前面已经和大家提到过Shuffle的具体流程和运用场景,也提到过通常shuffle分为两部分:
Map阶段的数据准备和Reduce阶段的数据拷贝处理。
Shuffle Write理解:
提供数据的一端,被称作 Map 端,Map 端每个生成数据的任务称为Mapper;将在map端的Shuffle称之为Shuffle Write。
Shuffle Read理解:
接收数据的一端,被称作 Reduce 端,Reduce 端每个拉取数据的任务称为 Reducer;将在Reduce端的Shuffle称之为Shuffle Read。
spark中rdd由多个partition组成,任务运行作用于partition。spark有两种类型的task:
ShuffleMapTask: 负责rdd之间的transform,map输出也就是Shuffle Write。
ResultTask,:job最后阶段运行的任务,也就是action(一个action会触发生成一个job并提交)操作触发生成的task,用来收集job运行的结果并返回结果到driver端。也就是Shuffle Read。
write和read原理
job依赖关系RDD结构图如下:

最终得到了整个执行过程,如下图所示:

这个执行过程中间就涉及到shuffle 过程;
前一个stage 的 ShuffleMapTask 进行 shuffle write, 把数据存储在 blockManager 上面, 并且把数据位置元信息上报到 driver 的 mapOutTrack 组件中,
而下一个 stage 根据数据位置元信息, 进行 shuffle read, 拉取上个stage 的输出数据。
每个 Task 在 Shuffle Write 操作时,虽然也会产生较大的
磁盘文件,但最后会将所有的临时文件合并 (merge) 成一个磁盘文件,因此每个 Task 就只有一个磁盘文件。
在下一个 Stage 的 Shuffle Read Task 拉取自己数据的时候,只要根据索引拉取每个磁盘文件中的部分数据即可。
Shuffle Write阶段
主要就是在一个stage结束计算之后,为了下一个stage可以执行shuffle类的算子(比如reduceByKey,groupByKey),而将每个task处理的数据按key进行“分区”。
所谓“分区”,就是对相同的key执行hash算法,从而将相同key都写入同一个磁盘文件中,而每一个磁盘文件都只属于reduce端的stage的一个task。在将数据写入磁盘之前,会先将数据写入内存缓冲中,当内存缓冲填满之后,才会溢写到磁盘文件中去。
那么每个执行shuffle write的task,要为下一个stage创建多少个磁盘文件呢?
很简单,下一个stage的task有多少个,当前stage的每个task就要创建多少份磁盘文件。比如下一个stage总共有100个task,那么当前stage的每个task都要创建100份磁盘文件。如果当前stage有50个task,总共有10个Executor,每个Executor执行5个Task,那么每个Executor上总共就要创建500个磁盘文件,所有Executor上会创建5000个磁盘文件。由此可见,未经优化的shuffle write操作所产生的磁盘文件的数量是极其惊人的。
Shuffle Write 操作发生在 ShuffleMapTask的runTask方法 中,代码如下:
override def runTask(context: TaskContext): MapStatus = {
val threadMXBean = ManagementFactory.getThreadMXBean
val deserializeStartTime = System.currentTimeMillis()
val deserializeStartCpuTime = if (threadMXBean.isCurrentThreadCpuTimeSupported) {
threadMXBean.getCurrentThreadCpuTime
} else 0L
val ser = SparkEnv.get.closureSerializer.newInstance()
val (rdd, dep) = ser.deserialize[(RDD[_], ShuffleDependency[_, _, _])](
ByteBuffer.wrap(taskBinary.value), Thread.currentThread.getContextClassLoader)
_executorDeserializeTime = System.currentTimeMillis() - deserializeStartTime
_executorDeserializeCpuTime = if (threadMXBean.isCurrentThreadCpuTimeSupported) {
threadMXBean.getCurrentThreadCpuTime - deserializeStartCpuTime
} else 0L
