人工神经网络相关数学推导和思考
今天凌晨今天凌晨的欧冠的八分之一决赛中,巴萨依靠朗格莱,梅西,苏亚雷斯三人的进球顺利挺进八强!梅老板的1V4更是让人直呼:爷青回!那么问题来了,如何根据外貌分辨进球的三人?如何让机器人梅小西学会过人的?第一个问题,我们可以根据三人的特点:老板个子矮,苏牙牙齿又白又大,朗哥头发短,等等等等,建立特征向量:X
=[身高,牙齿,头发长度,……],对很多很多张三人的照片进行特征计算,并打上对应的标明谁是谁的标签,让计算机进行学习,并进行分类。第二个问题,就只能让小西自己去通过交互获得经验了。每过人成功一次,他的收益函数就变大,失败了,就减小。梅小西通过基本功训练,学会了很多过人动作,又与很多人进行1v1对抗,通过比较对不同的人采用不同的动作,通过对比收益函数,他就能学会对不同的对手如何成功过人了。比如对马塞洛,就左脚外拨,对博阿滕,就内扣,哈哈哈。第一类问题属于监督学习,而第二类属于强化学习,以下内容是关于监督学习的,强化学习是真不会555.
一、分类问题基础(高中数学水平)
1.线性分类问题
我们先以最简单的二维空间上的二分类问题为例,假设两类待分类样本分别用圆圈和叉表示,是否线性可分的定义即为:“能不能找到一条直线,将该二维空间中的圆圈和叉完全分开。”话不多说,直接上图。
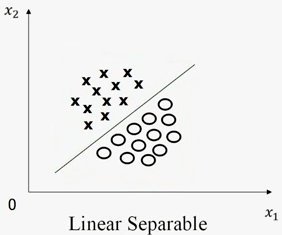 图1-1
图1-1
在上图中,两类样本点可用一条直线完全分开,因此在二维空间内,两类样本点线性可分。
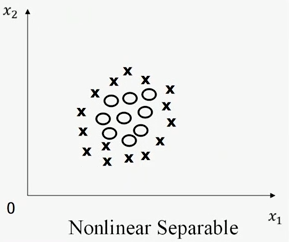 图1-2
图1-2
相比之下,上图1-2中找不到一条直线将两类样本点完全分开,因此描述为线性不可分。
同样的道理,以二分类为例,可以这样描述三维空间内的线性可分与不可分:能不能找到一个平面,将三维空间内的两类样本点集完全分开 。如下图所示:
 图1-3
图1-3
线性可分
 图1-4
图1-4
线性不可分
以此类推,在多维空间中线性可分的定义衍生为:在该空间中是否可以找到一个超平面将两类样本点完全分开。人脑对三位以上的空间缺乏想象力,因此需要借助数学表述来确定。
我们在高中二年级的时候就学过平面几何的线性规划问题,以此为例,假设二维空间的两个维度分别用x1和x2表述,再加上偏置b,一条直线可以表述为ax1+bx2+c=0.而平面上方的区域可以表示为ax1+bx2+c>0,下方则可表示为ax1+bx2+c<0.对于特征空间内的某个待分类向量,取权重向量W=[a,b],待分类向量x=[x1,x2]T,标签记为y,则可以计算Wx=y来确定该向量的类别。在上图1-1所示的空间中,我们将×的标签定为y1,而将o的标签定为y2,若能找到一条直线的方程为Wx=0对于所有的×样本,计算出的y1>0而对于所有的o样本,计算出的y2<0,那么该直线Wx=0可以将两类向量完全分开。
假设我们有N个训练样本X{1,2,…,N}他们各自的标签y{1,2,…,N},线性可分问题可以描述为存在向量W和常数b使得对于i=1,2,…,N,有yi(WXi+b)>0.
对于三维以及以上维度的空间,上述概念完全适用,只是待分类向量和权重向量变成了多维而已。
定义过线性可分以后,对于实际n维空间二分类问题,我们的主要任务则是寻找n+1维度的向量(Wn,b)对于N个训练样本X{1,2,…,N}他们各自的标签y{1,2,…,N},满足yi(WXi+b)>0罢了.
2.非线性分类问题
生活中绝大多数情况,我们遇到的都是非线性可分问题,诸如在一幅遥感图像中,我们要根据不同的地物,对该图像进行简单的区域划分。对于以上问题,可以通过特征计算,得出各个类别地物的N维特征向量X,例如,草地为X{1,N},水域为X{2,N},森林为X{3,N}.显然,找不到一条直线将任意两种地物分开,更别说三类以及以上的地物分开了。线性规划这时候又要派上用场了!
