百度论文复现——打卡学习计划
下面给出课程链接
https://aistudio.baidu.com/aistudio/education/group/info/1340
论文复现课程概述及车牌识别实践
这不单单是课程设计思路,也是小白由浅入深之路
最近哈工大被禁也是个问题,不得不考虑PYTORCH和TENSORFLOW前途,因此学习paddle也是必要的
车牌识别实践
官方的全连接层模型虽然经过调参可能达到90大几,但是建议还是尝试别的网络
#定义DNN网络
from paddle.fluid.dygraph import Conv2D
class MyCNN(fluid.dygraph.Layer):
'''
DNN网络
'''
def __init__(self):
super(MyDNN,self).__init__()
self.hidden1_1 = Conv2D(1,28,5,1) #通道数、卷积核个数、卷积核大小
self.hidden1_2 = Pool2D(pool_size=2,pool_type='max',pool_stride=1)
self.hidden2_1 = Conv2D(28,32,3,1)
self.hidden2_2 = Pool2D(pool_size=2,pool_type='max',pool_stride=1)
self.hidden3 = Conv2D(32,32,3,1)
self.hidden4 = Linear(32*10*10,65,act='softmax')
def forward(self,input): # forward 定义执行实际运行时网络的执行逻辑
'''前向计算'''
x = self.hidden1_1(input)
x = self.hidden1_2(x)
x = self.hidden2_1(x)
x = self.hidden2_2(x)
x = self.hidden3(x)
x = fluid.layers.reshape(x, shape=[-1, 32*10*10])
y = self.hidden4(x)
return y
GAN入门
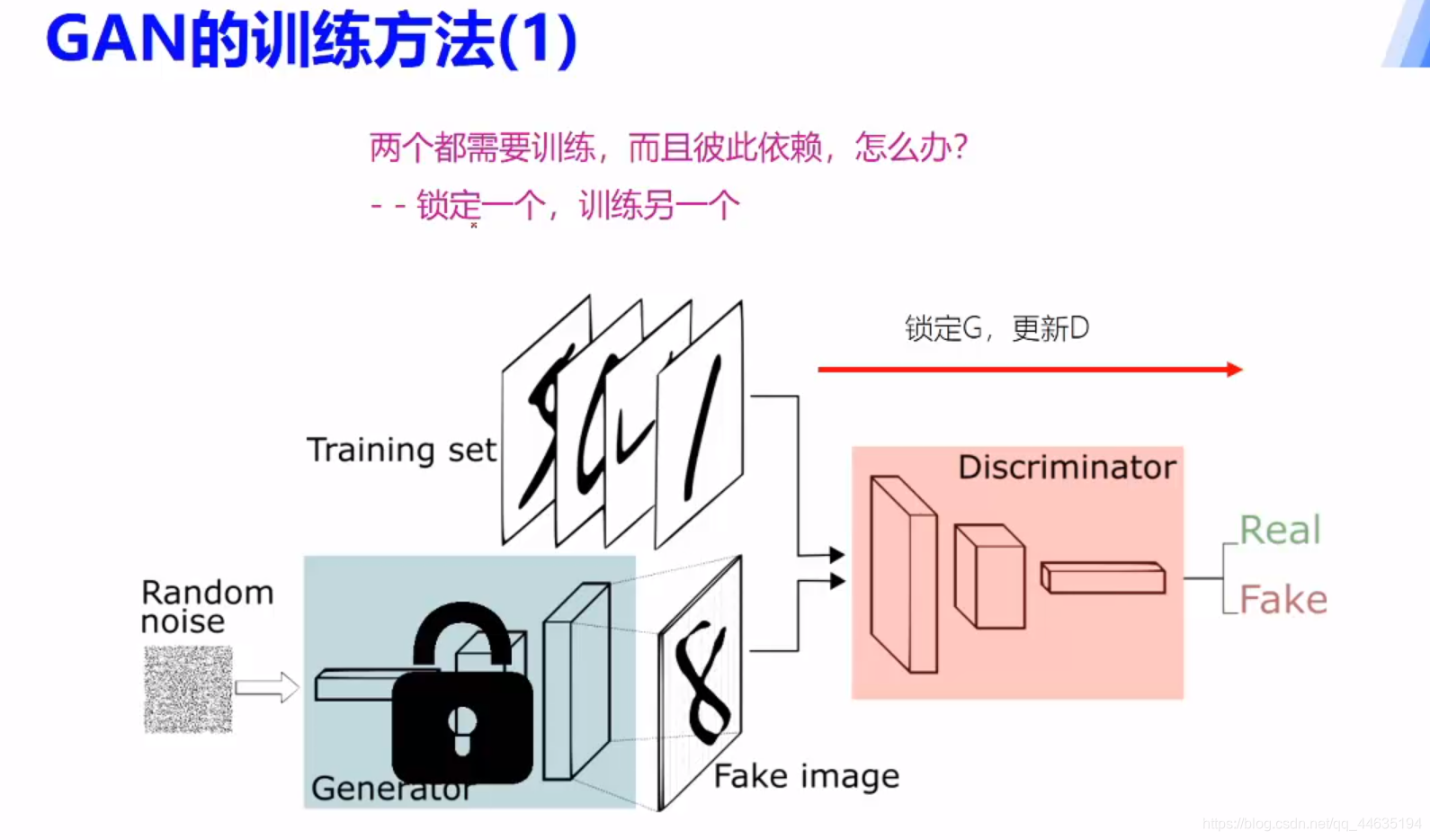
GAN原理
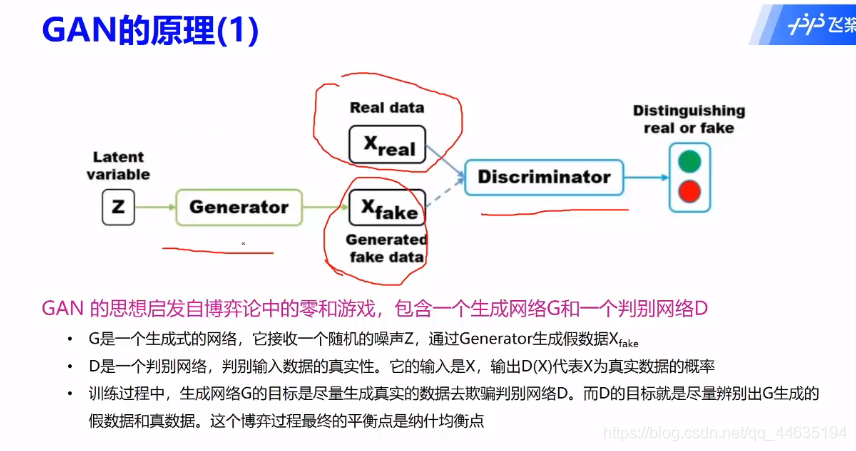
理想状态就是生成器生成的数据让判别网络不能准确判别,达到以假乱真的目的
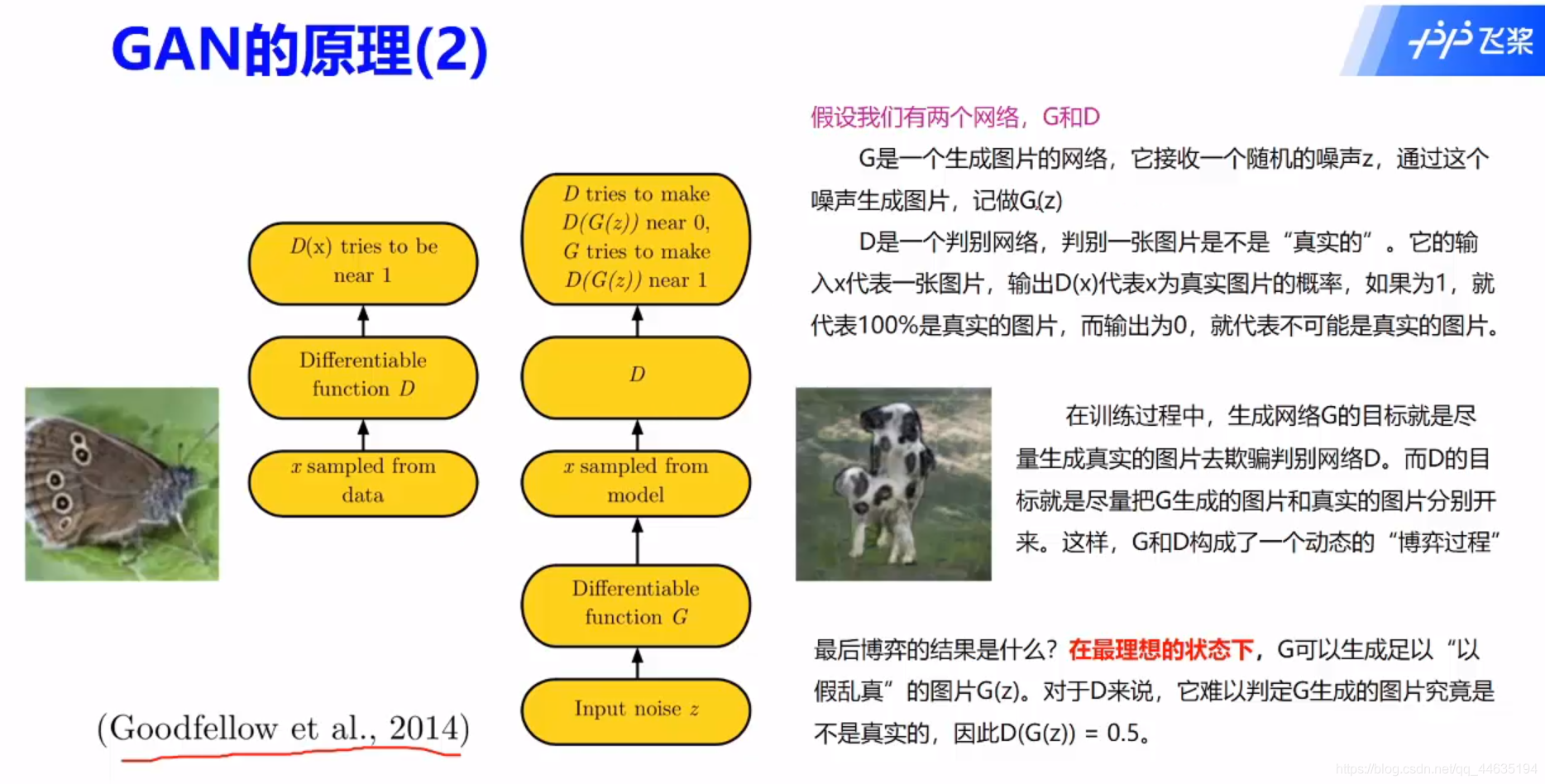



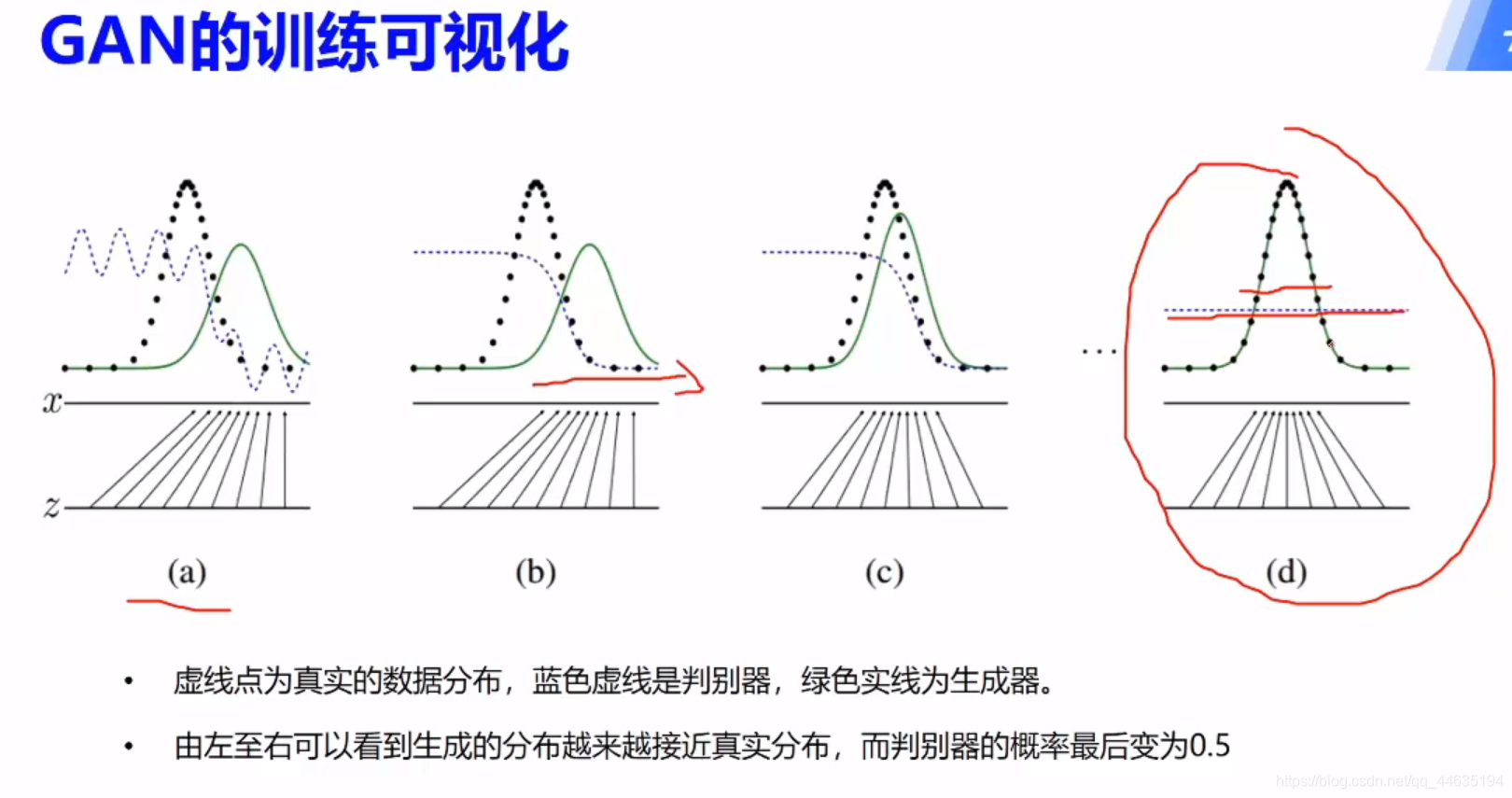



这个可以理解为你画了一幅贼丑的画,老师为了不伤你的心告诉你很好,然后你就在画丑画的路上一去不复返~
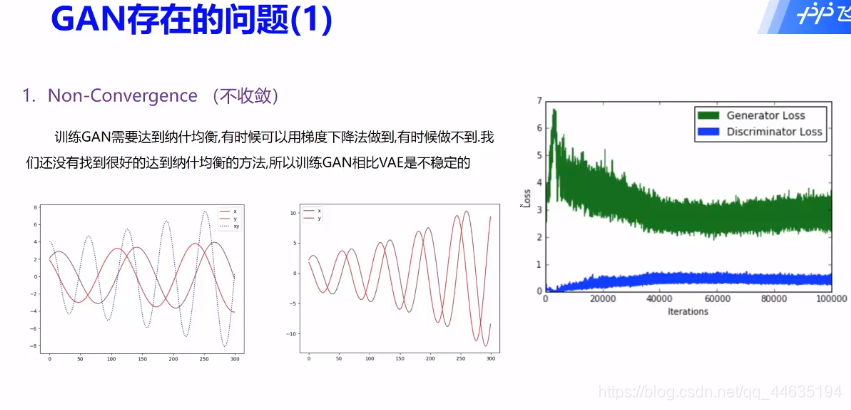
GAN常见模型
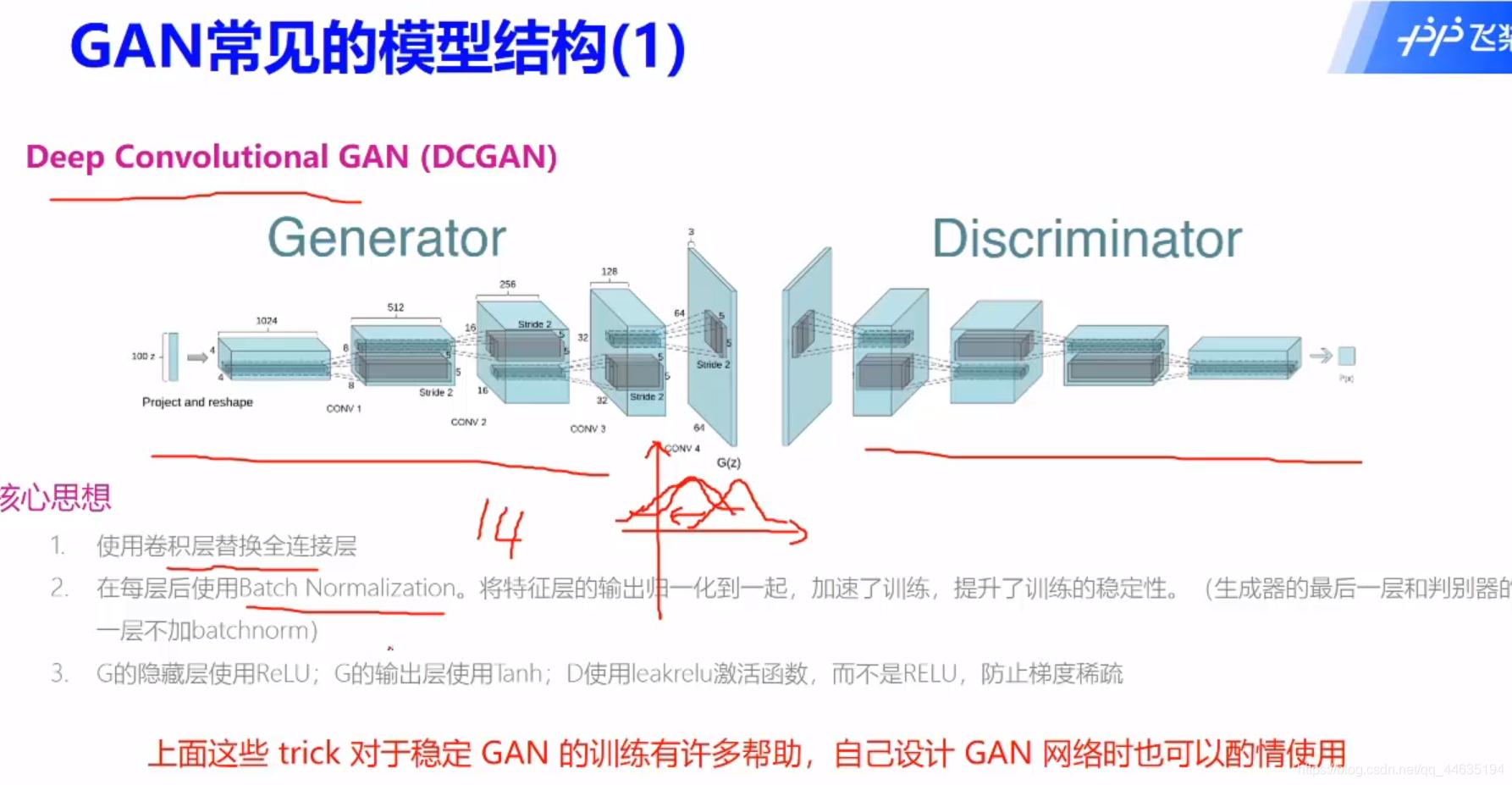
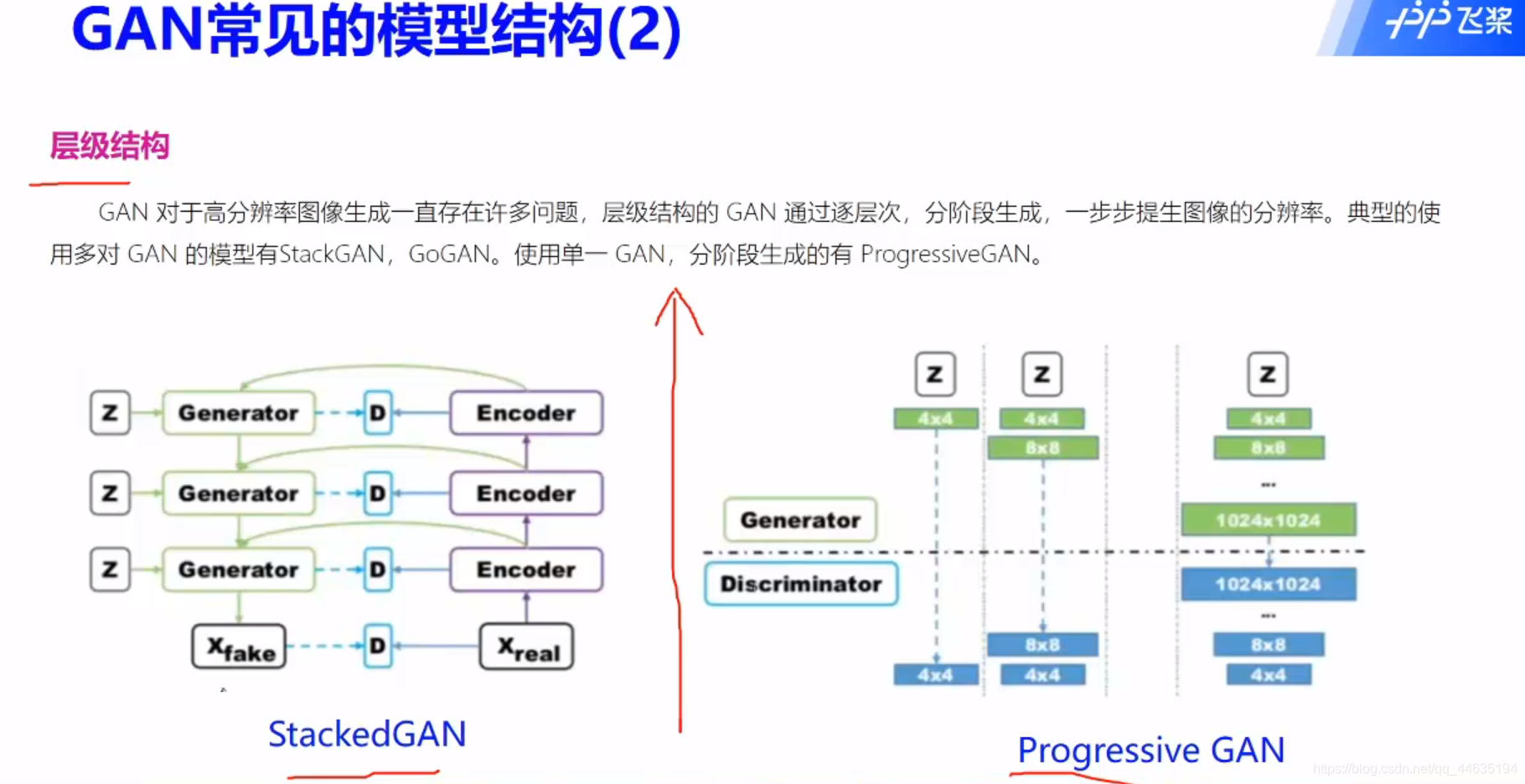
GAN的改进方案
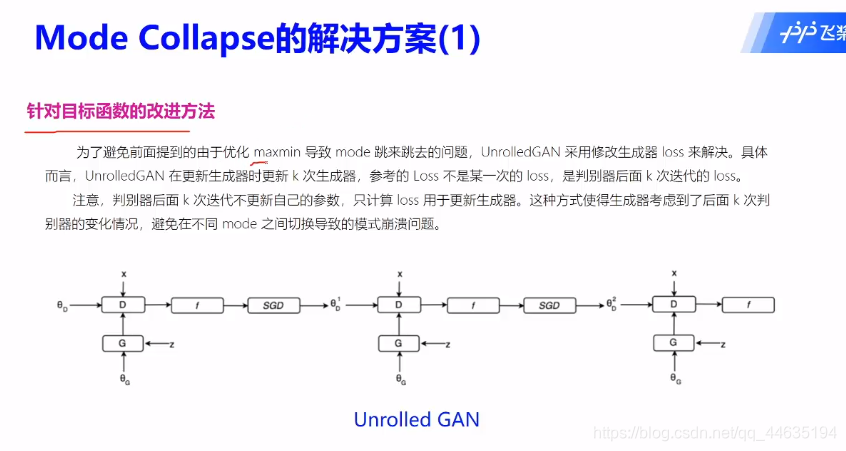
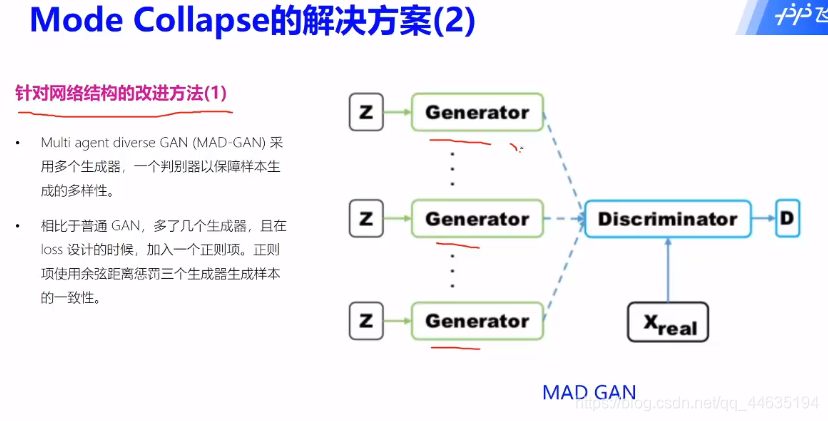


