机器学习算法原理与实践(五)、GMM与K-means的那些事
转载请注明出处【CSDN】http://blog.csdn.net/llp1992
GMM算法
GMM ,Gaussian Mixture Model,顾名思义,就是说该算法由 多个高斯模型线性叠加 混合而成。每个高斯模型我们称之为 component 。GMM算法描述的是数据的本身存在的一种分布,如果component足够多的话,GMM可以逼近任意一种概率密度分布,但是此时的GMM模型就太过复杂了。
GMM 与 K-means
GMM算法跟K-means算法很像,它也是被用来聚类。在GMM中,component的个数我们定义为 K ,这跟K-means中的K一样,需要另外的方式去确定K值得大小。
在K-means中,每个聚类中心的初始化都会影响聚类效果,同样的,GMM算法对每个component的质心的初始化也很敏感。
解决方案
在K-means中,二分K-means算法就是为了弱化初始点对聚类效果的影响而提出来的,具体思路如下:
首先将所有点作为一个簇,然后将该簇一分为二。之后选择能最大程度降低聚类代价函数(也就是误差平方和)的簇划分为两个簇。以此进行下去,直到簇的数目等于用户给定的数目k为止
伪代码如下:
将所有数据点看成一个簇
当簇数目小于k时
对每一个簇
计算总误差
在给定的簇上面进行k-均值聚类(k=2)
计算将该簇一分为二后的总误差
选择使得误差最小的那个簇进行划分操作
同样的,GMM也可以有类似的二分GMM算法,关于二分K-means算法的具体流程以及代码请参考博客:
GMM 模型
GMM由K个Gaussian分布线性叠加而成,先看看GMM的概率密度函数:
该函数可以这么理解,假设我们有一个数据集,然后我们现在用GMM模型来描述这个数据集的分布。在已知数据集由component k 描述的情况下,数据集的概率密度函数为: p(x|k)p(x|k) 。
当然,总共有 K 个component,每个component 对生成数据集的贡献为 p(k)p(k) ,或者说数据集由component k生成的概率为 p(k)p(k),由 component k 生成数据集,其概率密度函数为 p(k)p(x|k)p(k)p(x|k) 。将所有的component加起来就得到了GMM的概率密度函数。有点绕口,大致懂就好。
如果我们要从 GMM 的分布中随机地取一个点的话,实际上可以分为两步:首先随机地在这 K个Gaussian Component 之中选一个,每个 Component 被选中的概率实际上就是它的系数 pi(k) ,选中了 Component 之后,再单独地考虑从这个 Component 的分布中选取一个点就可以了──这里已经回到了普通的 Gaussian 分布,转化为了已知的问题。
GMM 聚类
假设现在有一个大数据集,为什么要大数据集?待会会说。只要我们能用GMM算法来描述这个“客观存在”的数据集,那么GMM的K个component也就是对应的K个cluster了。根据数据来推算概率密度通常被称作 density estimation ,特别地,当我们在已知(或假定)了概率密度函数的形式,而要估计其中的参数的过程被称作“参数估计”。
每个component k 都是一个Gaussian分布,其均值设定为 μkμk ,方差设定为 ΣkΣk ,这个component的影响因子设定为 πkπk。但是 我们一开始并不知道每个component k 的这几个参数的具体值,聚类误差函数中除了聚类后的label y之外,还有μkμk 、ΣkΣk 和 πkπk这3个我们不知道的隐含变量,这时问题就得用EM算法来迭代求解。
参数与似然函数
现在假设我们有 N 个数据点,并假设它们服从某个分布(记作 p(x)p(x) ),现在要确定里面的一些参数的值,例如,在 GMM 中,我们就需要确定 影响因子 π(k)π(k)、各类均值 μkμk 和 各类协方差 ΣkΣk 这些参数。
我们的想法是,找到这样一组参数,它所确定的概率分布生成这些给定的数据点的概率最大,而这个概率实际上就等于ΠNi=1p(xi)Πi=1Np(xi),我们把这个乘积称作似然函数 (Likelihood Function)。通常单个点的概率都很小,许多很小的数字相乘起来在计算机里很容易造成浮点数下溢,因此我们通常会对其取对数,把乘积变成加和 ∑Ni=1logp(xi)∑i=1Nlogp(xi) ,具体函数如下:
接下来我们只要将这个函数最大化(通常的做法是求导并令导数等于零,然后解方程),亦即找到这样一组参数值,它让似然函数取得最大值,我们就认为这是最合适的参数,这样就完成了参数估计的过程。
由于在对数函数里面又有加和,我们没法直接用求导解方程的办法直接求得最大值。为了解决这个问题,我们采取之前从 GMM 中随机选点的办法:分成两步,E步和M步,这就是用EM算法求解GMM的过程。其实这跟K-means的求解思想很像,或者说,K-means算法的求解中就是EM算法的精髓。
算法流程
