发现钓鱼网站
我平时会刷一会儿微博,看看当前热门数据。
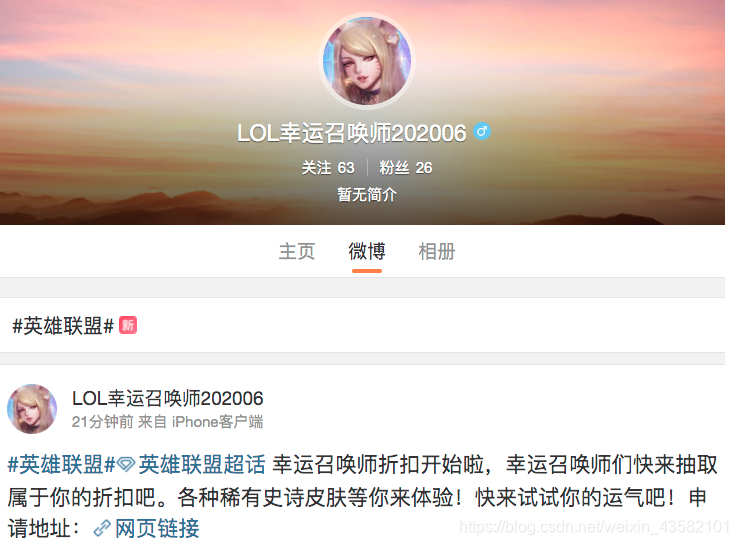
前天的时候在热门微博里看到了一则广告 <6月幸运召唤师抽奖> ,身为一个从s3开始入手的老玩家,没有丝毫犹豫直接从链接点了进去。

身为程序员的我,近些年也算是浏览大千网站,打开网页的第一时间就感觉有些不对。经过确认,该网站为钓鱼网站,直接向官方账号进行了反馈,也在12321进行了网站举报。
并没有这么简单
然而今天洽过午饭之后,打开微博发现事情并没有这么简单,该网站还是钓到了很多人
微博的超链接标签看不到详细的url,所以很多使用微博app的人更容易上当
从微博app中访问链接,打开后的界面跟真实的抽奖界面是完成一样的
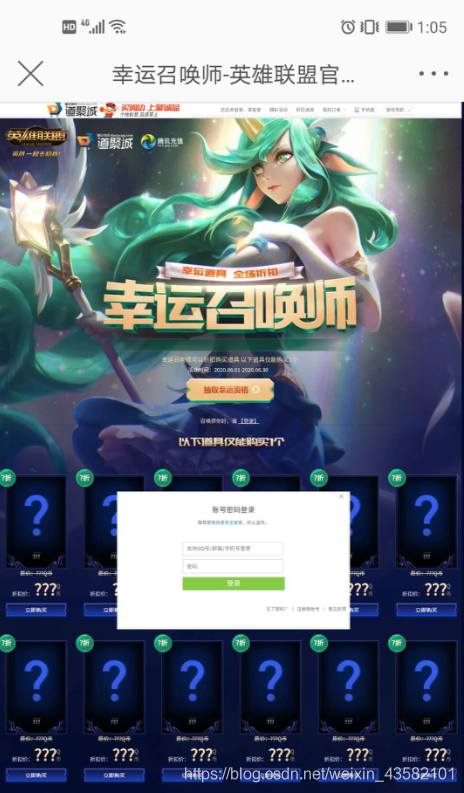
等到你提交账号密码之后,他会跳转到真正的抽奖官网,留下一脸懵逼的你打问号。
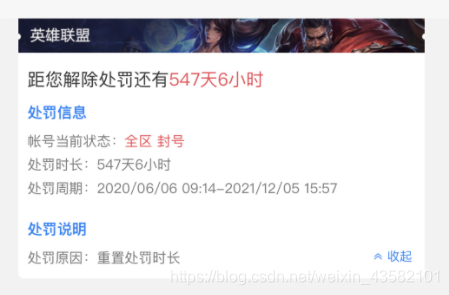
我查看了一下,已经有很多上当的同学在微博泄愤了,辛苦打的号被封3年是真的太气了。
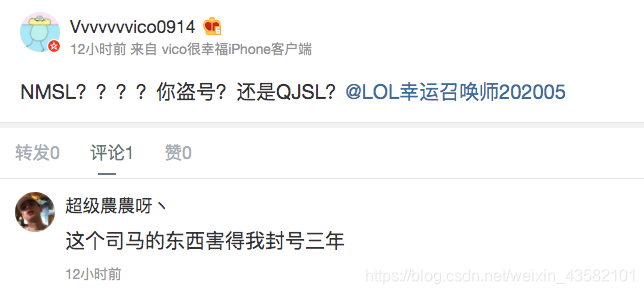
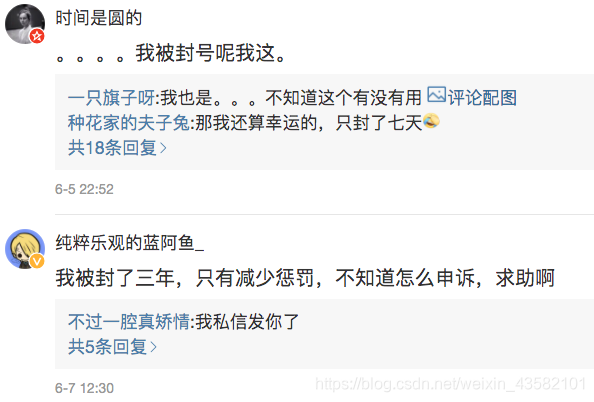