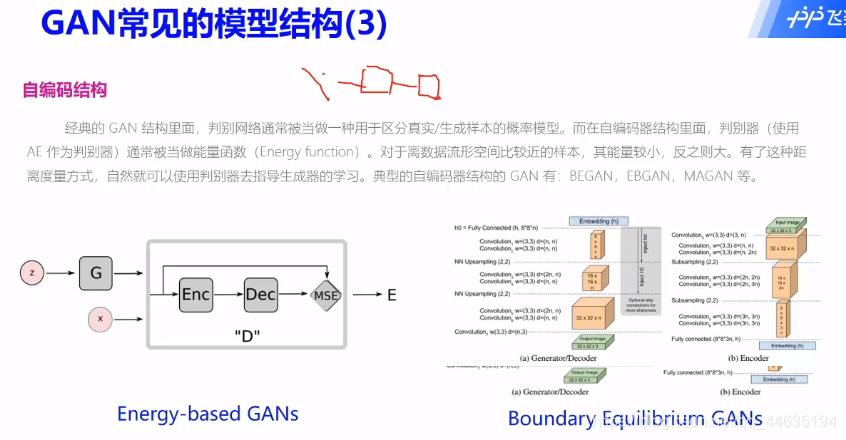
GAN应用场景


复现手写字体
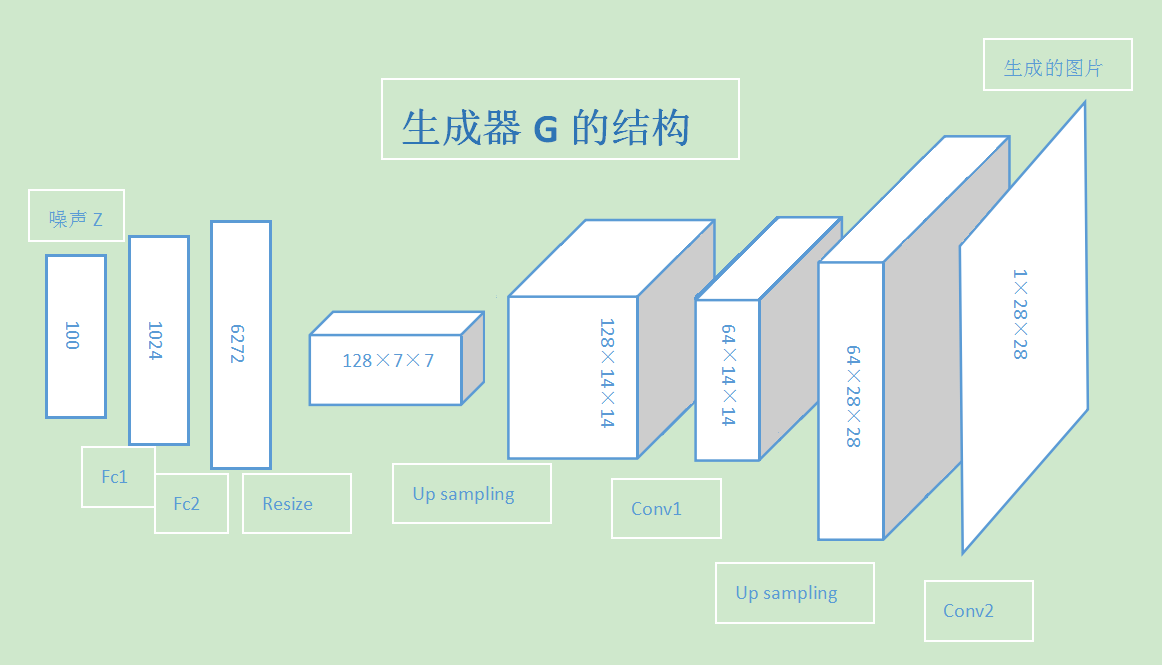
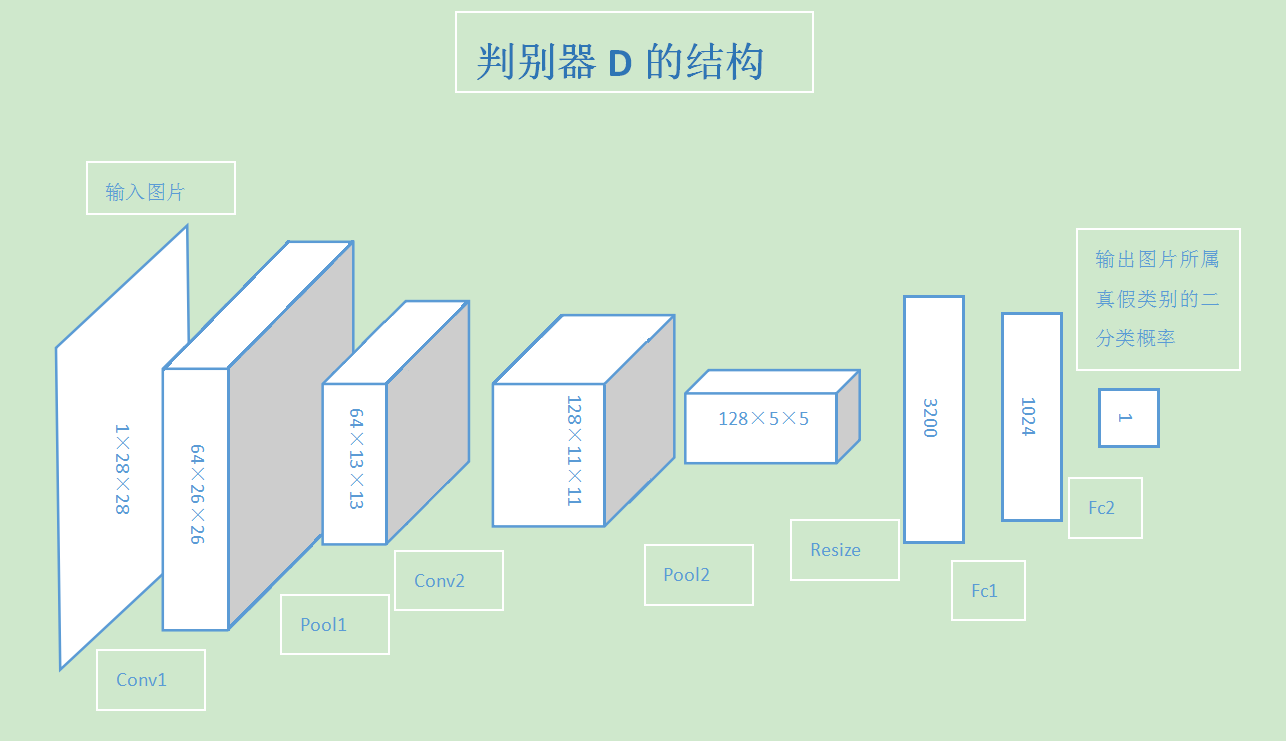
# 通过上采样扩大特征图
class G(fluid.dygraph.Layer):
def __init__(self, name_scope):
super(G, self).__init__(name_scope)
name_scope = self.full_name()
#
self.h1=Linear(100,1024)
self.h2=paddle.fluid.dygraph.BatchNorm(1024,act='tanh')
self.h3=Linear(1024,6272)
self.h4=paddle.fluid.dygraph.BatchNorm(6272,act='tanh')
#
self.h5=Conv2D(128,64,filter_size=5,padding=2)
self.h6=paddle.fluid.dygraph.BatchNorm(64,act='tanh')
self.h7=Conv2D(64,1,filter_size=5,padding=2,act='tanh')
def forward(self, z):
#
# My_G forward的代码
#
z=fluid.layers.reshape(z,shape=[-1,100])