1.估计数据由每个 Component 生成的概率(并不是每个 Component 被选中的概率):对于每个数据 来说,它由第 个 Component 生成的概率为:
其中 N(xi|μk,Σk)N(xi|μk,Σk) 就是后验概率
2.通过极大似然估计可以通过求到令参数=0得到参数 μkμk, ΣkΣk的值
其中,Nk=∑Ni=1γ(i,k)Nk=∑i=1Nγ(i,k) ,故 πkπk 可估计为 Nk/NNk/N
3.重复迭代前面两步,直到似然函数的值收敛为止。
Matlab 实现
GMM函数,来自 pluskid
function varargout = gmm(X, K_or_centroids)
% ============================================================
% Expectation-Maximization iteration implementation of
% Gaussian Mixture Model.
%
% PX = GMM(X, K_OR_CENTROIDS)
% [PX MODEL] = GMM(X, K_OR_CENTROIDS)
%
% - X: N-by-D data matrix.
% - K_OR_CENTROIDS: either K indicating the number of
% components or a K-by-D matrix indicating the
% choosing of the initial K centroids.
%
% - PX: N-by-K matrix indicating the probability of each
% component generating each point.
% - MODEL: a structure containing the parameters for a GMM:
% MODEL.Miu: a K-by-D matrix.
% MODEL.Sigma: a D-by-D-by-K matrix.
% MODEL.Pi: a 1-by-K vector.
% ============================================================
threshold = 1e-15;
[N, D] = size(X);
% isscalar 判断是否为标量
if isscalar(K_or_centroids)
K = K_or_centroids;
% randomly pick centroids
rndp = randperm(N);
centroids = X(rndp(1:K), :);
else % 矩阵,给出每一类的初始化
K = size(K_or_centroids, 1);
centroids = K_or_centroids;
end
% initial values
[pMiu pPi pSigma] = init_params();
Lprev = -inf;
while true
%% Estiamtion Step
Px = calc_prob();
% new value for pGamma
pGamma = Px .* repmat(pPi, N, 1);
pGamma = pGamma ./ repmat(sum(pGamma, 2), 1, K);
%% Maximization Step
% new value for parameters of each Component
Nk = sum(pGamma, 1);
pMiu = diag(1./Nk) * pGamma' * X;
pPi = Nk/N;
for kk = 1:K
Xshift = X-repmat(pMiu(kk, :), N, 1);
pSigma(:, :, kk) = (Xshift' * (diag(pGamma(:, kk)) * Xshift)) / Nk(kk);
end
%% check for convergence
L = sum(log(Px*pPi'));
if L-Lprev < threshold
break;
end
Lprev = L;
end
% 输出参数判定
if nargout == 1
varargout = {Px};
else
model = [];
model.Miu = pMiu;
model.Sigma = pSigma;
model.Pi = pPi;
varargout = {Px, model};
end
function [pMiu pPi pSigma] = init_params()
pMiu = centroids; % 均值,也就是K类的中心
pPi = zeros(1, K); % 概率
pSigma = zeros(D, D, K); %协方差矩阵,每个都是 D*D
% hard assign x to each centroids
% (X - pMiu)^2 = X^2 + pMiu^2 - 2*X*pMiu
