最近在读《Introduction to Data Mining 》这本书,发现课后答案只有英文版,于是打算结合自己的理解将答案翻译一下,其中难免有错误,欢迎大家指正和讨论。侵删。
第八章(上)

压缩前:220 × 32 × 4 = 134217728 bytes
压缩后:216 × 32 × 4 = 8388608 bytes
压缩率16



(a)当数据中有划分结构时。即存在子簇。
(b)当数据需要降维时,需要确定有几个簇产生。

(a)
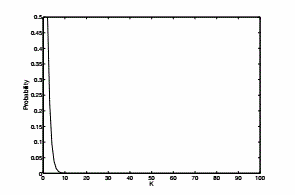
(b)0.27、5.7e-07、8.2e-64


(a)
基于中心:2个簇,长方形区域会对半分。
基于邻近性:1个簇,因为有噪声
基于密度:2个簇,是2个圆形区域,噪声不会造成影响
(b)
基于中心:1个簇,包括了所有环
基于邻近性:2个簇,是2个环形区域
基于密度:2个簇,是2个环形区域
(c)
基于中心:3个簇,是3个三角形区域(或者1个簇也可接受)
基于邻近性:1个簇,三个三角形有交点因此会被合并
基于密度:3个簇,虽然它们有交点,但交点处密度低
(d)
基于中心:2个簇,左右各一个
基于邻近性:5个簇,每条线是一个簇
基于密度:2个簇

(c)的平方误差最小,稠密区域要分配更多的质心。

最小值0,最大值1。对于每个划分的簇,簇均值就是簇中有1的百分比,比如购物篮数据,簇均值就代表一个顾客购买簇中某一确定项的可能性。值越大的分量更能代表数据,因为簇中大部分的组成成分值为0。
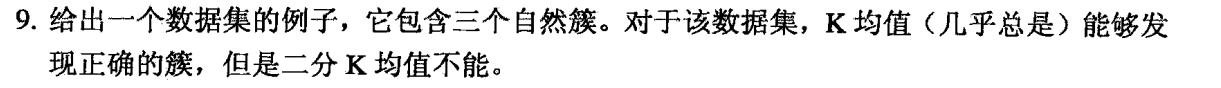
考虑一个数据集包含三个圆形簇,它们的中心在一条线上,且中间的簇中心到其他两个中心距离相等,这样,二分K均值第一次总会将中间的簇划分开来,不能得到正确的结果。
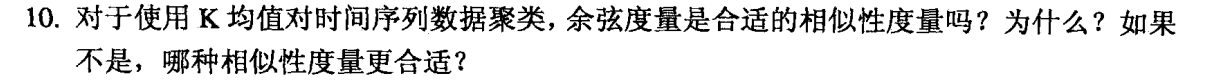
时间序列数据是稠密的高维数据,因此余弦度量并不合适,余弦度量适合稀疏数据。如果量级对于时间序列数据来说是重要的话,那么欧几里得距离是一个不错的选择。如果仅考虑时间序列数据的形状,那么选择相关系数。注意如果需要考虑时间序列之间的比较,那么需要创建复杂的时间序列相似性度量。

(a)可能意味着这个变量近似于常量,对于划分数据毫无用处。
(b)这样的变量能帮助解释划分的簇。
(c)这个变量可能是噪声。
(d)其他低SSE的簇可能产生有用的信息,但无论如何这个属性不能帮助解释划分。
(e)排除掉没有什么能力划分簇的属性,而且对所有簇SSE都很高的属性是棘手的,因为它产生了很多噪声。

簇之间的边界是分段的线,连接两个质心,再画它们的垂线,每条垂线都将区域一分为二,每一份都包含一个指定点。

不能。考虑一个有三个簇的数据集,每个簇分别有3,4,5个子簇,一个理想中的按等级划分的簇,根应该有三个分支,然后这三个分支分别有3,4,5分支,但是传统的凝聚层次聚类的算法不能产生这样的结构。

单链:
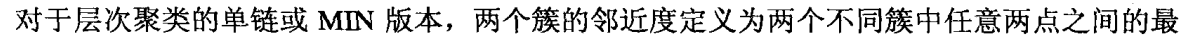


全链:

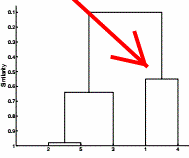


(a)
i.簇为{6,12,18,24,30}、{42,48},SSE分别为360、18,和SSE为378
ii.簇为{6,12,18,24}、{30、42、48},SSE分别为180、168,和SSE为348
(b)是稳定解
(c){6,12,18,24,30}、{42,48}
(d)单链技术
(e)基于邻近的
(f)K均值算法并不擅长发现不同规格的簇,至少当它们没有分离时。
虽然Ward方法基于最小化SSE,但它并不像K均值一样有提炼改善的步骤。类似的,二分K均值没有全局改善的步骤。因此,除非加上改善步骤,Ward方法和二分K均值都产生局部最小值,一般的K均值产生全局最小值。