y=self.h1(z)
y=self.h2(y)
y=self.h3(y)
y=self.h4(y)
y=fluid.layers.reshape(y,shape=[-1,128,7,7])
y=fluid.layers.image_resize(y,scale=2)
y=self.h5(y)
y=self.h6(y)
y=fluid.layers.image_resize(y,scale=2)
y=self.h7(y)
return y
class D(fluid.dygraph.Layer):
def __init__(self, name_scope):
super(D, self).__init__(name_scope)
name_scope = self.full_name()
#
# My_D的代码
#
self.h1=Conv2D(1,64,filter_size=3)
self.h2=paddle.fluid.dygraph.BatchNorm(64,act='relu')
self.h3=Pool2D(pool_size=2,pool_stride=2)
self.h4=Conv2D(64,128,filter_size=3)
self.h5=paddle.fluid.dygraph.BatchNorm(128,act='relu')
self.h6=Pool2D(pool_size=2,pool_stride=2)
self.h7=Linear(128*5*5,1024)
self.h8=paddle.fluid.dygraph.BatchNorm(1024,act='relu')
self.h9=Linear(1024,1)
def forward(self, img):
#
# My_G forward的代码
#
y=self.h1(img)
y=self.h2(y)
y=self.h3(y)
y=self.h4(y)
y=self.h5(y)
y=self.h6(y)
y=fluid.layers.reshape(y,shape=[-1,128*5*5])
y=self.h7(y)
y=self.h8(y)
y=self.h9(y)
return y
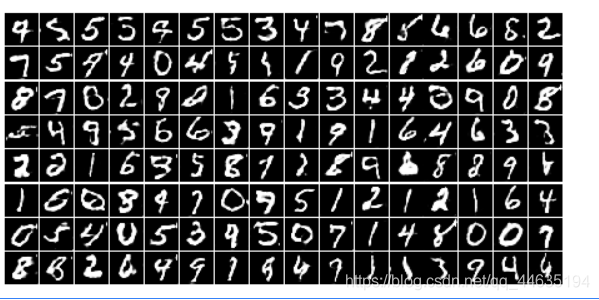
最后的效果图
视频分类入门
简述


方法概述
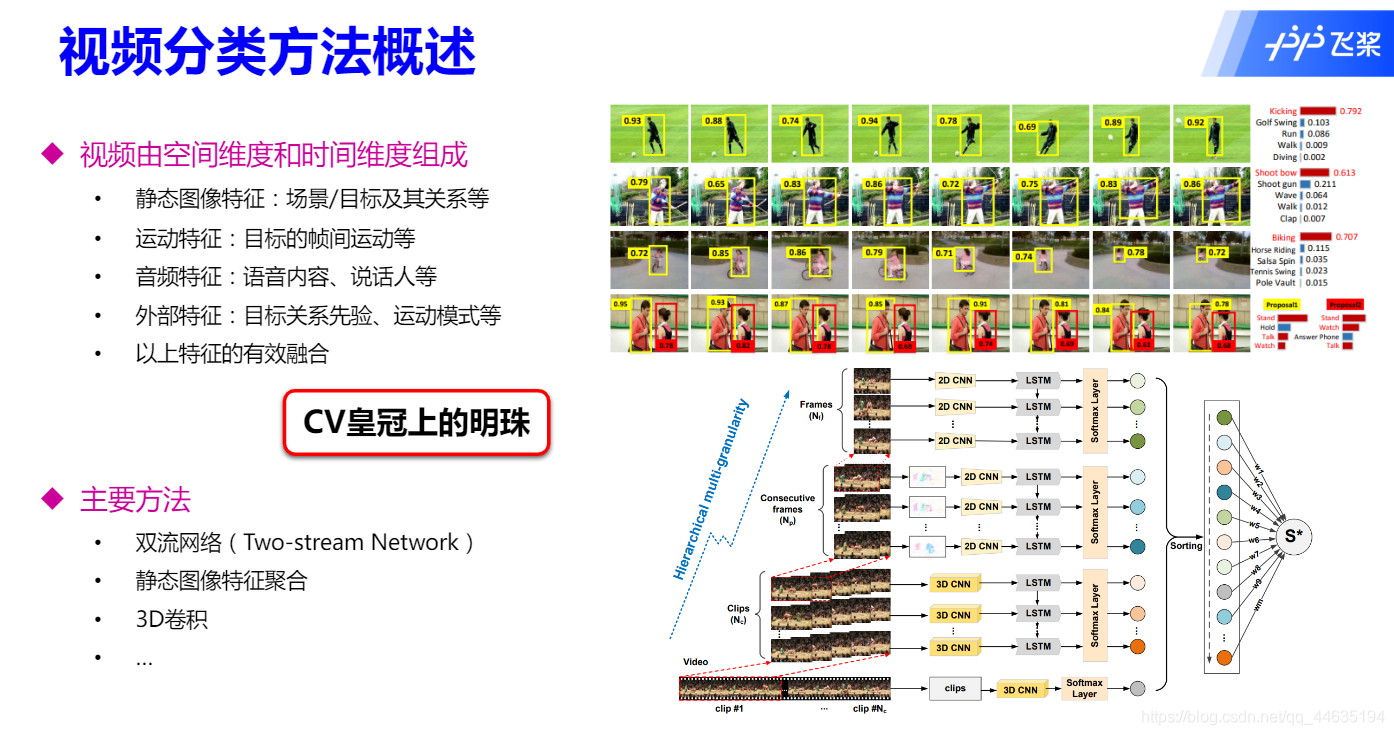




趋势

网络复现
GAN方向(论文阅读)StarGAN v2: Diverse Image Synthesis for Multiple Domains
效果展示

这是这篇论文的一个生成效果图,第一列是输入图像,后面的是y StarGAN v2生成的图像
摘要

摘要提出了一个好的图像到图像模型应满足:
- 生成图像的多样性
- 多域的可拓展性
提出的模型很好地满足了上面两个要求,并在数据集上得到了验证,然后也给出了github的地址(nice)
简介

-
简单的介绍了下好的图像到图像模型应该生成包含在多领域多风格的图像
-
提出了设计这样的模型的复杂和难点在于数据集的有任意数量大量的样式和域

-