 图1-5
图1-5
图中的三条直线可表示为:
l1:w11x1+w12x2+b1=0
l2:w21x1+w22x2+b2=0
l3:w31x1+w32x2+b3=0
三角形区域C1则可以表示为:
而对于多分类问题,我们则可以构造多条直线,将多个区域进行表述,根据以上方法,对每个区域的向量进行上述描述计算,从而判定他们的类别。
对于非线性可分问题,我们则可以利用多条直线进行逼近拟合。如下图中的圆形,我们可以用正n边形进行拟合与逼近,而逼近的程度n是可以根据实际需求,受我们控制的。然而正n边形的每一条边都可以线性表述,因此,我们就可以利用线性分类的方法解决它了。
 图1-6
图1-6
图中的圆圈和叉,用其他的正多边形分开不也是可以的吗?
二、MP神经元模型
上世纪40年代,一些科学家根据神经元的仿生学模型建立了其对应的简洁数学表达。即,将神经元树突所接收到的一串刺激表示为一个多维向量X=[x1,x2,…,xn]T,各个树突的对于外界刺激的传递权重不同,对应了权重向量W=[w1,w2,…,wn]T,同时传递到细胞核中是一个加权求和并作非线性变换的过程,完成该变换后,传递给与下一个神经元连接的突触,输出信息对应计算结果y.
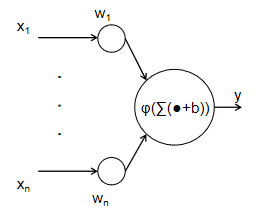 图2-1
图2-1
其实,与其说这是一个仿生学模型,不如把它理解成多元函数y=f(x1,…,xn)的一阶麦克劳林展开近似,权重向量的每一个分量其实可以理解为函数y对于每一个自变量xi在原点的偏导数的值,而偏置b则可以理解为余项。
三、感知器算法
搞清楚了分类算法的原始数学描述,这就要回到这个任务的最关键环节了,什么样的W和什么样的b能使我们圆满完成分类任务呢?找到了还不错的W和b,又如何调整他们,使得分类算法更具有鲁棒性呢?下图中,L1的效果是优于L2的,不是吗?
 图3-1
图3-1
回顾我们的任务:
对于实际n维空间二分类问题,我们的主要任务则是寻找n+1维度的向量(Wn,b)对于N个训练样本X{1,2,…,N}他们各自的标签y{1,2,…,N},满足yi(WXi+b)>0。
如果我们找到的W和b不能满足上面的情况,就该对他们进行调整了。而不满足的情况无非就两种:
(1)yi=+1,WXi+b<0
(2)yi=-1,WXi+b>0
显然对于(1)的情况,计算结果大了,我们的任务是,调整W和b,使得计算结果变大,对于(2)则是要调整W和b,使得计算结果变小。
感知器算法的调整可以表示为:
对于(1)的情况:W=(WT+X)T,b=b+1;
而对于(2)的情况:W=(WT-X)T,b=b-1;
这里为了表示方便,我们在此将W定义为列向量,即W=WT.
对于(1)我们有如下改动:
New=(W+X)TX+b+1
=WTX+XTX+b+1
=WTX+b+||X||+1
=Old+||X||+1
而对于(2)的情况,我们则有New=Old-||X||-1.这就完成了对W和b的调大调小,使得模型更能适应训练样本,当对每一个样本进行以上训练,并满足yi(WTXi+b)>0时,模型就获得平衡了。
在发明感知器算法时,Rossenblatt老师就严格的证明了,只要数据集线性可分,那么模型一定可以获得平衡。(在此省略证明过程,因为我也不会)
感知器算法在处理线性可分问题上,有一些重要的优点,诸如需要调整的参数数量少,收敛速度较快等等优点,但是,实际生活中的绝大多数常见的分类问题都是线性不可分的,所以,我们需要在古老的感知器算法的基础上对其做出必要的调整。
四、非线性函数带来的改变
回到图2-1,我们发现MP模型对细胞核的作用概括为一个非线性函数的映射,感知器算法的基础上,我们需要解决的问题的问题则是模型对非线性可分情况的模拟。先来构造一个简单的神经网络吧!
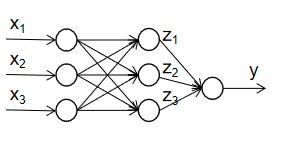 图4-1
图4-1
上述三层神经网络的输出为:
y=w1z1+w2z2+w3z3
=w1
(w11x1+w12x2+w13x3+b1)+w2
(w21x1+w22x2+w23x3+b2)+w3
(w31x1+w32x2+w33x3+b3)
试想一下,如果把
(x)改为线性函数ax+b的形式,那么这个三层的神经网络是不是也就跟感知机模型差不多了呢?试想一下以上模型中,除了待估计参数w和b以外,最重要的待确定量是什么呢?对了,就是那个非线性函数
(x)了。
在前面的内容中我们讲到,二分类的方法可以根据符号来确定,标签也是要么+1要么-1,所以为什么不想到《信号与系统》里面学过的单位阶跃函数u(x)呢?