distmat = repmat(sum(X.*X, 2), 1, K) + repmat(sum(pMiu.*pMiu, 2)', N, 1) - 2*X*pMiu';
[dummy labels] = min(distmat, [], 2);
for k=1:K %初始化参数
Xk = X(labels == k, :);
pPi(k) = size(Xk, 1)/N;
pSigma(:, :, k) = cov(Xk);
end
end
% 计算概率
function Px = calc_prob()
Px = zeros(N, K);
for k = 1:K
Xshift = X-repmat(pMiu(k, :), N, 1);
inv_pSigma = inv(pSigma(:, :, k)+diag(repmat(threshold,1,size(pSigma(:, :, k),1)))); % 方差矩阵求逆
tmp = sum((Xshift*inv_pSigma) .* Xshift, 2);
coef = (2*pi)^(-D/2) * sqrt(det(inv_pSigma)); % det 求方差矩阵的行列式
Px(:, k) = coef * exp(-0.5*tmp);
end
end
end- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
注意这句代码
coef = (2*pi)^(-D/2) * sqrt(det(inv_pSigma)); % det 求方差矩阵的行列式 - 1
乍看之下好像跟我们的后验概率公式很不符合啊!后验概率公式如下:
代码中的实现是 乘以协方差矩阵的逆矩阵的行列式的开根号后的值,根据线性代数的知识可以得到:|A−1|=1|A||A−1|=1|A| , 故代码没错。
测试代码
clear all
clc
data = load('testSet.txt');
[PX,Model] = GMM(data,4);
[~,index] = max(PX');
cent = Model.Miu;
figure
I = find(index == 1);
scatter(data(I,1),data(I,2))
hold on
scatter(cent(1,1),cent(1,2),150,'filled')
hold on
I = find(index == 2);
scatter(data(I,1),data(I,2))
hold on
scatter(cent(2,1),cent(2,2),150,'filled')
hold on
I = find(index == 3);
scatter(data(I,1),data(I,2))
hold on
scatter(cent(3,1),cent(3,2),150,'filled')
hold on
I = find(index == 4);
scatter(data(I,1),data(I,2))
hold on
scatter(cent(4,1),cent(4,2),150,'filled')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
效果如下
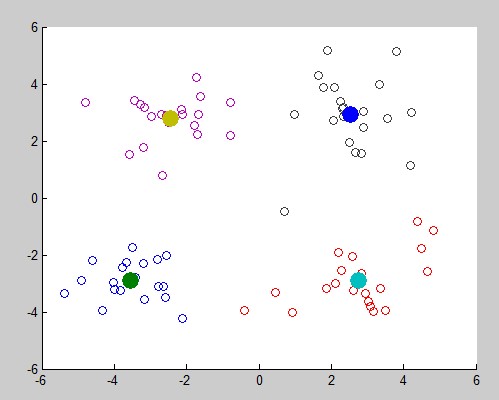
采用同样的数据集: GMM聚类效果如下:
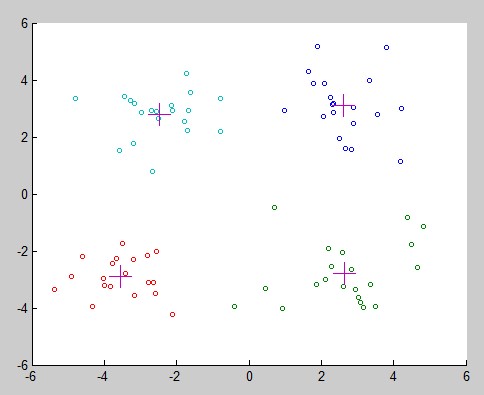
K-means效果如下:
Python版本代码
# -*- coding: utf-8 -*-
'''
Description :GMM in Python
Author : LiuLongpo
Time : 2015年7月26日16:54:48
Source :From pluskid
'''
import sys;
sys.path.append("E:\Python\MachineLearning\PythonTools")
import PythonUtils as pu
import matplotlib.pyplot as plt
import numpy as np
'矩阵的逆矩阵需要的库'
from numpy.linalg import *
def gmm(X,K):
threshold = 1e-15
N,D = np.shape(X)
randV = pu.randIntList(1,N,K)
centroids = X[randV]
pMiu,pPi,pSigma = inti_params(centroids,K,X,N,D);
Lprev = -np.inf
while True:
'Estiamtion Step'
Px = calc_prop(X,N,K,pMiu,pSigma,threshold,D)
pGamma = Px * np.tile(pPi,(N,1))
pGamma = pGamma / np.tile((np.sum(pGamma,axis=1)),(K,1)).T