var writer: ShuffleWriter[Any, Any] = null
try {
val manager = SparkEnv.get.shuffleManager
writer = manager.getWriter[Any, Any](dep.shuffleHandle, partitionId, context)
writer.write(rdd.iterator(partition, context).asInstanceOf[Iterator[_ <: Product2[Any, Any]]])
writer.stop(success = true).get
} catch {
case e: Exception =>
try {
if (writer != null) {
writer.stop(success = false)
}
} catch {
case e: Exception =>
log.debug("Could not stop writer", e)
}
throw e
}
}调用val (rdd, dep) = ser.deserialize(…)获取任务运行的rdd和shuffle dep,这是在由DAGScheduler序列化然后提交到当前任务运行的executor上的。
调用writer = manager.getWriter[Any, Any](dep.shuffleHandle, partitionId, context) 获得shuffle writer,调用writer.write(rdd.iterator)写出map output。rdd.iterator在迭代过程中,会往上游一直追溯当前rdd依赖的rdd,然后从上至下调用rdd.compute()完成数据计算并返回iterator迭代转换计算的结果。
rdd.iterator迭代方法如下:
final def iterator(split: Partition,context: TaskContext): Iterator[T]= {
if (storageLevel !=StorageLeve1.NONE) {
getorcompute(split, context)
} else {
computeorReadcheckpoint(split, context)
}
}因为 Spark 以 Shuffle 发生与否来划分 Stage,所以该 Stage 的 final RDD 每输出一个 record 就将其分区并持久化。
ShuffleWriter 有三种实现:
- BypassMergeSortShuffleWriter
- UnsafeShuffleWriter
- SortShuffleWriter
如下图所示:

下面是分析如何判断是使用哪种ShuffleWriter,如下图所示:

上面是使用哪种 writer 的判断依据, 是否开启 mapSideCombine 这个判断,是因为有些算子会在 map 端先进行一次 combine, 减少传输数据。 因为 BypassMergeSortShuffleWriter 会临时输出Reducer个(分区数目)小文件,所以分区数必须要小于一个阀值,默认是小于200。
UnsafeShuffleWriter需要Serializer支持relocation,Serializer支持relocation:原始数据首先被序列化处理,并且再也不需要反序列,在其对应的元数据被排序后,需要Serializer支持relocation,在指定位置读取对应数据。
BypassMergeSortShuffleWriter 实现细节
BypassMergeSortShuffleWriter和Hash Shuffle中的HashShuffleWriter实现基本一致, 唯一的区别在于,map端的多个输出文件会被汇总为一个文件。 所有分区的数据会合并为同一个文件,会生成一个索引文件,是为了索引到每个分区的起始地址,可以随机 access 某个partition的所有数据。
但是需要注意的是,这种方式不宜有太多分区,因为过程中会并发打开所有分区对应的临时文件,会对文件系统造成很大的压力。
具体实现步骤:
就是给每个分区分配一个临时文件,对每个 record的key 使用分区器(模式是hash,如果用户自定义就使用自定义的分区器)找到对应分区的输出文件句柄,直接写入文件,没有在内存中使用 buffer。 最后copyStream方法把所有的临时分区文件拷贝到最终的输出文件中,并且记录每个分区的文件起始写入位置,把这些位置数据写入索引文件中。
SortShuffleWriter 实现细节
我们可以先考虑一个问题,假如我有 100亿条数据,但是我们的内存只有1M,但是我们磁盘很大, 我们现在要对这100亿条数据进行排序,是没法把所有的数据一次性的load进行内存进行排序的,这就涉及到一个外部排序的问题,我们的1M内存只能装进1亿条数据,每次都只能对这 1亿条数据进行排序,排好序后输出到磁盘,总共输出100个文件,最后怎么把这100个文件进行merge成一个全局有序的大文件。