现在已经有很多解决风格多样性的方法,但是这些方法只考虑了两个域之间的映射,无法扩展到多域

-
为了解决上述问题提出了StarGAN
-
但是StarGAN仍旧存在问题,但是次模型仍旧只捕捉到了确定的映射,没有捕捉到分布的多模态性
-
这个限制的原因来自每个域由确定的标签来表明

- 为了两全其美,提出了StarGAN v2,一个拥有较好可扩展性的方法,能扩多个领域生成多样化图像。
- 从StarGAN开始,用我们提议的特定于领域的风格代码替换它的域标签,这些代码可以代表特定领域的不同风格
- 两个模块:映射网络和样式编码器。映射网络学习将随机高斯噪声转换为风格码,而编码器学习从给定的参考图像中提取风格码
- 考虑到多个域,两个模块都有多个输出分支,每个分支都提供特定域的样式代码。最后,利用这些样式代码,我们的生成器学会了在多个域上成功地合成不同的图像。
- 模型确实从使用样式代码中获益。通过实证证明,提出的方法可扩展到多个领域,并且在视觉质量和多样性方面,与领先的方法相比,取得了显著更好的结果

- 证明模型确实从使用样式代码中获益。经验证明,方法可扩展到多个领域,在视觉质量和多样性方面,与领先的方法相比,提供了更好的结果
StarGAN v2
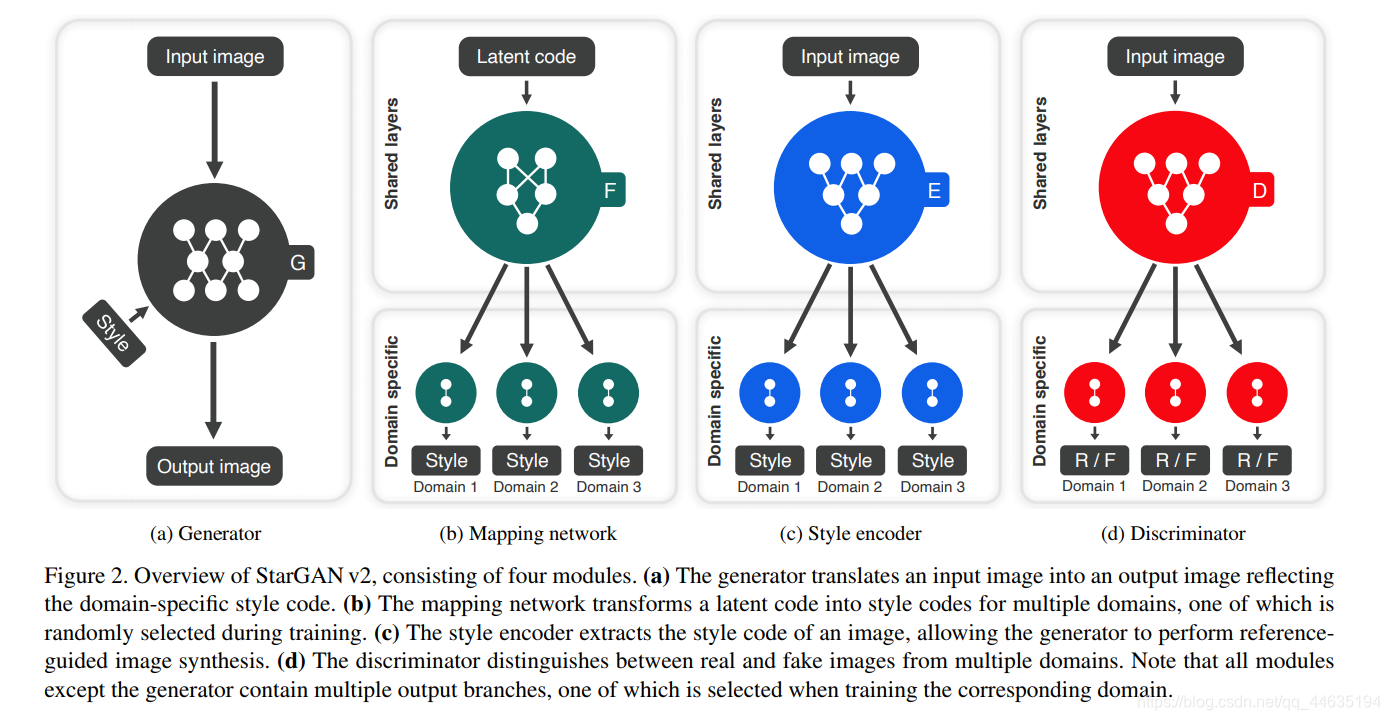
框架
训练目标
对抗损失
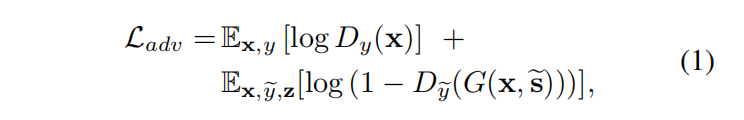
使用样式重建损失
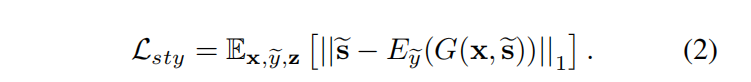
引入多样化敏感损失,是G能生成多样化图像
