么说,因为从定义上看,轮廓系数大,不一定是凝聚度a(样本与同簇的其他样本的平均距离)小,而可能是b和a都很大的情况下b相对a大得多,这么一来,a是有可能取得比较大的。a一大,样本与同簇的其他样本的平均距离就大,簇的紧凑程度就弱,那么簇内样本离质心的距离也大,从而导致SSE较大。所以,虽然轮廓系数引入了分离度b而限制了聚类划分的程度,但是同样会引来最优结果的SSE比较大的问题,这一点也是值得注意的。
3)Calinski-Harabasz准则

5.初始点选择
1)kmeans++方法
1、从输入的数据点集合中随机选择一个点作为第一个聚类中心
2、对于数据集中的每一个点x,计算它与最近聚类中心(指已选择的聚类中心)的距离D(x)
3、选择一个新的数据点作为新的聚类中心,选择的原则是:D(x)较大的点,被选取作为聚类中心的概率较大
4、重复2和3直到k个聚类中心被选出来
5、利用这k个初始的聚类中心来运行标准的k-means算法
从上面的算法描述上可以看到,算法的关键是第3步,如何将D(x)反映到点被选择的概率上,一种算法如下:
1、先从我们的数据库随机挑个随机点当“种子点”
2、对于每个点,我们都计算其和最近的一个“种子点”的距离D(x)并保存在一个数组里,然后把这些距离加起来得到Sum(D(x))。
3、然后,再取一个随机值,用权重的方式来取计算下一个“种子点”。这个算法的实现是,先取一个能落在Sum(D(x))中的随机值Random,然后用Random -= D(x),直到其<=0,此时的点就是下一个“种子点”。
4、重复2和3直到k个聚类中心被选出来
5、利用这k个初始的聚类中心来运行标准的k-means算法
2)层次聚类或者Cannopy算法进行初始聚类
又初始聚类得到的k个类别,然后从k个类别中分别随机选取k个点,作为kmeans的初始聚类中心点。
6.优缺点
1)优点
1,算法快速、简单
2,容易解释
3,聚类效果中上
4,适用于高维数据
2)缺点
1,对离群点敏感,对噪声点和孤立点很敏感(通过k-centers算法可以解决)
2,k-means算法中聚类个数k的初始化复杂,k不好选择(要预先确定)
3,初始聚类中心的选择不同,可能导致完全不同的聚类结果
4,kmeans不能处理非球形簇的聚类问题
补充说明:有机会再深入研究。
聚类的性能评估:
Adjusted Mutual Information(AMI)(调整互信息)
Rand Index
Adjust Rand Index
https://blog.csdn.net/darkrabbit/article/details/80378597
https://github.com/AugustMe/Machine-Learning
参考与引用:
https://www.cnblogs.com/dudumiaomiao/p/5839905.html
https://blog.csdn.net/niuniu0243111006/article/details/89409262
https://www.cnblogs.com/xingnie/articles/10334412.html
https://www.cnblogs.com/niniya/p/8784947.html
https://blog.csdn.net/sxllllwd/article/details/82151996
仅用来个人学习和分享,如若侵权,留言立删。
尊重他人知识产权,不做拿来主义者!
喜欢的可以关注我哦QAQ,
你的关注和喜欢就是我write博文的动力