
T1:跳格子
题目
n 个格子排成一列,一开始,你在第一个格子,目标为跳到第 n 个格子。在每个格子 i 里面你可以做出两个选择:
选择「a」:向前跳 ai 步。
选择「b」:向前跳 bi 步。
把每步的选择写成一个关于字符 a 和 b的字符串。求到达格子 n 的方案中,字典序最小的字符串。当做出某个选择时,你跳出了这n个格子的范围,则这个选择是不合法的。
当没有合法的选择序列时,输出 No solution!
当字典序最小的字符串无限长时,输出 Infinity!
否则,输出这个选择字符串
输入格式
输入有三行。
第一行输入一个整数n
第二行输入 n 个整数,分别表示 ai
第三行输入 n 个整数,分别表示 bi
输出格式
输出一行字符串表示答案。
样例
样例输入
7
5 -3 6 5 -5 -1 6
-6 1 4 -2 0 -2 0
样例输出
abbbb
数据范围与提示
题解
其实不用太害怕,我们先打个暴力试试水,发现最傻的暴力都有80,我们就可以知道这道题很简单
这道题后面的分数来自于
的判断,刚开始读完题后可能大多数人是无法理解这句话的
我们来想想什么情况下会无限死循环。这个就要与字典序挂钩了,字典序并不先比较长度,用过字典的吧!
在此题中只要对于
位而言,只要填
后面的字符串的字典序一定小于填
所以看一下这个神奇的栗子:
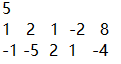
我们会从1选a跳到2再选a跳到4最后选b就可以跳到n了,答案是aab
但是我们发现如果跳到4后可以选择一次a回到2,再从2回到4,最后选b到n,答案变成aaaab
根据字典序第三位一个是a,一个是b,a所在的字符串字典序较小,以此类推,我们的答案就可以变成aaaaaaa…b
显然中间的a越多,字典序越小,这就是
的输出
但不仅仅是这么简单,如果是这样子的栗子:

我们的答案是aaa,但是这里面仍然有循环出现,跳到格子4后,选择b跳回2,但是我们发现这只会让答案变成aabbb…ba,第三位比较就知道字典序大于了aaa,所以这种循环的出现我们是可以输出最后答案字符串的
因此我们来思考一下如何辨别这种情况,用一个手打队列记录下我们一路上的选择,
假设1代表选a,0代表选b。在最后走到格子n的时候,就模拟一下这一路上的跳跃过程,
发现如果在跳跃的某一个点时选择a会跳到已经跳过的点上并且按照我们的答案存取发现这个点应该选b才能保证后面能跳到最后格子时就意味着死循环出现了

否则仍然有解
CODE
#include <cstdio>
#include <cstring>
using namespace std;
#define MAXN 100005
int n, idx;
int a[MAXN], b[MAXN], st[MAXN];
bool vis[MAXN];
bool flag;
void dfs ( int id ) {
if ( flag )
return;
if ( id > n || id < 1 )
return;
if ( vis[id] )
return;
vis[id] = 1;
if ( id == n ) {
flag = 1;
memset ( vis, 0, sizeof ( vis ) );
int t = 1;
vis[1] = 1;
for ( int i = 1;i <= idx;i ++ ) {
if ( st[i] )
t = t + a[t];
else {
if ( t + a[t] > 0 && t + a[t] <= n && vis[t + a[t]] ) {
printf ( "Infinity!" );
return;
}
t = t + b[t];
vis[t] = 1;
}
}
for ( int i = 1;i <= idx;i ++ )
printf ( "%c", st[i] ? 'a' : 'b' );
return;
}
st[++ idx] = 1;
dfs ( id + a[id] );
idx --;
st[++ idx] = 0;
dfs ( id + b[id] );
idx --;
}
int main() {
scanf ( "%d", &n );
for ( int i = 1;i <= n;i ++ )
scanf ( "%d", &a[i] );
for ( int i = 1;i <= n;i ++ )
scanf ( "%d", &b[i] );
dfs ( 1 );
if ( ! flag )
printf ( "No solution!" );
return 0;
}
T2:英雄联盟
题目
正在上大学的小皮球热爱英雄联盟这款游戏,而且打的很菜,被网友们戏称为「小学生」。
现在,小皮球终于受不了网友们的嘲讽,决定变强了,他变强的方法就是:买皮肤!
