所有代码以及数据包均来自《Learning Data Mining with Python (Robert Layton 著)》。
使用环境为Jupyter Notebook。
Chapter 2
2.1 scikit-learn估计器
为了帮助用户实现大量分类算法,scikit-learn把相关功能封装成所谓的估计器,它包括 fit() 和 predict() 两个函数,也就是训练步和测试步。下面介绍scikit-learn中的近邻算法。
数据集:Ionosphere数据集,可从UCI机器学习数据库下载。该数据集每行有35个值,前34个是天线采集的数据,最后一个是“g”或“b”,表示数据的好坏。
首先,导入numpy和csv库,加载数据集,创建Numpy数据X和Y存放数据集。

接下来,将数据集切分成训练集和测试集,调用sklearn库中的K近邻分类器,并测试算法。

2.2 交叉检验
在先前的实验中,如果碰巧测试集很简单,算法可能表现很好,但运气不好的话可能算法会表现很糟糕,使用交叉检验能够解决一次测试带来的问题。将整个大数据集分为几个部分,对于每一个部分:将当前部分作为测试集,用剩余部分训练算法,记录当前得分。
scikit-learn中提供了交叉检验的方法:

效果比之前的稍稍差了一点,接下来调整参数。
我们测试从1到20的近邻数(n_neighbors)看看哪个效果最好:

这里提一句,%matplotlib inline是一种Python提供的魔法命令,它可以将matplotlib的图表嵌入到Notebook之中。画出来的图是这样的:

2.3 预处理
为了需要,我们先对Ionosphere做些破坏。首先为了不破坏原来的数据集,我们创建一个副本,将X每隔一行就把第二个特征的值除以10,我们直接计算一下准确率:
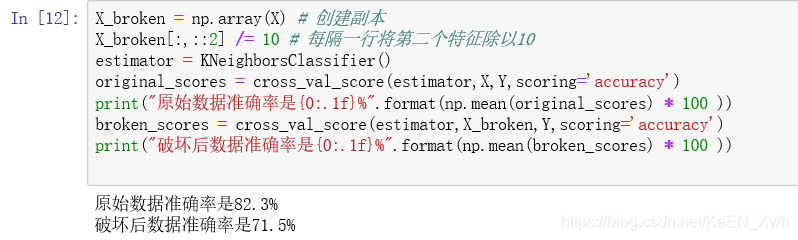
准确率不出意外地降低了。接下来用MinMaxScaler类进行基于特征的规范化,即 x = ( x - xmin ) / ( xmax - xmin ),这样就将每个特征的值规范化为0到1之间。然后在预处理器MinMaxScaler上调用训练和转换函数fit_transform()。

正确率再次提升。
2.4 流水线
随着实验的增加,操作的复杂度也在提高,比如对特征进行各种操作,要跟踪记录这些操作不是很容易,因此引入流水线结构。流水线的输入是一连串的数据挖掘步骤,其中最后一步必须是估计器,前几步是转换器,输入的数据集经过转换器的处理后,输出的结果作为下一步的输入。最后用最后一步的估计器对数据进行分类。
在这里,我们流水线分为两大步:
(1)用MinMaxScaler将特征取值范围规范到0~1;
(2)指定KNeighborsClassifier分类器。
每一步都用(‘名称‘,步骤)来表示。

结果跟之前一样。
在这一章中其实用不用流水线结构其实看不出区别,但后面章节使用更高级的测试方法的时候,设置流水线就很有必要了。