一、注释
单行注释:# 被注释内容。
多行注释:’’‘被注释内容’’’,或者""“被注释内容”""
注:msg = ‘’’ #表示多行赋值,不表示注释,去掉前面的msg =则表示注释
print(‘a’)
print(‘b’)
print(‘c’)
‘’’
二、变量
变量:把程序运行的中间结果临时的存在内存里,以便后续的代码调用。
- 变量的赋值
abc = ‘123’ --------->变量名:abc,变量abc的值:123 - 变量定义的规则:
- 变量名只能是 字母、数字或下划线的任意组合
- 变量名的第一个字符不能是数字
- 以下关键字不能声明为变量名
[‘and’, ‘as’, ‘assert’, ‘break’, ‘class’, ‘continue’, ‘def’, ‘del’, ‘elif’, ‘else’, ‘except’, ‘exec’, ‘finally’, ‘for’, ‘from’, ‘global’, ‘if’, ‘import’, ‘in’, ‘is’, ‘lambda’, ‘not’, ‘or’, ‘pass’, ‘print’, ‘raise’, ‘return’, ‘try’, ‘while’, ‘with’, ‘yield’] - 变量的定义要具有可描述性。
- 推荐
- 驼峰体:AgeOfHuang = 73
- 下划线:age_of_huang = 73
- 不能使用中文。
三、常量
常量:一直不变的量。python中没有真正的常量,为了应和其他语言的口味,全部大写的变量称之为常量。将变量全部大写,放在文件的最上面。如身份证等等
eg: ID = ‘6666666666’
四、基本运算符
算数运算
变量:a=10,b=20
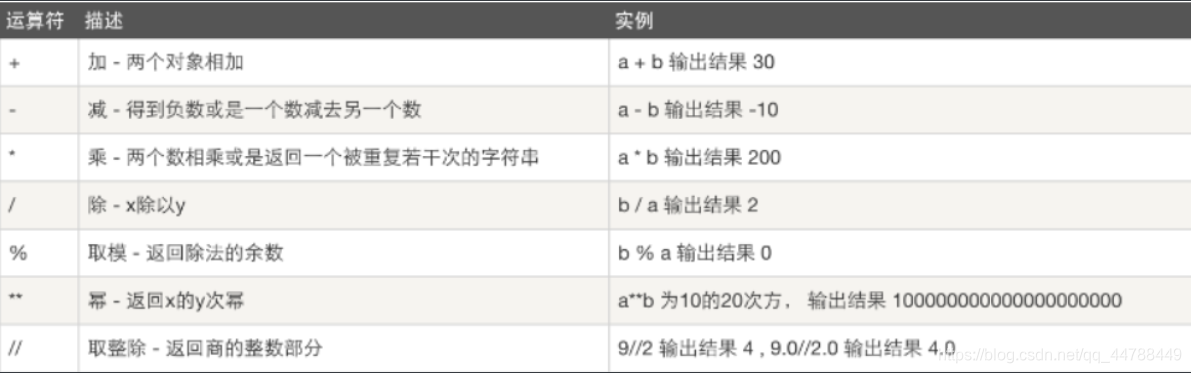
比较运算

赋值运算

逻辑运算

1,在没有()的情况下not 优先级高于 and,and优先级高于or,即优先级关系为( )>not>and>or,同一优先级从左往右计算。
2 , x or y , x为真,值就是x,x为假,值是y;
x and y, x为真,值是y,x为假,值是x。
成员运算:
测试实例中包含了一系列的成员,包括字符串,列表或元组。