我们可以每个文件(有序的)都取一部分头部数据最为一个 buffer, 并且把这 100个 buffer放在一个堆里面,进行堆排序,比较方式就是对所有堆元素(buffer)的head元素进行比较大小, 然后不断的把每个堆顶的 buffer 的head 元素 pop 出来输出到最终文件中, 然后继续堆排序,继续输出。如果哪个buffer 空了,就去对应的文件中继续补充一部分数据。最终就得到一个全局有序的大文件。
如果你能想通我上面举的例子,就差不多搞清楚sortshufflewirter的实现原理了,因为解决的是同一个问题。
具体实现步骤:
- 使用 PartitionedAppendOnlyMap 或者 PartitionedPairBuffer 在内存中进行排序, 排序的 K 是(partitionId, hash(key)) 这样一个元组。
- 如果超过内存 limit, 我 spill 到一个文件中,这个文件中元素也是有序的,首先是按照 partitionId的排序,如果 partitionId 相同, 再根据 hash(key)进行比较排序
- 如果需要输出全局有序的文件的时候,就需要对之前所有的输出文件 和 当前内存中的数据结构中的数据进行 merge sort, 进行全局排序
不同的地方在于,需要对 Key 相同的元素进行 aggregation, 就是使用定义的 func 进行聚合, 比如你的算子是 reduceByKey(+), 这个func 就是加法运算, 如果两个key 相同, 就会先找到所有相同的key 进行 reduce(+) 操作,算出一个总结果 Result,然后输出数据(K,Result)元素。
SortShuffleWriter 中使用 ExternalSorter 来对内存中的数据进行排序,ExternalSorter内部维护了两个集合PartitionedAppendOnlyMap、PartitionedPairBuffer, 两者都是使用了 hash table 数据结构, 如果需要进行 aggregation, 就使用 PartitionedAppendOnlyMap(支持 lookup 某个Key,如果之前存储过相同key的K-V 元素,就需要进行 aggregation,然后再存入aggregation后的 K-V), 否则使用 PartitionedPairBuffer(只进行添K-V 元素)
UnsafeShuffleWriter 实现细节
UnsafeShuffleWriter 里面维护着一个 ShuffleExternalSorter, 用来做外部排序, 外部排序就是要先部分排序数据并把数据输出到磁盘,然后最后再进行merge 全局排序, 既然这里也是外部排序,跟 SortShuffleWriter 有什么区别呢?
这里只根据 record 的 partition id 先在内存 ShuffleInMemorySorter 中进行排序, 排好序的数据经过序列化压缩输出到换一个临时文件的一段,并且记录每个分区段的seek位置,方便后续可以单独读取每个分区的数据,读取流经过解压反序列化,就可以正常读取了。
整个过程就是不断地在 ShuffleInMemorySorter 插入数据,如果没有内存就申请内存,如果申请不到内存就 spill 到文件中,最终合并成一个 依据 partition id 全局有序 的大文件。
SortShuffleWriter 和 UnsafeShuffleWriter 对比:

使用 UnsafeShuffleWriter 的条件:
- 没有指定 aggregation 或者key排序, 因为 key 没有编码到排序指针中,所以只有 partition 级别的排序
- 原始数据首先被序列化处理,并且再也不需要反序列,在其对应的元数据被排序后,需要Serializer支持relocation,在指定位置读取对应数据。 KryoSerializer 和 spark sql 自定义的序列化器 支持这个特性。
- 分区数目必须小于 16777216 ,因为 partition number 使用24bit 表示的。
- 因为每个分区使用 27 位来表示 record offset, 所以一个 record 不能大于这个值。
三种Writer分别对应不同的 Handle:
- BypassMergeSortShuffleWriter -> BypassMergeSortShuffleHandle
- UnsafeShuffleWriter -> SerializedShuffleHandle
- SortShuffleWriter -> BaseShuffleHandle
根 据 ShuffleHandle 来决定 使 用 不 同 的 ShuffleWrite , 在 构 建
ShuffleDependency 时会构建 ShuffleHandle。创建时在 registerShuffle 方法中,有
着对 ShuffleHandle 使用的条件约束,如下图所示:

如何选择ShuffleWrite条件
- 如果分区小于 spark.shuffle.sort.bypassMergeThreshold(默认 200),且