我深入了解了一下,这个渔夫之前的账号 <LOL6月幸运账号师> 已经被封了,但是他又申请了新的账号继续钓鱼,这可真是防不胜防,所以写一篇文章提醒下大家,谨防假冒。
如何察觉是钓鱼网站
我在公司电脑上浏览微博,一般使用的是网页版或者移动版。
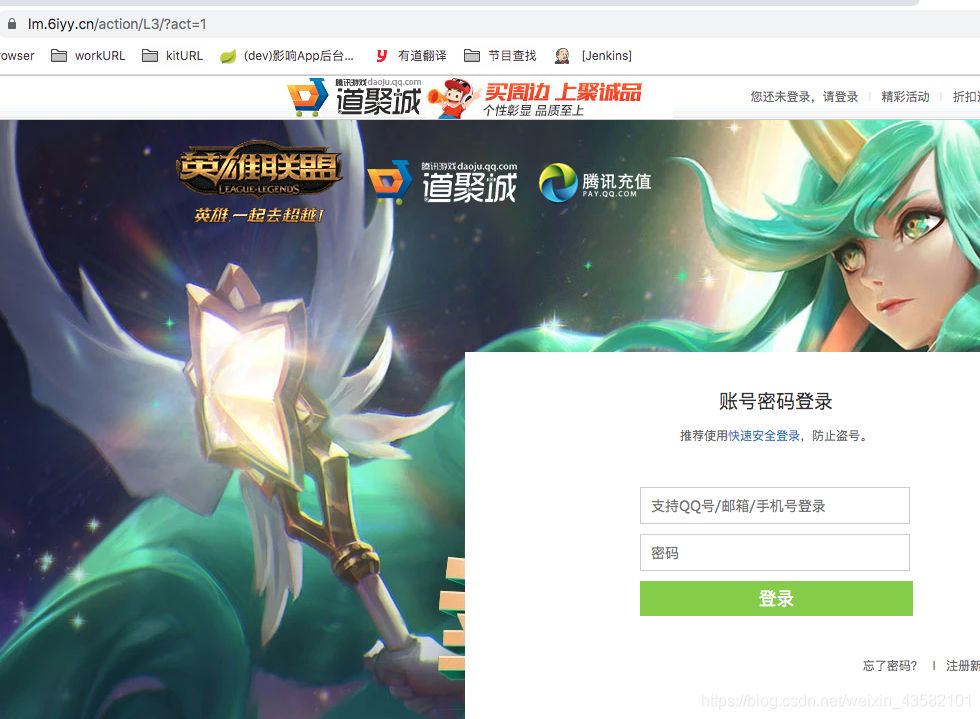
钓鱼网站链接: https://lm.6iyy.cn/action/L3/?act=1
首先是该网站的异常url,一般来说英雄联盟的活动,链接前面都是 https://lol.qq.com/ 。
LoL官方抽奖的链接: https://lol.qq.com/act/a20200415lucky/index.html
而这个 lm.6iyy.cn 看起来就比较low。当遇到这个情况,最好先到官网确认下,谨防假冒。
对于使用app看不到链接的同学,碰到这种广告推送,千万不要随意点击。打开了也不要提交账号密码,先确认是否是正确有效的官方活动,如果真的脑子一热就把账号密码提交了,一定要快速更改密码,亡羊补牢未为晚也。
吃一堑长一智,要怪就怪这些无良网站开发者和某浪的神奇推送机制吧
难道就这样忍了吗
虽然年迈的我没有被骗到,但是看着那一个个被封几百天的同学,自己也是很生气啊!