判断子元素是否在原字符串(字典,列表,集合)中:
print('a' in 'bcvd') #返回False
print('y' not in 'ofkjdslaf') #返回True
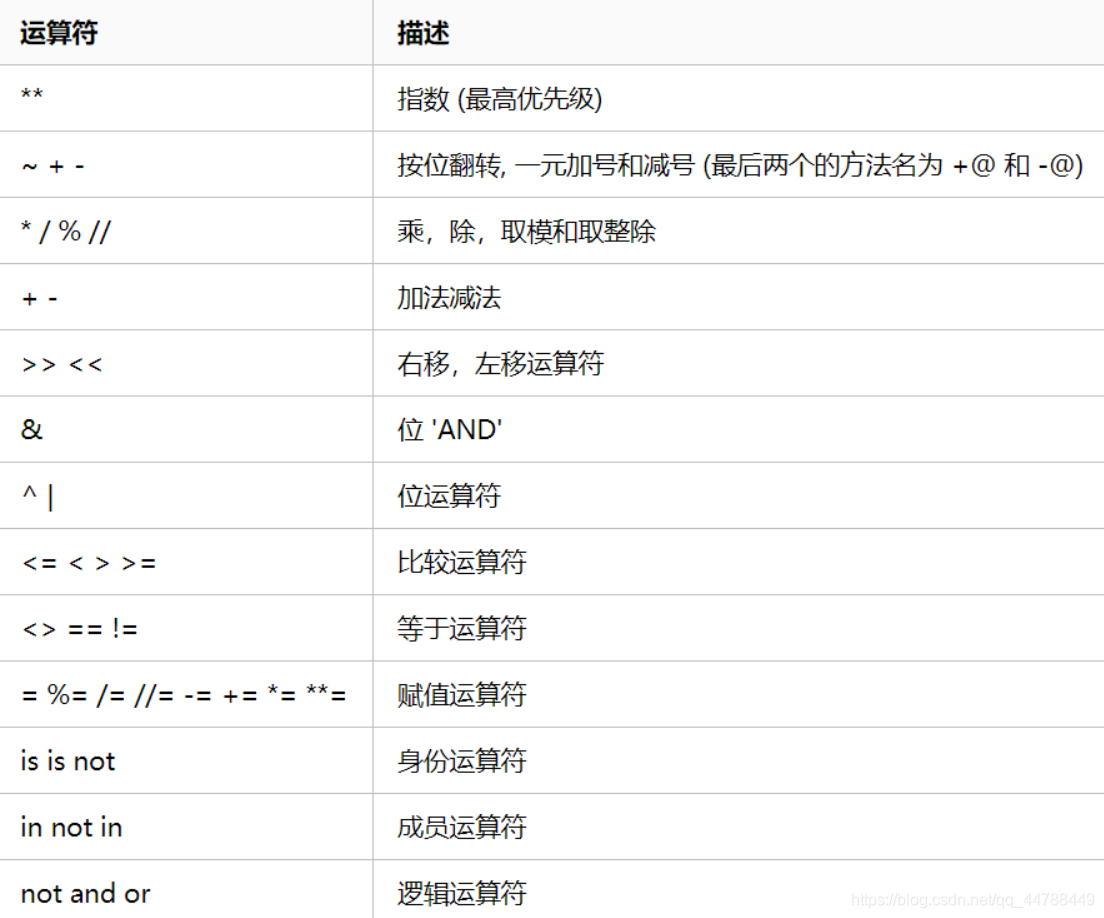
运算符优先级
从高到低
五、编码
计算机是需要存储数据和通过网络传输数据的,计算机存储在磁盘中的数据或者通过网络发送的数据本质发送的都是bit流也就是所谓的01010101101,那么这些010010是需要与咱们熟知的文字有标准的对应关系,这样咱们才可以识别这些数据。
计算机起初使用的密码本是:ASCII码(American Standard Code for Information Interchange,美国标准信息交换代码)是基于拉丁字母的一套电脑编码系统ASCII码中只包含英文字母,数字以及特殊字符与二进制的对应关系,主要用于显示现代英语和其他西欧语言,其最多只能用 8 位来表示(一个字节),即:2**8 = 256,所以,ASCII码最多只能表示 256 个符号。
也就是说:‘abc’,‘123’,’$%^’,'2d%'都是占3个字节
随着计算机的发展,ASCII码逐渐的不够使用。比如: 中⽂汉字有9万多个. 而ASCII 多也就256个位置. 所以ASCII不行了.
这时, 不同的国家就提出了不同的编码用来适用于各自的语言环境(每个国家都有每个国家的GBK,每个国家的GBK都只包含ASCII码中内容以及本国自己的文字). 比如, 中国的GBK, GB2312, BIG5, ISO-8859-1等等. 这时各个国家都可以使用计算机了. 但是GBK只包含中文,不能包含其他文字,言外之意,GBK编码是不能识别其他国家的文字的
GBK:只包含本国文字(以及英文字母,数字,特殊字符)与0101010对应关系。 GBK是采用单双字节变长编码,英文使用单字节编码,完全兼容ASCII字符编码,中文部分采用双字节编码。
对于ASCII码中的内容,GBK完全沿用的ASCII码,所以一个英文字母(数字,特殊字母)用一个字节表示,而对于中文来说,一个中文用两个字节表示。也就是说:‘abc’,‘123’,’$%^’,'2d%'还是占3个字节,‘ab中国’占6个字节
随着全球化的普及,由于网络的连通,各个国家都需要相互来往,此时急需一种编码能够共同使用,要包含全世界所有的文字与二进制0101010的对应关系,所以创建了万国码:Unicode
起初:Unicode规定一个字符用两个字节表示:
英文: a b c 6个字节 一个英文2个字节
中文: 中国 4个字节 一个中文用2个字节
但是这种也不行,这种最多有65535种可能,可是中国文字有9万多,所以改成一个字符用四个字节表示:
a----------> 01000001 01000010 01000011 00000001
b----------> 01000001 01000010 01100011 00000001
中---------> 01001001 01000010 01100011 00000001
这样虽然解决了问题,但是又引出一个新的问题就是原本a可以用1个字节表示,却必须用4个字节,这样非常浪费资源,所以对Uniocde进行升级。出现了UTF-8
UTF-8: 包含全世界所有的文字与二进制0101001的对应关系(最少用8位一个字节表示一个字符)
UTF-8 :最少用8位数,去表示一个字符.
英文: 8位,1个字节表示.
欧洲文字: 16位,两个字节表示一个字符.
中文,亚洲文字: 24位,三个字节表示.
也就是说:‘abc’,‘123’,’$%^’,'2d%'还是占3个字节,‘ab中国’占8个字节
单位之间的转换
8bit = 1byte
1024byte = 1KB
1024KB = 1MB
1024MB = 1GB
1024GB = 1TB
1024TB = 1PB
1024TB = 1EB
1024EB = 1ZB
1024ZB = 1YB
1024YB = 1NB
1024NB = 1DB