map 端没有聚合操作,使用 BypassMergeSortShuffleHandle,否则进入下一个条件。 - 如果 map 端没有聚合操作,且 Serializer 支持重定位(即使用 KryoSerializer),且分区数目小于 16777216(最大分区号)时使用SerializedShuffleHandle。否则进入下一条件。如下图所示:

- 以上条件都不满足时使用 BaseShuffleHandle。
对应的 ShuffleWrite 是SortShuffleWriter,这种形式的支持 map 端聚合操作,同时支持排序。这种是最通用的 Writer。HashShuffleWriter 的主要弊端是产生的临时文件太多,那么 Sort ShuffleWriter 使相同的ShuffleMapTask 公用一个输出文件,然后创建一个索引文件对这个文件进行索引,如下图所示:

下面是基于排序的 Shuffle write操作,如下图所示:
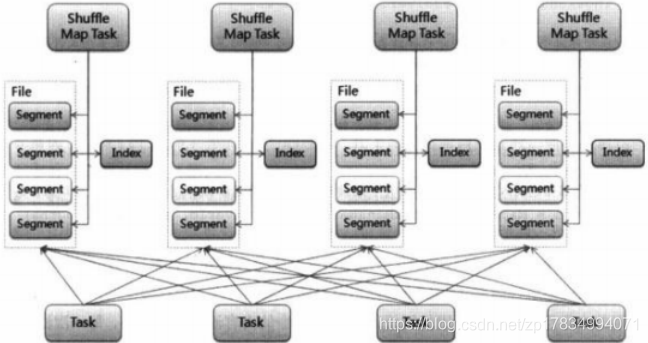
BypassMergeSortShuffleWriter工作原理
BypassMergeSortShuffleWriter, 这个writer会根据reduce的个数n(reduceByKey中指定的参数,有partitioner决定)创建n个临时文件,然后计算iterator每一个key的hash,放到对应的临时文件中,最后合并这些临时文件成一个文件;
同时还创建一个索引文件来记录每一个临时文件在合并后的文件中偏移。当reducer取数据时根据reducer partitionid就能以及索引文件就能找到对应的数据块。
BypassMergeSortShuffleWriter#write的执行过程:
-
根据reducer的个数(partitioner决定)n 创建n个DiskBlockObjectWriter,每一个创建一个临时文件,临时文件命名规则为temp_shuffle_uuid,也就是每一个临时文件放的就是下游一个reduce的输入数据。
-
迭代访问输入的数据记录,调用partitioner.getPartition(key)计算出记录的应该落在哪一个reducer拥有的partition,然后索引到对应的DiskBlockObjectWriter对象,写出key,value
-
创建一个名为shuffle_shuffleid_mapid_0.uuid这样的临时且绝对不会重复的文件,然后将1中生成的所有临时文件写入到这个文件中,写出的顺序是partitionid从小到大开始的(这里之所以使用uuid创建文件,主要是不使用uuid的话可能有另外一个任务也写出过相同的文件,文件名中的0本来应该是reduceid,但是由于合并到只剩一个文件,就用0就行了)。
-
写出索引文件,索引文件名为shuffle_shuffleid_mapid_0.index.uuid(使用uuid和3中的原因是一样的)。由于map的输出数据被合并到一个文件中,reducer在读取数据时需要根据索引文件快速定位到应该读取的数据在文件中的偏移和大小。
-
索引文件只顺序写出partition_0 ~ partition_n的偏移的值
-
还需要将3中shuffle_shuffleid_mapid_0.uuid重命名为”shuffle_shuffleid_mapid_0", 过程是验证一下是不是已经存在这么一个文件以及文件的长度是否等于 1 中所有临时文件相加的大小,不是的话就重命名索引文件和数据文件(去掉uuid)。否则的话表示先前已经有一个任务成功写出了数据,直接删掉临时索引和数据文件,然后返回。
SortShuffleWriter工作原理
SortShuffleWriter, 会在map做key的aggregate操作,(key,value)会先在保存在内存里,并按照用户自定义的aggregator做key的聚合操作,并在达到一定的内存大小后,对内存中已有的记录按(partition,key)做排序,然后保存到磁盘上的临时文件。最终对生成的文件再做一次merge操作。
Shuffle Read阶段
shuffle read,通常就是一个stage刚开始时要做的事情。此时该stage的每一个task就需要将上一个stage的计算结果中的所有相同key,从各个节点上通过网络都拉取到自己所在的节点上,然后进行key的聚合或连接等操作。由于shuffle write的过程中,task给Reduce端的stage的每个task都创建了一个磁盘文件,因此shuffle read的过程中,每个task只要从上游stage的所有task所在节点上,拉取属于自己的那一个磁盘文件即可。
shuffle read的拉取过程是一边拉取一边进行聚合的。每个shuffle read task都会有一个自己的buffer缓冲,每次都只能拉取与buffer缓冲相同大小的数据,然后通过内存中的一个Map进行聚合等操作。聚合完一批数据后,再拉取下一批数据,并放到buffer缓冲中进行聚合操作。以此类推,直到最后将所有数据到拉取完,并得到最终的结果。
Shuffle Read 操作发生在 ShuffledRDD#compute 方法中,意味着 Shuffle Read