在此我们构造一个复杂一点的多分类问题吧!
 图4-2
图4-2
如上图,样本空间被分为三类,在左边的三角形里面,则被定为C1,在右边的三角形里则被定为C2,都不在则被定为C3.
L11:w11x1+w12x2+b11=0
L12:w21x1+w22x2+b12=0
L13:w31x1+w32x2+b13=0
L21:w41x1+w42x2+b21=0
L22:w51x1+w52x2+b22=0
L23:w61x1+w62x2+b23=0
规则:若为C1类,y=1;若为C2类,y=2;若为C3类,y=0.(类别编号y是随意设定的)
函数选取:
(x)=u(x)
其实解决这个问题,也只需要高中数学知识就可以啦!
三角形区域C1则可以表示为:
然而,我们可以通过调整每项w和b的符号,使得向量x=[x1,x2]T满足:
所以,回顾神经元模型的数学表达这三个方程所对应的神经元输出分别为
u(w11x1+w12x2+b11)=1
u(w21x1+w22x2+b12)=1
u(w31x1+w32x2+b13)=1;
做到这一步,我们就要在余下层神经元的偏置和权重上下功夫了!
 图4-3
图4-3
如上图所示,输入层和第一个隐藏层之间是FC层,而余下几层非全连接。
上面三个神经元分别代表构成三角形C1的三条直线的方程,每个神经元与输入层神经元的连接权值分别为该方程中系数向量w的两个分量的值。若待分类向量在三角形C1内部,则上面三个神经元的输出全为1(因为计算结果大于0,则u(.)输出1),下面三个神经元的输出至少有一个为0.到了下一层神经元,由于加上了偏置-2.5,因此只有上面那个神经元会输出1(因为3-2.5>0,阶跃函数输出1)下面的神经元则输出0,经过下一层的连接权值相乘,结果输出1。同理,在C2中则输出2,两个都不在,则输出0.
其实只要高中数学基础就可以搭建一个用于二维非线性多分类神经网络啦,所以好好学习数学还是很有用的。
每一层多个神经网络的线性结构,加上层与层之间的非线性结构,就可以模拟几乎任意的决策函数了。线性函数和阶跃函数都很平凡,可他&她们在一起了以后,却组成了一个幸福而强大的分类大家庭!(扯远了23333)
五、梯度下降&后向传播算法
有人就会问了,实际分类问题你咋知道决策函数长啥样?的确,在实际问题中,我们只知道一堆训练数据和他们的标签啊。所以现实的做法其实是:先估计网络的结构并初始化参数,然后将训练数据处理好并输入这个网络,再根据训练情况调整待估计参数和神经网络的结构。
我们进行分类训练的主要任务,便是让神经网络输出y和样本标签Y尽可能地接近。因此定义目标函数为:E(W,b)=(Y-y)2E(x,Y),其中E(x,Y)是遍历所有的训练样本和标签后的均值,我们的主要关注点是第一项。回顾感知器算法,他调整的思路主要是加减法计算,或许这就是其不能应用于非线性可分问题的原因吧。
梯度下降法的主要思路是:
1.先初始化待定参数(W,b)
2.应用迭代算法更新(W,b),并求局部极值
3.使用局部极值时的(W,b)作为学习结果
其中迭代更新的数学推导过程如下:
在第n步迭代中,w和b表示如下:
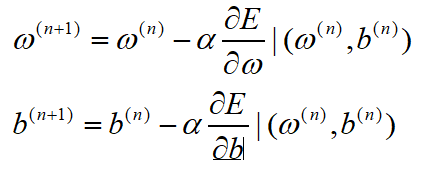 式5-1
式5-1
上式中的
被称为学习率,可以控制每一步调整的量的大小,梯度下降法就像下山,学习率过大,就像你一步过去迈在了对面的山峰上,可能导致收敛效果很差;学习率过小,就像你在走娘炮步,要走一年才能下山。
将目标函数E(w,b)进行泰勒展开可以得到:
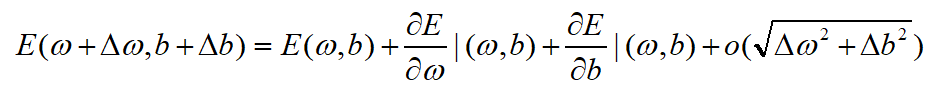 式5-2