'Maximization Step'
Nk = np.sum(pGamma,axis=0)
pMiu = np.dot(np.dot(np.diag(1 / Nk),pGamma.T),X)
pPi = Nk / N
for kk in range(K):
Xshift = X - np.tile(pMiu[kk],(N,1))
pSigma[:,:,kk] = (np.dot(np.dot(Xshift.T,np.diag(pGamma[:,kk])),Xshift)) / Nk[kk]
'check for convergence'
L = np.sum(np.log(np.dot(Px,pPi.T)))
if L-Lprev<threshold:
break
Lprev = L
return Px
def inti_params(centroids,K,X,N,D):
pMiu = centroids
pPi = np.zeros((1,K))
pSigma = np.zeros((D,D,K))
distmat = np.tile(np.sum(X * X,axis=1),(K,1)).T \
+ np.tile(np.sum(pMiu * pMiu,axis = 1).T,(N,1)) \
- 2 * np.dot(X,pMiu.T)
labels = np.argmin(distmat,axis=1)
for k in range(K):
Xk = X[labels==k]
pPi[0][k] = float(np.shape(Xk)[0]) / N # 样本数除以 N 得到概率
pSigma[:,:,k] = np.cov(Xk.T)
return pMiu,pPi,pSigma
'计算概率'
def calc_prop(X,N,K,pMiu,pSigma,threshold,D):
Px = np.zeros((N,K))
for k in range(K):
Xshift = X - np.tile(pMiu[k],(N,1))
inv_pSigma = inv(pSigma[:,:,k]) \
+ np.diag(np.tile(threshold,(1,np.ndim(pSigma[:,:,k]))))
tmp = np.sum(np.dot(Xshift,inv_pSigma) * Xshift,axis=1)
coef = (2*np.pi)**(-D/2) * np.sqrt(np.linalg.det(inv_pSigma))
Px[:,k] = coef * np.exp(-0.5 * tmp)
return Px
def test():
X = pu.readDataFromTxt('testSet.txt')
num = np.size(X)
X = np.reshape(X,(num/2,2))
ppx = gmm(X,4)
index = np.argmax(ppx,axis=1)
plt.figure()
plt.scatter(X[index==0][:,0],X[index==0][:,1],s=60,c=u'r',marker=u'o')
plt.scatter(X[index==1][:,0],X[index==1][:,1],s=60,c=u'b',marker=u'o')
plt.scatter(X[index==2][:,0],X[index==2][:,1],s=60,c=u'y',marker=u'o')
plt.scatter(X[index==3][:,0],X[index==3][:,1],s=60,c=u'g',marker=u'o')
if __name__ == '__main__':
test()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
效果如下:

奇怪的是,用Python实现的时候,并没有出现协方差矩阵是奇异矩阵的现象,这是什么原因我也不是很清楚。
GMM与K-means对比
- 聚类效果差不多,初始值敏感的缺点也差不多,解决方案也差不多,二分法。
- 不同点:GMM输出的是数据点属于每个每类的概率,我们用最大似然方法去确定分类。就严谨性来说,用概率进行描述数据点的分类,GMM显然要比K-mean好很多。
关于GMM算法中奇异矩阵的问题
这个问题应该说是GMM算法的一个瑕疵,如果运行上面的代码可以发现在求协方差矩阵的逆矩阵的时候,有时候会报错,说协方差矩阵是奇异矩阵(singular),此时求解矩阵的行列式就会报错,关于这个问题,pluskid在 一篇博客
中已经说的很清楚。这里总结一下解决方法:
- 假设有N个D维的样本数据,如果协方差矩阵是奇异矩阵,那么要检查一下N是否足够大,D是否可以减少几维
- 最简单的解决方法之一,在协方差矩阵上加上一个对角线矩阵 λIλI,其中 λλ 要足够小 ,不过如果数据集太小,这样也只是减少发生协方差矩阵是奇异矩阵的概率而已。
代码和数据都已近存放到 GitHub ,可以提供下载,如果觉得有用就请给个star吧。