http://www.52im.net/forum.php?mod=collection&action=view&ctid=7&page=1
携程早期IM架构
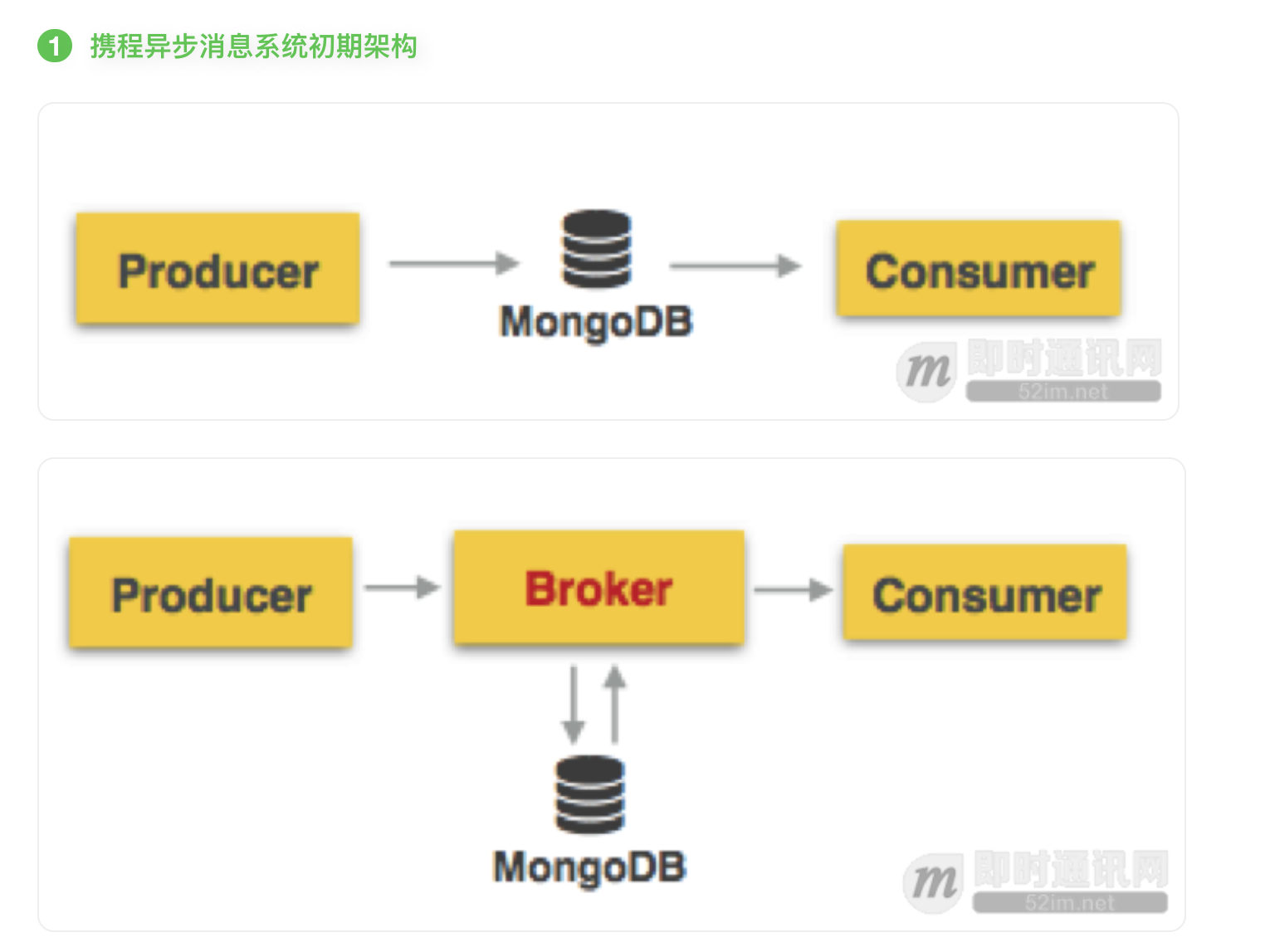

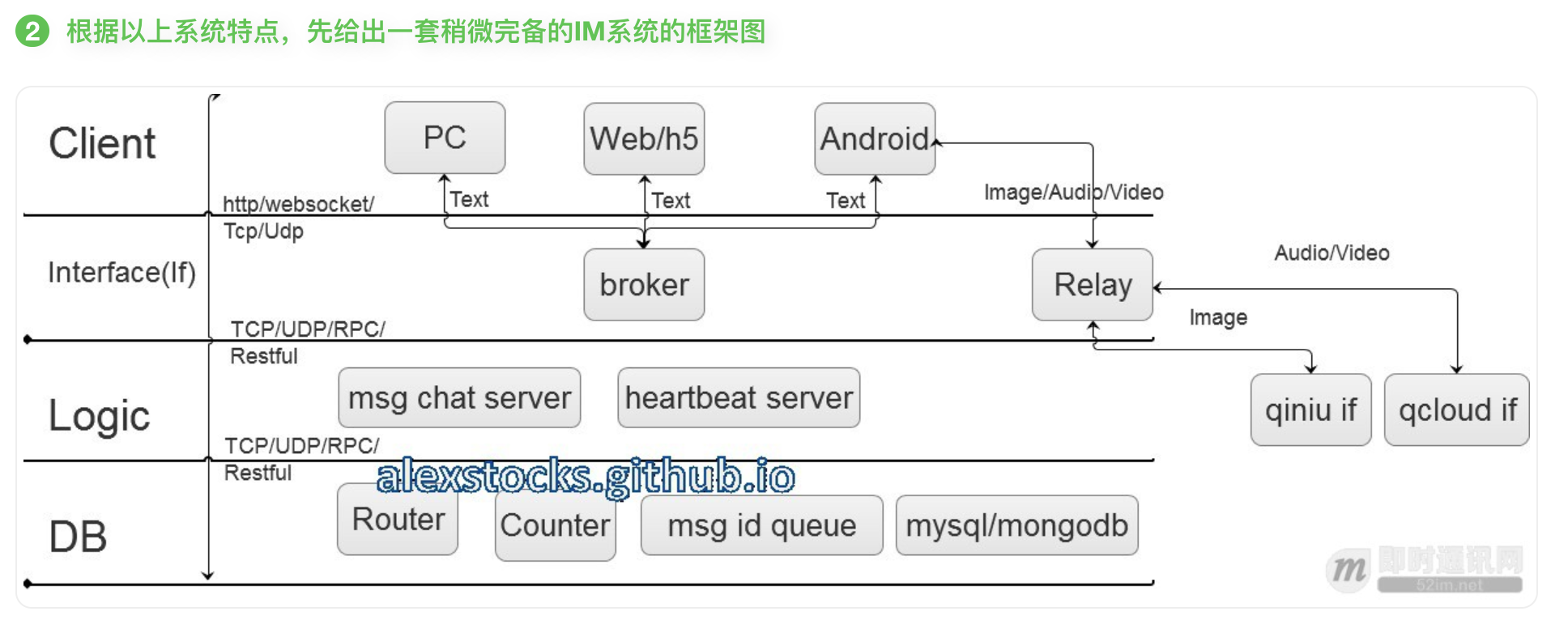

四 发送流程
消息的制造者[producer]一般是IM系统的最基本单元UIN[即一个自然人],既然是一个自然人,就认为其发送能力有限,不可能一秒内发出多于一条的消息,即其消息频率最高为: 1条msg / s。高于这个频率,都被认为是键盘狂人或者狂躁机器人,客户端或者服务端应该具有拒绝给这种人提供服务或者丢弃其由于发狂而发出的消息。
基于上面这个假设,producer发出的消息请求被称为msg req,服务器给客户端返回的消息响应称为msg ack。整个消息流程为:
- A client以阻塞方式发出msg req,req = {producer uin, channel name, msg device id, msg time, msg content};
- B broker收到消息后,以uin为hash或者通过其他hash方式把消息转发给某个msg chat server;
- C msg chat server收到消息后以key = Hash{producer uin【发送者id】 + msg device id【设备id】+ msg time【消息发送时间,精确到秒】}到本地消息缓存中查询消息是否已经存在,如果存在则终止消息流程,给broker返回"duplicate msg"这个msg ack,否则继续;
- D msg chat server到Counter模块以channel name为key查询其最新的msg id,把msg id自增一后作为这条消息的id;