作者并不是hacker,也不擅长通过特殊手段去攻击这个钓鱼网站,基本的举报工作做完之后,我决定想办法恶心他一下。
这种钓鱼网站主要是收集玩家的账号信息,然后挂到租赁平台或者是测试外挂脚本等等。
那我就伪造百万个账号密码提交到他的后台,给被骗的同学增加修改密码的反应时间。
使用Asyncpy提交账号
Asyncpy是我之前基于asyncio和aiohttp开发的一个轻便高效的爬虫框架,可实现并发操作。(使用文档)
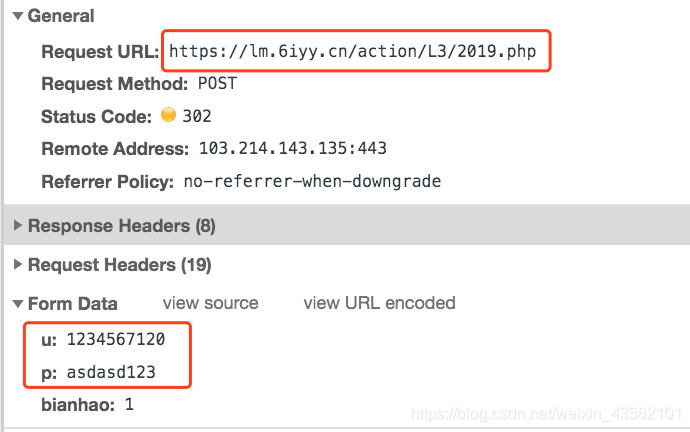
先查看一下这个钓鱼网站的提交接口,参数很简单,u 和 p 是我填写的账号和密码
开始编写一个提交账号的爬虫程序。
安装框架: pip install asyncpy
创建项目: asyncpy genspider demo
然后打开这个项目。

打开demo.py
开始编写爬虫文件
# -*- coding: utf-8 -*-
from asyncpy.spider import Spider
import settings
from asyncpy.request import Request
from middlewares import middleware
import random
class DemoSpider(Spider):
name = 'demo'
settings_attr = settings
start_urls = []
url = 'https://lm.6iyy.cn/action/L3/2019.php'
pwstr = 'abcdefghigklmnopqrstuvwxyz123456789!#.'
async def start_requests(self):
for i in range(100000): # 创建请求任务
userport, password = '', ''
for num in range(9):
userport = str(random.randint(1,9))+userport # 帐号
l = random.randint(10,15) # 密码的位数
for num in range(l):
password = str(random.choice(self.pwstr))+password # 密码
data = {"u": userport,
"p": password
}
print(data)
yield Request(url=self.url,data=data,callback=self.parse)
async def parse(self, response):
pass
DemoSpider.start(middleware=middleware)
打开settings.py文件
找到 CONCURRENT_REQUESTS 参数,控制并发线程的数量。
CONCURRENT_REQUESTS = 300
修改 middleware.py文件
修改user-agent,可以添加代理IP
# -*- coding: utf-8 -*-
from asyncpy.middleware import Middleware
from asyncpy.request import Request
from asyncpy.spider import Spider
middleware = Middleware()
@middleware.request
async def UserAgentMiddleware(spider:Spider, request: Request):
ua = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3100.0 Safari/537.36"
request.headers.update({"User-Agent": ua})
# request.aiohttp_kwargs.update({"proxy": "http://58.218.200.228:3632"})
然后重新返回demo.py,点击运行,当前10w个账号的提交任务已经开始了!
还可以多创建几个demo.py文件,同時启动哈,可参考(使用文档)
控制好请求的速度,不要搞那么快,铭记初衷,毕竟我们不是恶意破坏服务器哈!