可以发生 ShuffleMapTask 和 ResultTask 两种任务中。代码如下:
override def compute(split: Partition,context: TaskContext):Iterator[(K,C)]= {
val dep = dependencies.head.asInstanceOf[ShuffleDependency[K,v,c]]
SparkEnv.get.shuffleManager.getReader(dep.shuffleHandLe,split.index,split.index + 1,context
.read()
.asInstanceof[Iterator[(K,c)]]
}
每个 Stage 的上边界,要么需要从外部存储读取数据,要么需要读取上一个
Stage 的输出,而下边界要么需要写入本地文件系统(Shuffle),以供下一个 Stage读取,要么是最后 一个 Stage,需要输出结果。
除了需要从外部存储读取数据和 RDD 已经持久化(Cache、Checkpoint),一般 Task 都是从 ShuffledRDD 的 Shuffle Read 开始的。
ShuffleManager#getReader 实例化一个 BlockStoreShuffleReader。代码如下:
override def getReader[K,c](
handle: shuffleHandle,
startPartition: Int,
endPartition: Int,
context: TaskContext): ShuffleReader[K,c]= {
new BlockstoreShuff1eReader(
handle.asInstanceOf[BaseShuffleHandle[K,_,c]],startPartition,endPartition,context)
}BlockStoreShuffleReader#read 首先实例化了 ShuffleBlockFetcherIterator 对象,如下图所示:
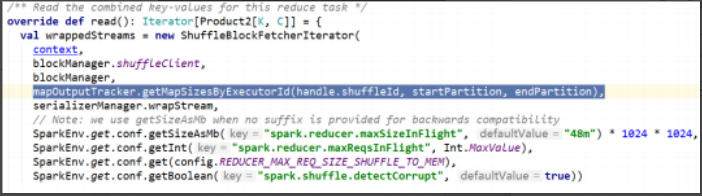
图中“mapOutputTracker.getMapSizesByExecutorId”返回存储数据位置的元
数据;
- blockManager.shuffleClient, 是NettyBlockTranseferService的实例,用来传输datablock。
- mapOutputTracker.getXXX返回executorId到BlockId的映射,表示当前partition需要读取的上游的的block的blockid,以及blockid所属的executor。
- serializerManager.wrapStream, 反序列化流,上有数据被包装成输入流之后,再使用反序列化流包装之后读出对象。
具体实现代码如下:
override def read(): Iterator[Product2[K, C]] = {
val wrappedStreams = new ShuffleBlockFetcherIterator(
context,
blockManager.shuffleClient,
blockManager,
mapOutputTracker.getMapSizesByExecutorId(handle.shuffleId, startPartition, endPartition),
serializerManager.wrapStream,
// Note: we use getSizeAsMb when no suffix is provided for backwards compatibility
SparkEnv.get.conf.getSizeAsMb("spark.reducer.maxSizeInFlight", "48m") * 1024 * 1024,
SparkEnv.get.conf.getInt("spark.reducer.maxReqsInFlight", Int.MaxValue),
SparkEnv.get.conf.getBoolean("spark.shuffle.detectCorrupt", true))
val serializerInstance = dep.serializer.newInstance()
// Create a key/value iterator for each stream
val recordIter = wrappedStreams.flatMap { case (blockId, wrappedStream) =>
// Note: the asKeyValueIterator below wraps a key/value iterator inside of a
// NextIterator. The NextIterator makes sure that close() is called on the
// underlying InputStream when all records have been read.