- E msg chat server把分配好id的消息插入本地msg cache和msg DB[mysql/mongoDB]中;
- F msg chat server给broker返回msg ack, ack = {producer uin, channel name, msg device id, msg time, msg id};
- G broker把msg ack下发给producer;
- H producer收到ack包后终止消息流程,如果在发送流程超时后仍未收到消息则转到步骤1进行重试,并计算重试次数;
- I 如果重试次数超过两次依然失败则提示“系统繁忙” or “网络环境不佳,请主人稍后再尝试发送”等,终止消息发送流程。
上面设计到了一个模块图中没有的概念:msg cache,之所以没有绘制出来,是因为msg cache的大小是可预估的,它只是用于消息去重判断,所以只需存下去重msg key即可。假设msg chat server的服务人数是40 000人,消息发送频率是1条/s,消息的生命周期是24 hour,消息key长度是64B,那么这个cache大小 = 64B * (24 * 3600)s * 40000 = 221 184 000 000B,这个数字可能有点恐怖,如果是真实商业环境这个数字只会更小,因为没有人一天一夜不吃不喝不停发消息嘛。其本质是一个hashset(C++中对应的是unordered_set),物理存储介质当然是共享内存了。

经过思考,msg cache只需存下某个UIN在某个device上的最新的消息时间即可,msg cache的结构应为hashtable,以{UIN + device id}为key,以其最新的消息的发送时间(客户端发送消息的时间)为value,不再考虑消息的生命周期。