在这里我们讲怎么用python实现朴素贝叶斯分类器,具体的关于朴素贝叶斯分类模型的详细讲解,我会在接下来的学习中涉及。
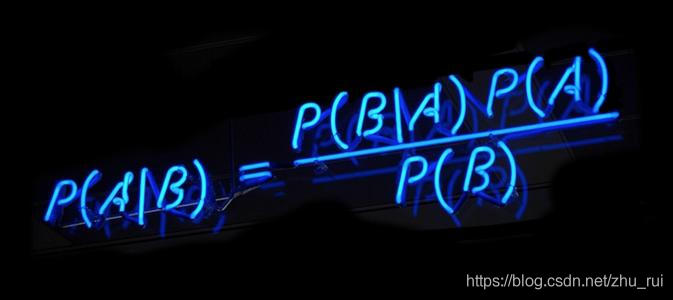
1. 朴素贝叶斯分类器概念
朴素贝叶斯分类模型是一种简单的构造分类器的方法。它将问题分为特征向量和决策向量两类(通过独立检查每个特征来学习参数,并从每个特征中收集简单的类别统计数据。),并且假设问题的特征变量都是互相府里的作用于决策变量的,也就是问题的特征之间互不相干。
朴素贝叶斯分类器是则一种与线性模型非常相类似的一种分类器。它的训练速度更快。
但是这种高效率所带来的缺点就是,朴素贝叶斯模型的泛化能力要比线性模型强。
2. 朴素贝叶斯分类器分类
- GaussianNB分类器(高斯)
GaussianNB可应用于任意连续数据,主要用于高维数据,计算的时候会保存每个类别中每个特征的平均值和标准差。
- BernoulliNB分类器(伯努利)
BernoulliNB假定输入数据为二分类数据,主要用于文本数据分类,计算每个类别中每个特征不为0的元素个数。
- MultinomNB分类器(多项式)
MultinomNB假定输入数据为基数数据(即每个特征代表某个对象的整数计数,比如一个单词在句子里出现的次数),主要用于文本数据分类。计算类别中每个特征的平均值。
3. 对朴素贝叶斯(高斯)分类模型进行分析
数据源是sklearn中聚类生成器(make_blobs)生成的50000个随机样本(其中每个样本的特征数为2个,共有3个类簇,样本集的标准差事1.0,随机种子数是42)
运行代码如下:
from sklearn.datasets import make_blobs
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import GaussianNB
n_samples=50000
centers = [(-5,-5),(0,0),(5,5)]
#n_samples是待生成的样本的总数。
#n_features是每个样本的特征数。
#centers表示类别数。
#cluster_std表示每个类别的方差,例如我们希望生成2类数据,
#后一类比前一类具有更大的方差,可以将cluster_std设置为[1.0,3.0]。
#shuffle表示刷新样本,默认值为True
#random_state表示随机种子数
X,y = make_blobs(n_samples=n_samples,n_features=2,cluster_std=1.0,centers=centers,
shuffle=False,random_state=42)
y[:n_samples // 2] = 0
y[n_samples //2 :] = 1
#RandomState(42)使每次随机生成数一样,随机种子数为42
#rand返回一个或一组服从“0~1”均匀分布的随机样本值。随机样本取值范围是[0,1),不包括1。
#rand的传入参数为y.shape[0]也就是50000,返回含有50000个元素的一维数组
sample_weight = np.random.RandomState(42).rand(y.shape[0])
X_train,X_test,y_train,y_test,sw_train,sw_test=train_test_split(X,y,sample_weight,
random_state=42)
clf = GaussianNB()
clf.fit(X_train,y_train)#训练模型
print("accurcy score :{:}".format(clf.score(X_test,y_test)))#测试模型
输出分类结果:
accurcy score :0.8331
在这里只是简单的介绍了一下怎么使用朴素贝叶斯分类器。就不举其余两个的例子了,但是我们需要了解,BernoulliNB和MultinomNB都只有一个参数alpha用于控制模型复杂度。alpha越大,平滑化越强,模型复杂度越低。但是alpha对模型性能并不是很重要,但是调整这个参数通常会使精度有所提高。

- 完整代码都在文章里面全部可以运行
- 有不懂得地方和问题请留言
- 这是一个系列,大家可以收藏一下以后学习用得到