所有代码以及数据包均来自《Learning Data Mining with Python (Robert Layton 著)》。
使用环境为Jupyter Notebook。
Chapter 1
第一个例子是亲和性分析。数据挖掘中有个常见的应用场景,就是顾客在购买一件商品时,可能会愿意同时购买另一件商品,当收集到足够的数据后,就可以进行亲和性分析。商家可以利用这样的规则提高销售额,比如有名的例子“啤酒与尿布”。
亲和性分析根据样本个体之间的相似度,确定它们关系的亲疏。亲和性分析应用场景如下:
1.向网站用户提供多样化的服务或投放定向广告
2.为了向用户推荐电影与商品,而卖给他们一些与之相关的小玩意
3.根据基因寻找有亲缘关系的人
商品推荐
我们希望从数据集中得到这样的规则:如果一个人买了商品X,那么他很有可能购买商品Y
首先加载数据集,并且通过输出前五行,查看一下数据集到底是什么样子,方便后续处理:
(这里注意路径问题,从属性中复制出来的路径是反斜杠“\”,要改成斜杠“/”,否则会报错)

解释一下数据,每一行代表一条交易数据,每一列代表一种商品,分别是面包、牛奶、奶酪、苹果、香蕉。每个特征只有两个值,1或0,1代表购买了某种商品,0则否之。
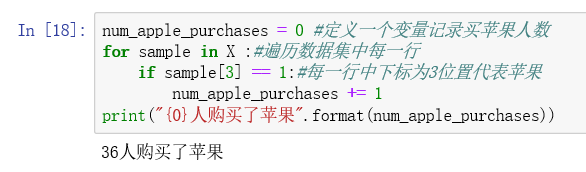
小试牛刀结束,接下来开始正餐。为了计算支持度与置信度,我们要统计 规则应验 和 规则无效 这两种情况,考虑使用字典结构,键为由条件和结论组成的元组,比如(苹果,牛奶)。这里使用collections库中的defaultdict,目的是当我们第一次访问,字典中是没有相应的元组的,用dict会出发KeyError异常,如果一个一个键初始化的话太浪费时间,因此选择用defaultdict,访问不存在的键的时候会返回默认值0(也可以改成其他默认值)。