serializerInstance.deserializeStream(wrappedStream).asKeyValueIterator
}
// Update the context task metrics for each record read.
val readMetrics = context.taskMetrics.createTempShuffleReadMetrics()
val metricIter = CompletionIterator[(Any, Any), Iterator[(Any, Any)]](
recordIter.map { record =>
readMetrics.incRecordsRead(1)
record
},
context.taskMetrics().mergeShuffleReadMetrics())
// An interruptible iterator must be used here in order to support task cancellation
val interruptibleIter = new InterruptibleIterator[(Any, Any)](context, metricIter)
val aggregatedIter: Iterator[Product2[K, C]] = if (dep.aggregator.isDefined) {
if (dep.mapSideCombine) {
// We are reading values that are already combined
val combinedKeyValuesIterator = interruptibleIter.asInstanceOf[Iterator[(K, C)]]
dep.aggregator.get.combineCombinersByKey(combinedKeyValuesIterator, context)
} else {
// We don't know the value type, but also don't care -- the dependency *should*
// have made sure its compatible w/ this aggregator, which will convert the value
// type to the combined type C
val keyValuesIterator = interruptibleIter.asInstanceOf[Iterator[(K, Nothing)]]
dep.aggregator.get.combineValuesByKey(keyValuesIterator, context)
}
} else {
require(!dep.mapSideCombine, "Map-side combine without Aggregator specified!")
interruptibleIter.asInstanceOf[Iterator[Product2[K, C]]]
}
// Sort the output if there is a sort ordering defined.
dep.keyOrdering match {
case Some(keyOrd: Ordering[K]) =>
// Create an ExternalSorter to sort the data. Note that if spark.shuffle.spill is disabled,
// the ExternalSorter won't spill to disk.
val sorter =
new ExternalSorter[K, C, C](context, ordering = Some(keyOrd), serializer = dep.serializer)
sorter.insertAll(aggregatedIter)
context.taskMetrics().incMemoryBytesSpilled(sorter.memoryBytesSpilled)
context.taskMetrics().incDiskBytesSpilled(sorter.diskBytesSpilled)
context.taskMetrics().incPeakExecutionMemory(sorter.peakMemoryUsedBytes)
CompletionIterator[Product2[K, C], Iterator[Product2[K, C]]](sorter.iterator, sorter.stop())
case None =>
aggregatedIter
}
}
}
类的定义如下图所示:

blocksByAddress 指出了数据是来自于哪个节点的哪些 block,并且 block 的数据大小是多少。接下来初始化代码如下图所示 :

从代码可以看出:
