李宏毅老师详解Batch-Normalization,相见恨晚,留着复习用
学习笔记:

Batch Normalization算法自从15年提出,到现在已经成为深度学习中经常使用的技术,可以说是十分powerful
step1:先从Feature Scaling开始
在没有进行Feature Scaling之前,如果两个输入数据x1,x2的distribution很不均匀的话,导致w2对计算结果的影响比较大(图左),所以训练的时候,横纵方向上需要给与一个不同的training rate,在w1方向需要一个更大的learning rate,w2方向给与一个较小的learning rate,不过这样做的办法却不见得很简单。所以对不同Feature做了normalization之后,使得error surface看起来比较接近正圆的话(图右),就可以使训练容易得多。
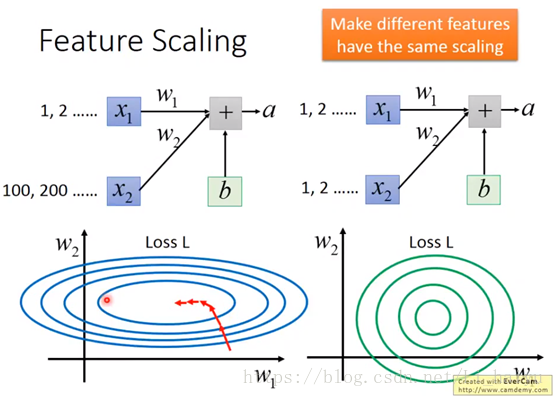
step2:看一典型的Feature Scaling的将具体做法
下面一共有R个data,分别计算每个维度的平均值,标准差,然后再使用图片那个简单的公式进行一下normalization,就可以把所有维度的平均值变为0,方差变为1了。一般来说,进行Feature Scaling之后可以使梯度下降算法更快收敛。
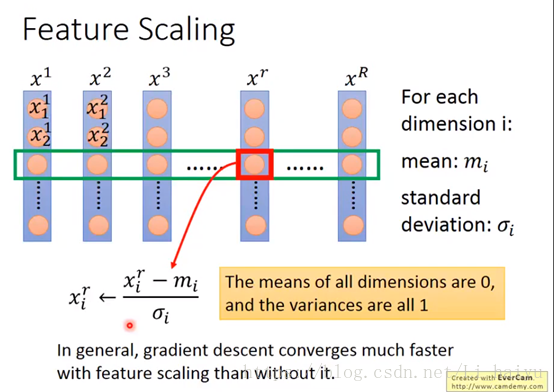
step3:看一下deep learning怎么进行Feature Scaling
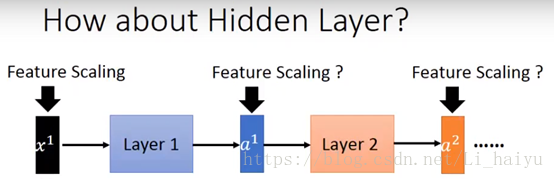
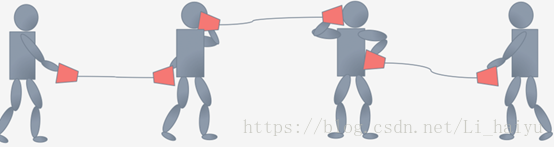
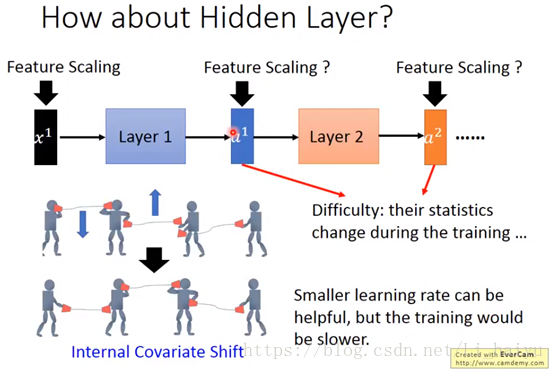
对每一个layer的输入进行Feature Scaling,其实这样对deep learning的训练是很有帮助的,因为它让Internal Covariate Shift下降,那么Internal Covariate Shift是个什么问题呢,可以按照下图来理解,每个小人手上都有一个话筒只有他们将两个话筒对接在一块才能很好地像后面传递信息。
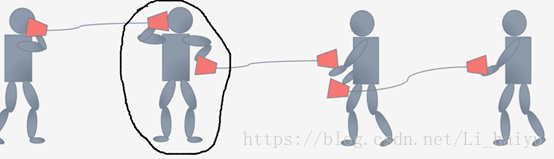