式5-2
其实,式5-1中的更新量就是式5-2中的增量
w和
b
将上述更新结果代入,得到:
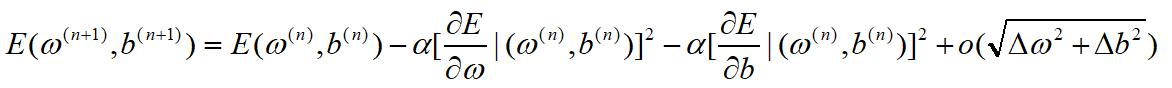 式5-3
式5-3
梯度值的平方永远大于等于零,所以这就可以保证目标函数值可收敛到局部极小值,注意,是局部极小值,而不是全局极小值。
回到图4-1中的神经网络,结合梯度下降算法,我们发现,需要计算E对所有待估计的参数w和b的偏导数值,假如我们构建的神经网络较为复杂,那么计算量将会显著增大!这就要求我们改进算法,借助一些数学技巧简化计算。先将图4-1的神经网络稍作拆解如下:
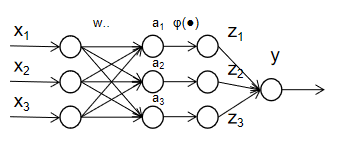 图5-4
图5-4
上述三层神经网络的输出为:
y=w1z1+w2z2+w3z3
=w1
(w11x1+w12x2+w13x3+b1)+w2
(w21x1+w22x2+w23x3+b2)+w3
(w31x1+w32x2+w33x3+b3)
取目标函数为E=1/2(y-Y)2
神经网络中的y、a1、a2、a3是连接上一层的枢纽,因此可先求对枢纽变量的偏导数
根据求偏导法则,有:
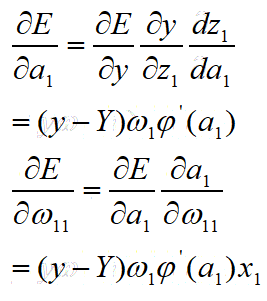
重复利用各个枢纽变量的偏导数,进而求得目标函数对待优化变量的偏导数,并且从后往前推导,后向传播算法由此而来。
而多层的复杂神经网络,则可以通过以上方法构造出递推公式进而简化计算和节省计算机内存,推导如下:
取输入层向量为:X=Z(0)
第一层:a(1)=W(1)Z(0)+b(1)
Z(1)=
(a(1))
……
第 l 层:a(l)=W(l)Z(l-1)+b(l)
Z(l)=
(a(l))
推导第m层神经网络枢纽变量的偏导数,设为
i(m):
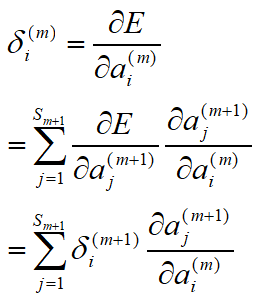 这里Sm+1为第m+1层神经元个数
这里Sm+1为第m+1层神经元个数
我们的目标是将上式转化为向量W的函数,因此对第二项入手: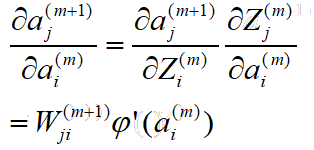
这就得到了关于待调整向量W的递推表达式,从后往前推导至第0层,即可根据输入训练样本向量X的大小来调整每层的权重向量了。
六、一些补充
在上面的推到中,有一个重要的量我们并没有留意,那就是神经元对应的非线性函数
(x).这个函数的导数及其求法对网络模型的性能十分重要。假如我们使用理想的阶跃函数,那么它的导数将会是一个冲激函数(在原点值无穷大,且在[0+,0-]区间内积分为1).在《信号与系统》我们学过,奇异函数及其导数,都是不能物理实现的。因此一般情况下,我们要找形式类似且方便求导的函数。
我们一般采用的函数有:
sigmoid函数:
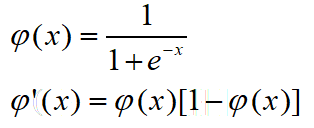
tanh函数:
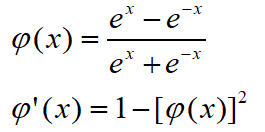
 图6-1
图6-1
如上式以及图6-1,这两个非线性函数具有和单位阶跃函数相似的特点,并且导数易求。
根据上面的推导,每加入一个样本,权重向量就会有一次更新,这样很有可能导致个别样本误差的严重影响和收敛速度过慢。因此一般情况下采用随机梯度下降法:即将所有的训练样本分为n组,每组为具有相等样本数量的Batch,每一次使用一个Batch进行训练,诞生一个Epoch,再将Batch随机打乱,反复训练出多个Epoch,避免随机误差的影响并保证训练的均衡。