- 首先区分是本地还是远程 blocks,返回远程请求 FetchRequest 加入到fetchRequests 队列中。
- 从 fetchRequests 取出远程请求,并使用 sendRequest 方法发送请求,获取远程数据。
- 获取本地 blocks。
- splitLocalRemoteBlocks, 根据executorId区分出在本地的的block和远程的block,然后构建出FetchRequest(每一个request可能包含多个block,但是block都是属于一个executor)。
- fetchUpToMaxBytes和fetchLocalBlocks,从本地或者远程datablock,数据放在buffer中,包装好buffer放到其成员results(一个阻塞队列)中。
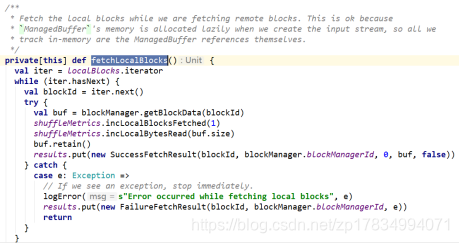
本地读取
fetchLocalBlocks()负责本地 blocks 的获取,在上图的splitLocalRemoteBlocks中,已经将本地的 blocks 列表存入了localBlocks。如下图所示:
远程读取
调用 fetchUpToMaxBytes()来获取远程数据。如下图所示:
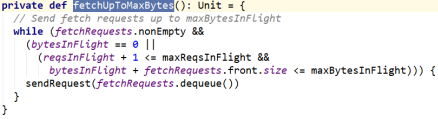
从 fetchRequests 中取出 FetchRequest,并调用了 sendRequest()方法。
sendRequest()向远程节点发起读取 block 的请求。
关键代码如下图所示:


解析Shuffle Read中核心代码迭代器
1. ShuffleBlockFetcherIterator
其next方法返回类型为(BlockId, InputStream)。当前reduce分区需要从上游map 输出数据中fetch多个block。这个迭代器负责从上游fetch到blockid中的数据(由于write阶段数据是合并到一个blockid文件中,所以数据是其中一段)。
然后将从数据创建InputStream,并把blockid以及创建的stream返回。显然如果上游有三个partition,每个partition的输出数据文件中有一段是当前的输入,那这个迭代器三次就结束了。
2.val recordIter = wrappedStreams.flatMap { …}
在1 中迭代器产生(BlockId,InputStream),但是作为read 而言spark最终需要的读出一个个(key,value),在 1 的iterator上做一次flatMap将(BlockId,InputStream)转换成(key,value)。
先是调用serializerInstance.deserializeStream(wrappedStream)使用自定义的序列化方式包装一下1中的输入流,这样就能正常读出反序列化后的对象;然后调用asKeyValueIterator转换成NextIterator,其next方法就反序列化后的流中读出(key,value)。
3.val metricIter = CompletionIterator…
这个迭代器包装2中迭代器,next方法也只是包装了2中的迭代器,但是多了一个度量的功能,统计读入多少(key,value)。
4.InterruptibleIterator
这个迭代器使得任务取消是优雅的停止读入数据。
5.val aggregatedIter: Iterator[Product2[K, C]] = if …
从前面shuffle write的过程可以知道,即便每一个分区任务写出时做了value的聚合,在reducer端的任务里,由于有多个分区的数据,因此依然还要需要对每个分区里的相同的key做value的聚合。
这个iterator就是完成这个功能。
首先,会从4 中迭代器中一个个读入数据,缓存在内存中(map缓存,因为要做聚合),并且在必要时spill到磁盘(spill之前会按key排序)。这个过程和shuffle write中在map端聚合时操作差不多。
然后, 假设上一部产生了多个spill文件,那么每一个spill文件必然时按key排序的,再对这个spill文件做归并,归并时key相同的进行聚合。
最后, 迭代器的next返回key以及聚合后的value。
6.dep.keyOrdering match {…
在5中相同key的所有value都按照用户自定义的聚合方法聚合在一起了,但是iterator输出是按key的hash值排序输出的,用户可能自定义了自己的排序方法。
这里又使用了ExternalSorter,按照自定义排序方式排序(根据前面External介绍,可能又会有spill磁盘的操作。。。),返回的iterator按照用户自定义排序返回聚合后的key。
作为iterator,它的next方法每次从results中取出一个,从数据buffer中创建出InputStream,使用wrapStream包装InputStream返回。
至此shuffle read算是完成。