现在我们看一下中间那个小人在训练的时候为了将两个话筒拉到同一个水平高度,它会将左手边的话筒放低一点,同时右手的话筒放低一点,因为是同时两边都变,所以就可能出现了下面的图,最后还是没怼上啊…
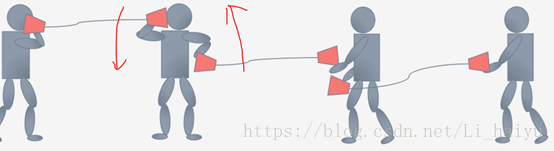
在过去的解决方法是调小learning rate,因为没对上就是因为学习率太大导致的,虽然体调小learning rate可以很好地解决这个问题,但是又会导致训练速度变得很慢。
step4:Internal Covariate Shift问题
那么把刚才的话筒转化为deep learning中就是说,训练过程参数在调整的时候前一个层是后一个层的输入,当前一个层的参数改变之后也会改变后一层的参数。当后面的参数按照前面的参数学好了之后前面的layer就变了,因为前面的layer也是不断在变的。其实输入数据很好normalization,因为输入数据是固定下来的,但是后面层的参数在不断变化根本就不能那么容易算出mean和variance,所以需要一个新的技术叫Batch normalization。
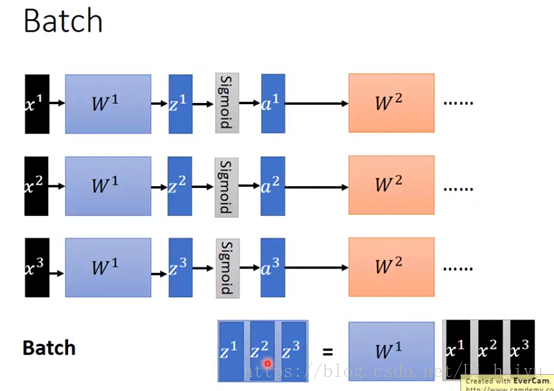
下面简单复习一下Batch,比如下面的batch = 3,计算的时候对batch进行向量化得到matrix,再进行运算。
step5:Batch Normalization实现细节
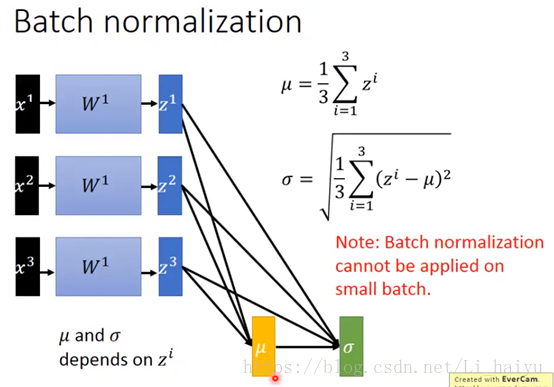
对每层进行Batch Normalization的时候一般都是先进行normalization再传进active function的, 好处就是可以让输入更多地落在active function (比如sigmoid和tanh)的微分比较大的地方也就是零附近。先对一层的输出求平均值μ和方差σ,然后normalization一下,这样就可以得到每个维度的平均值为零,方差为1。
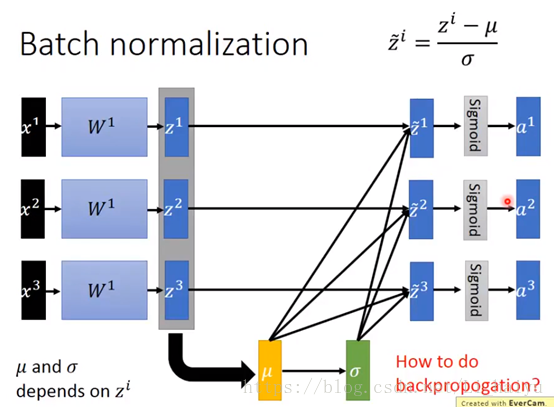
在每层的active function之前都进行一次batch normalization那么做了batch normalization之后的方向传播又是怎么进行的呢?