msg chat server每收到一条新消息就把新消息中记录的发送时间与缓存中记录的消息时间比较即可,如果新消息的时间小于这个msg pool记录的时间即说明其为重复消息,大于则为新消息,并用新消息的msg time作为msg cache中对应kv的value的最新值。假设UIN为4B,device id为4B,时间为4B,则msg cache的数据的size(不计算hashtable数据结构本身占用的内存size)为12B * 40000 = 480 000B,新msg pool完全与每条消息的lifetime无关,这就大大下降了其内存占用。
用户查看消息邮箱中的本地历史消息的时候,就要依据msg id把消息排序好展现给用户。至于用户发送过程中看到的消息可以认为是本地消息的一个cache,每个channel最多给他展现100条,这100条消息的排序要依照每条消息的发出时间或者是消息的接收时间[这个接收到的消息时间以消息到达本机时的本地时钟为依据]。当用户要查看超出数目如100条消息之外的消息,客户端要引导用户去走历史消息查看流程。




上面提到的一个词:newest channel id 或者 client newest msg id of channel,其意思就是消息接收者所在的channel的所拥有的本地消息的最新id。一般地,如果server端的Counter能够稳定地提供服务,channel中的msg id应该是连续的,如果客户端检测到msg id不连续,可以把不连续处的id作为newest channel id,要求server端再把这个msg id以后的消息重发下来,这就要求client有消息去重判断的功能。
每次收到server端下发的消息后,用户必须更新local newest channel msg id,把消息id窗口往前推进,不要因为id不连续而一直不更新这个值,因为服务端的服务也不一定超级稳定