小皮球只会玩
个英雄,因此,他也只准备给这
个英雄买皮肤,并且决定,以后只玩有皮肤的英雄。
这 个英雄中,第 个英雄有 款皮肤,价格是每款 Q 币(同一个英雄的皮肤价格相同)。
为了让自己看起来高大上一些,小皮球决定给同学们展示一下自己的皮肤,展示的思路是这样的:对于有皮肤的每一个英雄,随便选一个皮肤给同学看。
比如,小皮球共有 5 个英雄,这 5 个英雄分别有 款皮肤,那么,小皮球就有 种展示的策略。
现在,小皮球希望自己的展示策略能够至少达到 \text{M}M 种,请问,小皮球至少要花多少钱呢?
输入格式
第一行,两个整数
第二行,
个整数,表示每个英雄的皮肤数量
第三行,\text{N}N 个整数,表示每个英雄皮肤的价格
输出格式
一个整数,表示小皮球达到目标最少的花费。
输入输出样例
输入
3 24
4 4 4
2 2 2
输出
18
说明/提示
样例解释
每一个英雄都只有4款皮肤,每款皮肤2Q币,那么每个英雄买3款皮肤,
,共花费
Q币。
数据范围
共 10 组数据,第
组数据满足:
的数据:
保证有解
题解
这是一道水水的
,看都看的出来

从最简单的二维dp搞起:
设
表示前i种皮肤共花费j元的最大的不同种展示策略数,
我们发现这个转移式的第一维只跟上一次的
有关,我们就可以考虑滚动(我就是这么写的)
当然滚动也能被压成一维
要注意要从大到小,因为要用到上一次的前面的
,如果我们先更新了小的,后面更新大的的时候会产生错误

CODE
#include <cstdio>
#include <cstring>
#include <iostream>
using namespace std;
#define MAXN 305
#define MAXM 600005
#define LL long long
int n;
LL m, sum;
LL dp[2][MAXM], k[MAXN], c[MAXN];
int main() {
scanf ( "%d %lld", &n, &m );
for ( int i = 1;i <= n;i ++ )
scanf ( "%lld", &k[i] );
for ( int i = 1;i <= n;i ++ ) {
scanf ( "%lld", &c[i] );
sum += k[i] * c[i];
}
for ( int i = 0;i <= sum;i ++ )
dp[0][i] = dp[1][i] = 1;
int f = 0;
for ( int i = 1;i <= n;i ++ ) {
f = ! f;
for ( int j = c[i];j <= sum;j ++ ) {
dp[f][j] = dp[!f][j];//记得初始化
for ( int p = 1;p <= k[i];p ++ ) {
if ( j < p * c[i] )
break;
dp[f][j] = max ( dp[f][j], dp[!f][j - p * c[i]] * p );
}
}
}
for ( int i = 1;i <= sum;i ++ )
if ( dp[f][i] >= m )
return ! printf ( "%d", i );
return 0;
}
T3:排序问题
题目
九条可怜是一个热爱思考的女孩子。
题目描述
九条可怜最近正在研究各种排序的性质,她发现了一种很有趣的排序方法: Gobo sort !
Gobo sort 的算法描述大致如下:
假设我们要对一个大小为 n 的数列 a 排序。
等概率随机生成一个大小为 n 的排列 p 。
构造一个大小为 n 的数列 b 满足
b,检查 b 是否有序,如果 b 已经有序了就结束算法,并返回 b ,不然返回步骤 2。
显然这个算法的期望时间复杂度是
的,但是九条可怜惊奇的发现,利用量子的神奇性质,在量子系统中,可以把这个算法的时间复杂度优化到线性。