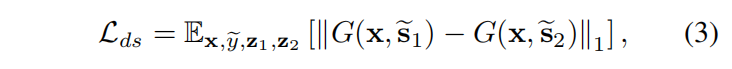
为了保证生成的图像G正确地保留了其输入图像x的域不变特征(例如姿态),使用了循环一致性丢失
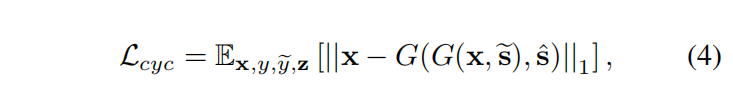
总目标函数
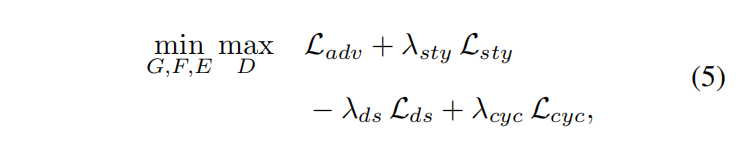
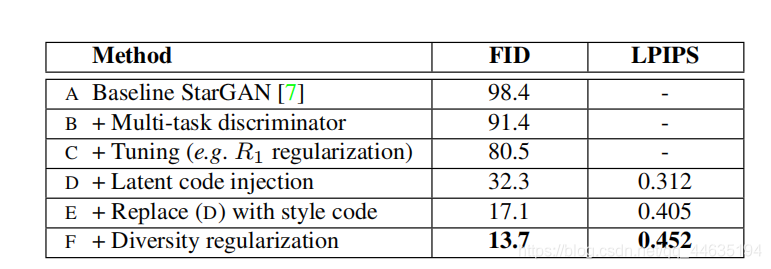
FID表示生成图像和真实图像的分布距离,越低越好,LPIPS度量了图像多样化,越高越好
相关工作
- StyleGAN转换真实图像时,这种方法需要付出不小的努力,因为它的生成器并不是设计来接受图像作为输入的。
- 所有这些方法都只考虑了两个域,并将其扩展到多个域是很有意义的
上面除了损失函数都是一些套话和工作介绍,下面开始讲细节
训练细节
- Batch size:8
- iterations 100K
- λsty = 1, λds = 1,and λcyc = 1 for CelebA-HQ
- λsty = 1, λds = 2, andλcyc = 1 for AFHQ
- the weightλds is linearly decayed to zero over the 100K iterations
- We adopt the non-saturating adversarial loss with R1regularization [35] using γ = 1
- We use the Adam optimizer with β1 = 0 and β2 = 0.99.
