①Deepdive简介
Deepdive是由斯坦福大学InfoLab实验室开发的一个开源知识抽取系统。它通过弱监督学习,从非结构化的文本中抽取结构化的关系数据 。
它是一个具有语言识别能力的信息抽取工具,可用作KBC系统(Knowledge Base Construction)的内核,也可以理解为是一种Automatic KBC工具。
由于基于语法分析器构建,所以Deepdive可通过各类文本规则实现实体间关系的抽取。
Deepdive面向异构、海量数据,所以其中涉及一些增量处理的机制。
PaleoDeepdive是基于Deepdive的一个例子,用于推测人、地点、组织之间的关系。
由于基于语法分析器构建,所以Deepdive可通过各类文本规则实现实体间关系的抽取。
Deepdive面向异构、海量数据,所以其中涉及一些增量处理的机制。
PaleoDeepdive是基于Deepdive的一个例子,用于推测人、地点、组织之间的关系。
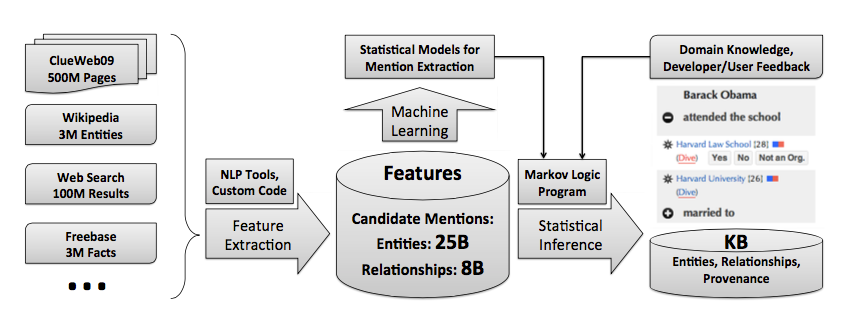
Deepdive的工作机制分为特征抽取、领域知识集成、监督学习、推理四步。
Deepdive的执行过程可以分为:feature extraction,probabilistic knowledge engineering,statistical inference and learning三部分。
Deepdive的执行过程可以分为:feature extraction,probabilistic knowledge engineering,statistical inference and learning三部分。
系统结构图如下(参考http://zhaodaolimeng.com/deepdivexue-xi-bi-ji/):
②环境配置
本次学习的过程依照浙江大学于openkg上发表的CNDeepdive进行文本抽取训练(修改了自然语言处理的model包,使它支持中文,并提供中文tutorial。后续将持续更新一些针对中文的优化)。
笔者通过虚拟机,下载好CNDeepdive后依步骤安装,且按需求配置环境。其中,PostgreSQL的安装和配置方法参考http://www.cnblogs.com/z-sm/archive/2016/07/05/5644165.html,笔者将在实验成功后整理(第二节)。