1、用自己的语言大致描述kafka架构原理图
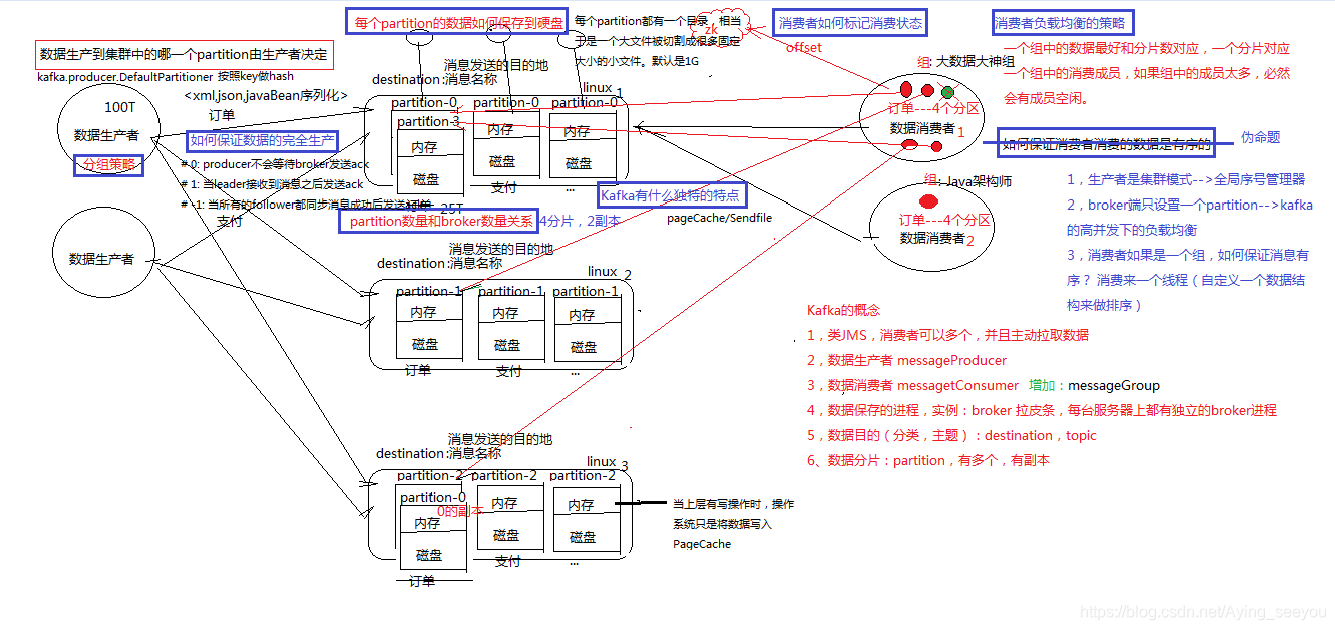
1>创建topic设置分区和副本数,生产者以<key,value>的方式发布数据到borker上的leader 副本[如果副本数不为1,zookeeper通过监听机制向kafka发出请求,kafka会在副本间选出一个leader副本来接受生产者发布的数据],再由其他副本复制leader副本上的数据
2>在broker里,leader副本将数据写入到内存,当内存达到默认值后,会以缓冲的形式缓存到硬盘中,同时其他的副本复制leader副本里的数据。
3>消费者以分组的形式可以让同一时间不同组的某个成员访问相同的数据,同一个组里不能有两个成员访问相同的分区,当某个组里的某个成员的server挂掉了,zookeeper会通过监听机制来安排其他同组成员来访问数据,以免数据丢失
2、kafka分片保存算法: partion 如何分布在 broker
在知道每一个borker上的分区个数的时候,利用算法列出一个borker集合,
分区编号对broker取余得到的值的排列:
0%3=0 --> Hdoop3;
1%3=1 --> Hdoop1;
2%3=2 --> Hdoop2;
3%3=0 --> Hdoop3;
4%3=1 --> Hdoop1;
可以看出来顺序为:Hadoop3,Hadoop1,Hadoop2
那么就按照分区的编号依次分布在Hadoop3,Hadoop1,Hadoop2上

3、kafka生产数据时数据的分组策略(kafka的文件存储机制): 生产的消息怎么分配到partion
默认类defaultpartitioner【可以自己定义】
发布每一条数据的格式是(k,val)
数据产生到集群中的partition由生产者决定的(key)
Utils.abs(key.hashCode) % numPartitions 上文中的key是producer在发送数据时传入的,produer.send(KeyedMessage(topic,myPartitionKey,messageContent))
4、每个partition的数据是如何保存到硬盘上的?
答:一个topic分为好几个partition,每一个分区代表一个文件夹保存在broker上,而每一个分区的命名是从序号0开始递增,它里面的消息是有序的,并且它的目录下有多个segment的文件(包含.index,.log),
而每个segment的大小默认为1g,当数据达到默认之后,会产生一个新的segment文件,这个segment文件的命名规则是以上一个segmen文件的最后一条数据的物理偏移量来命名的
在理论环境下,broker按照顺序读写的机制,可以每秒保存600M的数据。主要通过pagecache机制,尽可能的利用当前物理机器上的空闲内存来做缓存。
当前topic所属的broker,必定有一个该topic的partition,partition是一个磁盘目录。partition的目录中有多个segment组合(index,log)
5、kafka的ack机制/kafka如何能保证数据的完全生产: 0 1 -1 all
request.required.acks=?设置发送数据是否需要服务端反馈【config/producer.properties里设置】
0:[延迟低,存储的保证弱]:表示生产者不会得到broker返回的ack,当server挂掉会丢失数据
1:[持久性强]:会保证leader replica接收到数据后,生产者会得到返回的ack,在server确定请求成功处理后client才会返回。只有在生产者刚把数据写到leader副本上还没来得及复制就挂了,消息才会丢失
-1:[最好的持久性]:在所有的副本接收了数据后,producer才会得到返回的ack。只要有一个副本存活数据就不会丢失
【生产者生产数据时,broker会不会返回ack给producer】
all
6、kafka的消费者如何消费数据:
每次消费数据,消费者都会记录自己offsets的偏移量,并且会注册到zookeeper里,同时zookeeper记住了每一个消费者消费的分区,zookeeper会监听,一旦挂掉就会通过负载均衡
消费的位置:zkCli.sh:ls /consumers/?/offsets
owner:这个组下每一个消费者消费的哪一个partitioner
7、消费者负载均衡的策略:
一个分片对应一个消费者
8、数据有序的讨论: 伪命题
生产者生产数据后存放在各个分区里,每一个分区里的数据都不一样,消费者在消费时从分区里找到数据再展示出来的数据是无序的,但分区内的数据是有序的。要想全局有序就是只有一个分区
伪命题
如果要全局有序的,必须保证生产有序,存储有序,消费有序。
由于生产可以做集群,存储可以分片,消费可以设置为一个consumerGroup,要保证全局有序,就需要保证每个环节都有序。只有一个可能,就是一个生产者,一个partition,一个消费者。这种场景和大数据应用场景相悖。