在方向后传播的时候,一路反向传播回来的时候是会通过σ然后通过μ然后去update Z的,如果在BP过程中没有考虑μ和σ的话是不对的,因为μ和σ是依赖于Z的,改动了Z就相当于改动了μ和σ,所以在training的时候μ和σ是会被考虑进去的。
现在我们把Z normalize成Z ̃ ,然后在active function输入之前还可以增加β和γ参数,这两个参数在training的时候也会被学习到。
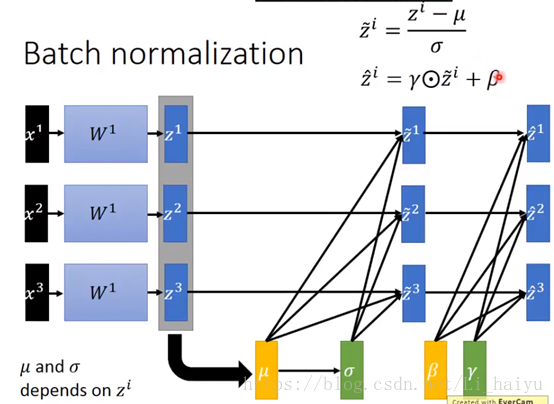
下面再看一下在tseting的时候是怎么做这个batch normalization的?
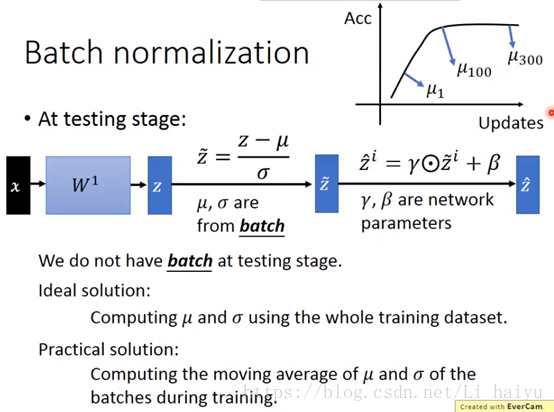
Testing的时候你是不知道怎么计算μ和σ的,因为只有一笔data输入到网络中,不能估计出μ和σ,这里提供两个思路估算testing时候的μ和σ
① Ideal Solution:网络已经训练好了,参数已经固定,所以直接可以在整个training dataset上计算μ和σ,但是有实际中由于training dataset太大或者training dataset没有留下来,一般不采用这个方法。
② Practical Solution:把过去update过程中的μ和σ都算出来,例如途中μ1,μ100,μ300
step6:batch normalization的好处

本人水平有限,如有理解不当之处,希望各位大侠可以不吝斧正,为了加深理解墙裂推荐观看李宏毅老师的视频+论文原文
李宏毅视频讲解链接
YouTube:https://www.youtube.com/watch?v=BZh1ltr5Rkg&t=538s
哔哩哔哩:https://www.bilibili.com/video/av16540598
论文原文:https://arxiv.org/pdf/1502.03167.pdf
参考链接:https://gab41.lab41.org/batch-normalization-what-the-hey-d480039a9e3b