九条可怜对这个排序算法进行了进一步研究,她发现如果一个序列满足一些性质,那么 Gobo sort 会很快计算出正确的结果。为了量化这个速度,她定义 Gobo sort 的执行轮数是步骤 2 的执行次数。
于是她就想到了这么一个问题:
现在有一个长度为 n 的序列 x ,九条可怜会在这个序列后面加入 m 个元素,每个元素是 [l,r] 内的正整数。 她希望新的长度为 n+m 的序列执行 Gobo sort 的期望执行轮数尽量的多。她希望得到这个最多的期望轮数。
九条可怜很聪明,她很快就算出了答案,她希望和你核对一下,由于这个期望轮数实在是太大了,于是她只要求你输出对 998244353 取模的结果。
输入格式
第一行输入一个整数 T,表示数据组数。
接下来
行描述了 T 组数据。
每组数据分成两行,第 1 行有四个正整数 n,m,l,r,表示数列的长度和加入数字的个数和加入数字的范围。 第 2 行有 n 个正整数,第 i 个表示
输出格式
输出 TT 个整数,表示答案。
输入输出样例
输入
2
3 3 1 2
1 3 4
3 3 5 7
1 3 4
输出
180
720
说明/提示
样例解释
对于第一组数据,我们可以添加
到序列的最末尾,使得这个序列变成 1 3 4 1 2 2 ,那么进行一轮的成功概率是
,因此期望需要 180 轮。
对于第二组数据,我们可以添加
到序列的最末尾,使得这个序列变成 1 3 4 5 6 7 ,那么进行一轮的成功概率是
,因此期望需要 720 轮。
数据范围
对于 30% 的数据,
对于 50% 的数据,
对于 60% 的数据,
对于 70% 的数据,
对于 90% 的数据,
对于 100% 的数据,
题解
代码中有一定的解释,帮助大家理解,我真是太善良了
首先对于一个长度为
的序列,排序后变为不同的序列的方案数为
但是会有数字重复出现,煮个栗子

虽然1的含义不一样,但这个序列只能算一个
所以排序后不同的序列的方案数应该为
表示数字x出现的次数
但是这里又出现
的抉择,我们观察上面的式子,分子是固定的,如果要最后的结果尽量大,意味着分母要尽量小,我们知道阶乘越往后乘得越大,所以这启发我们尽量控制
的一致
首先对于不属于
的数字就最先搞定,然后扔掉,不需要,接下来我们来算
区间的
的贡献
我们考虑刚开始的
个数可能有一部分会出现在区间内,我们用树状来表示一下,看图
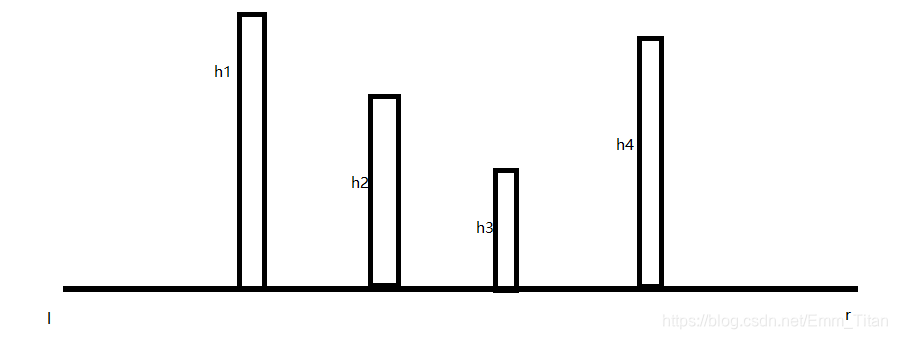
表示该数出现了
次,对应在图上就是树状的高度,因为只能填
个数,又要维持
的一致,我们就考虑二分这条线,什么线???那根黄线,看图
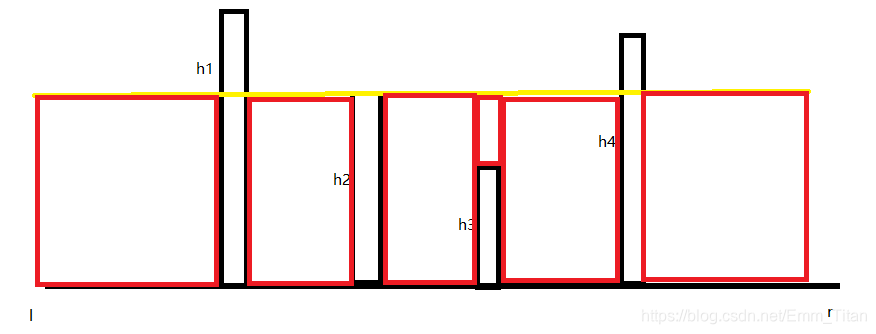
红色的部分表示填的数的区域,我们尽可能让这个黄线下的可填数区域接近于
但不能超过,但我们不能保证
刚好填完,所以有可能有些区域上面会多一层,绿色部分代表一个数的高度,看图
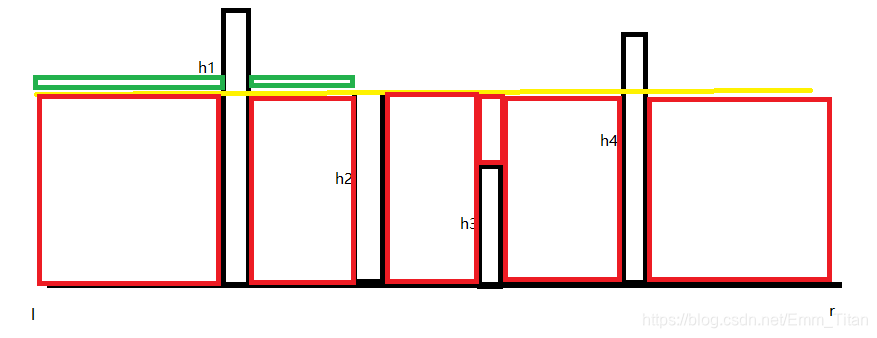
所以就划分成了三种不同类型的树状,我们分别处理
1.长度超过答案黄线的,就是个数阶乘
2.长度被我们拔高到等于黄线的,就是黄线高度阶乘,用快速幂算多个的贡献总和
3.长度在黄线之上多了仅仅一层绿帽子 ,就是高度
阶乘,用快速幂算多个的贡献总和
最后涉及到除法,又有取模强迫我们用逆元,线性筛不推荐,时间空间都挺大,我们就老老实实地用快速幂求逆元,刚好模数是一个质数,搞费马小定理

CODE
ps:这个代码可能会交出TLE,但是多交交几遍,是AC的亲测
#include <cstdio>
#include <algorithm>
using namespace std;
#define int long long
#define mod 998244353
#define MAXN 200005
#define MAXM 20000000