到目前为止,我们已经得到了所有必要的统计量。

计算结束,我们已经得到支持度字典和置信度字典,接下来定义一个打印函数,任意打印一个规则看下输出结果。

分类问题
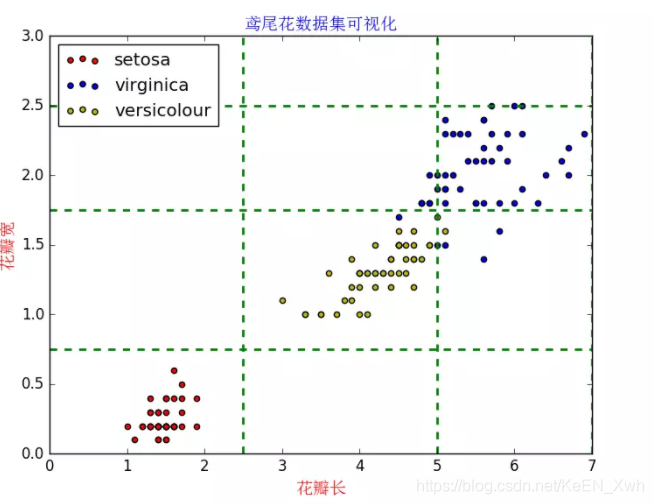
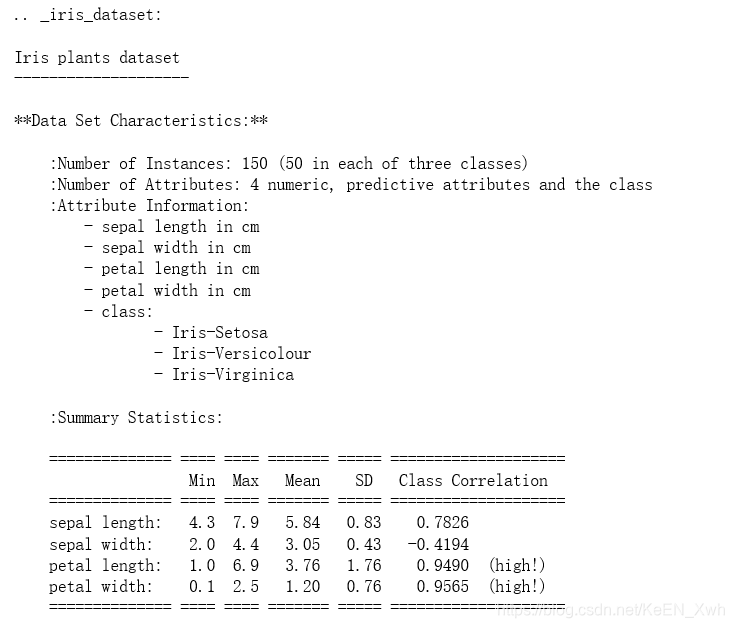
第二个例子是分类问题,目标是根据已知类别的数据集,经过训练得到一个分类模型,再用模型对类别未知的数据进行分类。接下来使用著名的Iris植物分类数据集,这个数据集有150条记录,每条记录给出了四个特征:sepal length 、sepal width、petal length、petal width ,单位均为cm,共有三种类别:Iris Setosa(山鸢尾)、Iris Versicolour(变色鸢尾)、Iris Virginica(维吉尼亚鸢尾)。
scikit-learn库内置了该数据集,可直接导入:
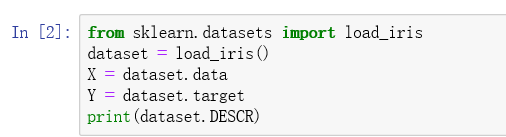
dataset.DESCR命令可以查看数据集,包括特征的说明:

数据集的特征值为连续值,而我们即将使用的算法需要类别型特征值,因此需要离散化。最简单的离散化算法,莫过于确定一个阈值,将低于该阈值的特征值置为0,高于阈值的置为1:

接下来使用OneR算法,就是根据已有数据中,具有相同特征值的个体最可能属于哪个类别进行分类。
第一步,遍历数据集,统计具有给定特征值的个体在各个类别出现的次数,然后找到最大值,就找到了具有给定特征值的个体在哪个类别出现次数最多,接着统计错误率。

该函数实现了什么功能呢?对于某项特征,遍历其每一个特征值,使用上述函数,就能得到预测结果和每个特征值所带来的错误率。
第二步,利用上述函数,计算预测结果和总错误率

最后,将数据集分成两个部分,分别用于训练和测试。(书中代码从sklearn.cross_validation 导入切分函数,会提示不存在该模块,需要从sklearn.model_selection导入)

最终得到结果:

PS:书中代码有错误的地方已修改过来
原代码:
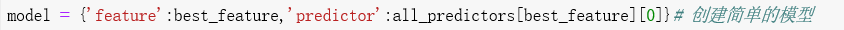
会抛出错误:

索引对于标量变量无效。显然是predictor的索引出了问题,我们可以从每个函数中print打印的结果来看:

all_predictors中元素predictors是一个字典,我们定义model中’predictor’时,取了best_feature位置键值对的第一个元素,也就是一个键,0,一个数当然没有下表索引。
修改后:

即可。
PPS:其实这个算法有很大问题,从预测结果来看,只有0和2类,没有1类,对鸢尾花数据集有了解的人应该知道,长宽最小的是setosa,居中的是versicolour,较大的是virginica,如果用均值作分类标准的话,很明显会丢失versicolour的信息,因为versicolour差不多会分布在均值上下浮动的地方。因此考虑换一个算法,应该会得到更好的效果。