- The learning ratesfor G, D, and E are set to 10 -4,while that of F is set to10 -6
- We initialize the weights of all modules using He initialization and set all biases to zero,
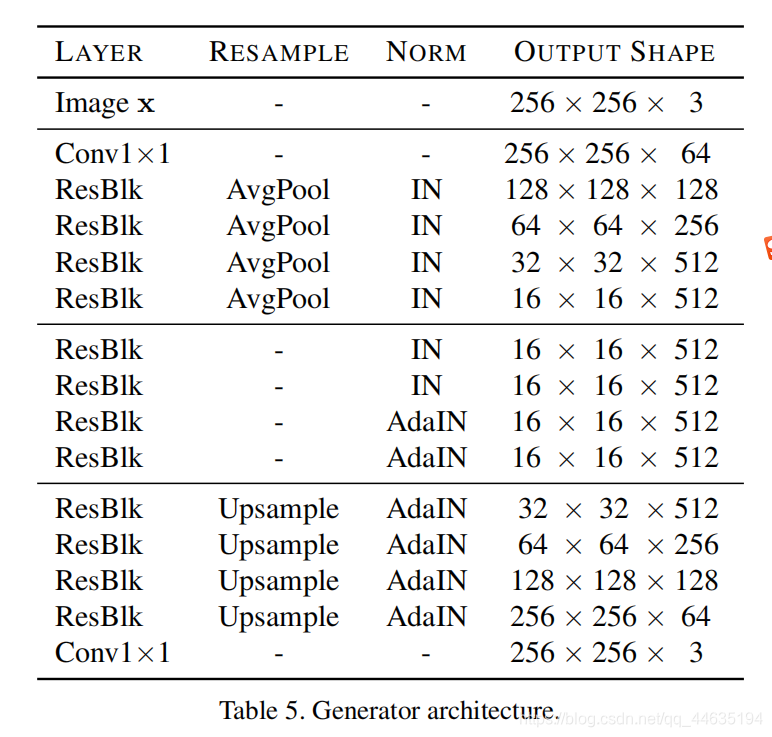
网络结构
生成器:
- 四个下采样区、四个中间采样区和四个上采样区组成
- 对上下采样区块分别使用实例归一化(IN)和自适应实例归一化(AdaIN)]。样式代码被注入到所有的层中,通过学习仿射变换提供缩放和移动向量。
- 对于CelebA-HQ,增加了一层下采样层和上采样层。
- remove all shortcuts in the upsampling residual blocks and add skip connections with the adaptive
wing based heatmap
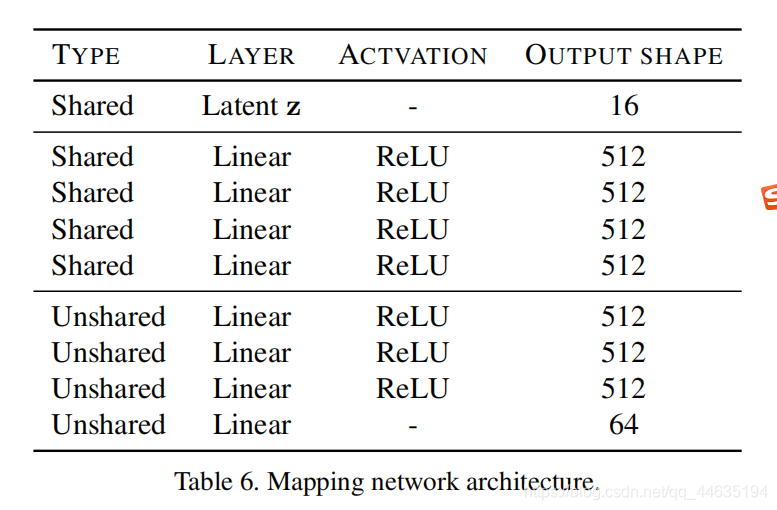
映射网络
- 由一个带有K个输出分支的MLP组成,其中K表示域的数量。
- 所有域共享四个完全连接层,每个域共享四个特定的完全连接层
- 将潜在代码、隐藏层和样式代码的维度分别设置为16、512和64
- 从标准高斯分布中抽取潜码样本
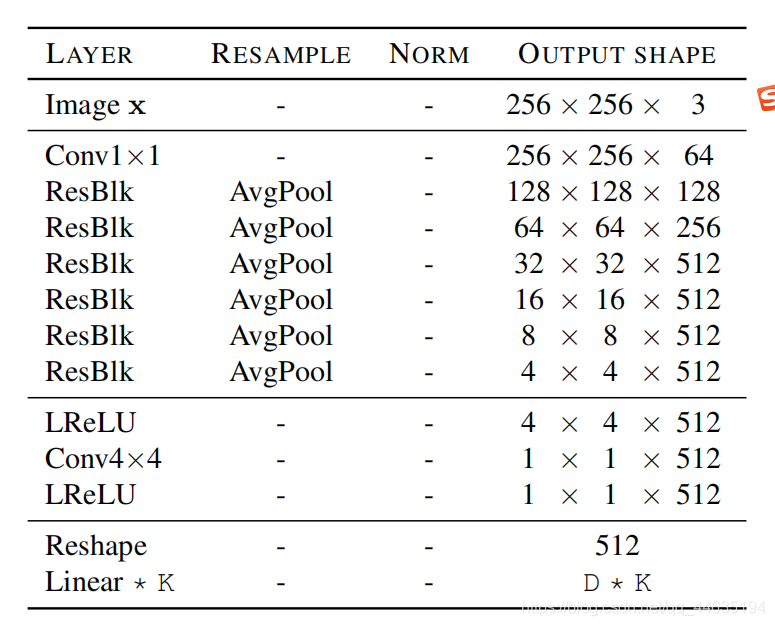
风格编码器
- 由一个带有K个输出分支的CNN组成,其中K是域的数量。在所有域之间共享六个预激活剩余块,然后为每个域共享一个特定的全连接层
判别器
- 鉴别器包含6个预激活残块,残块有泄漏的ReLU。我们使用K个全连通层对每个域进行真/假分类,其中K表示域的数量。