int T, n, m, l, r, cnt, tot, result, height;
int a[MAXN], b[MAXN], fac[MAXM + 5];
void prepare () {//预处理出阶乘
fac[0] = 1;//必须初始化0,原因在后面
for ( int i = 1;i <= MAXM;i ++ )
fac[i] = fac[i - 1] * i % mod;
}
int qkpow ( int x, int y ) {
int ans = 1;
while ( y ) {
if ( y & 1 )
ans = ans * x % mod;
x = x * x % mod;
y >>= 1;
}
return ans;
}
int inv ( int x ) {//求的是x的阶乘的逆元
return qkpow ( fac[x], mod - 2 );
}
int check ( int x ) {//统计[l,r]高度在x以下有多少个空可以选择填数字
int sum = ( r - l + 1 - tot ) * x;//未出现在a数组里面的,这一竖列上一个数字都没有
for ( int i = 1;i <= tot;i ++ )//出现在a数组里面的,统计上方空气能填几个
if ( b[i] < x )
sum += x - b[i];
return sum;
}
void solve ( int L, int R ) {
if ( L > R )
return;
int mid = ( L + R ) >> 1;
if ( check ( mid ) <= m ) {
height = mid;
solve ( mid + 1, R );
}
else
solve ( L, mid - 1 );
}
signed main() {
prepare();
scanf ( "%lld", &T );
while ( T -- ) {
scanf ( "%lld %lld %lld %lld", &n, &m, &l, &r );
for ( int i = 1;i <= n;i ++ )
scanf ( "%lld", &a[i] );
sort ( a + 1, a + n + 1 );
a[n + 1] = -1;
cnt = tot = 0;
result = fac[n + m];
for ( int i = 1;i <= n;i ++ ) {
cnt ++;
if ( a[i] != a[i + 1] ) {
if ( l <= a[i] && a[i] <= r )//具体的数字对我们来说并不重要,我们只需要知道这个数字对应的树状高度
b[++ tot] = cnt;
else
result = result * inv ( cnt ) % mod;
cnt = 0;
}
}
solve ( 0, MAXM );
m -= check ( height );//剩下的m就填不满一层,有些空会填,有些不会,就特殊处理
for ( int i = 1;i <= tot;i ++ )
if ( b[i] > height ) {//处理高于height的贡献
cnt ++;
result = result * inv ( b[i] ) % mod;
}
// 处理在height基础上多填一层的贡献 处理被我们拔高到height高度的贡献
result = result * qkpow ( inv ( height + 1 ), m ) % mod * qkpow ( inv ( height ), r - l + 1 - m - cnt ) % mod;
//注意这里的height可能等于0,如果不在上面初始化,答案就变成了0,你就从100pots变成了30pots
printf ( "%lld\n", result );
}
return 0;
}
byebye~~