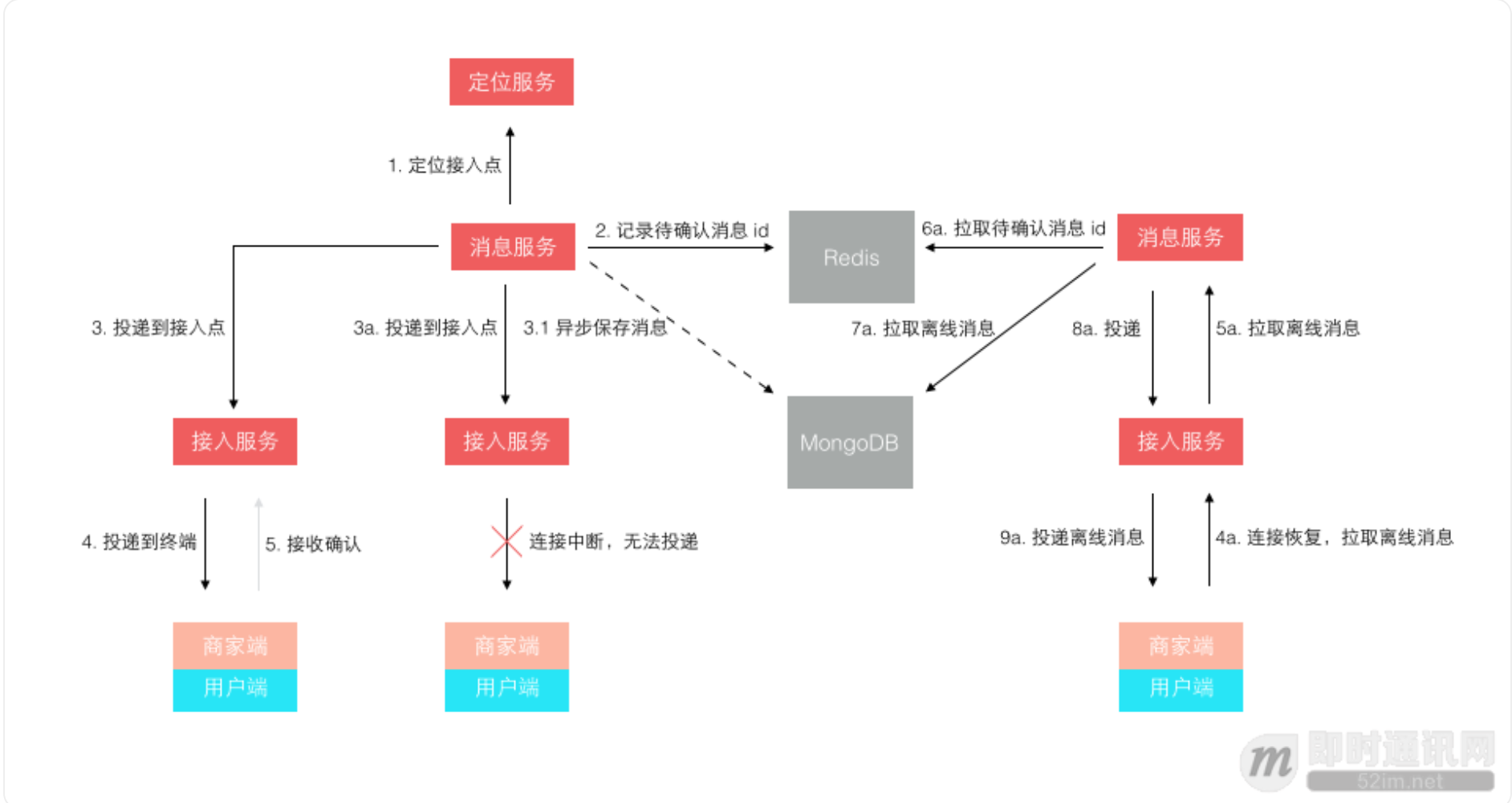

+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
从零到卓越:京东客服即时通讯系统的技术架构演进历程

1.0 的功能十分简单,实现了一个 IM 的基本功能,接入、互通消息和状态。 另外还有客服功能,就是顾客接入咨询时的客服分配,按轮询方式把顾客分配给在线的客服接待。 用开源 Mina 框架实现了 TCP 的长连接接入,用 Tomcat Comet 机制实现了 HTTP 的长轮询服务。 而消息投递的实现是一端发送的消息临时存放在 Redis 中,另一端拉取的生产消费模型。
这个模型的做法导致需要以一种高频率的方式来轮询 Redis 遍历属于自己连接的关联会话消息。 这个模型很简单,简单包括多个层面的意思:理解起来简单;开发起来简单;部署起来也简单。 只需要一个 Tomcat 应用依赖一个共享的 Redis,简单的实现核心业务功能,并支持业务快速上线。
但这个简单的模型也有些严重的缺陷,主要是效率和扩展问题。 轮询的频率间隔大小基本决定了消息的延时,轮询越快延时越低,但轮询越快消耗也越高。 这个模型实际上是一个高功耗低效能的模型,因为不活跃的连接在那做高频率的无意义轮询。 高频有多高呢,基本在 100 ms 以内,你不能让轮询太慢,比如超过 2 秒轮一次,人就会在聊天过程中感受到明显的会话延迟。 随着在线人数增加,轮询的耗时也线性增长,因此这个模型导致了扩展能力和承载能力都不好,一定会随着在线人数的增长碰到性能瓶颈。
1.0 的时代背景正是京东技术平台从 .NET 向 Java 转型的年代,我也正是在这期间加入京东并参与了京东主站技术转型架构升级的过程。 之后开始接手了京东咚咚,并持续完善这个产品,进行了三次技术架构演进。
2.0 版:成长阶段(时间:2012)
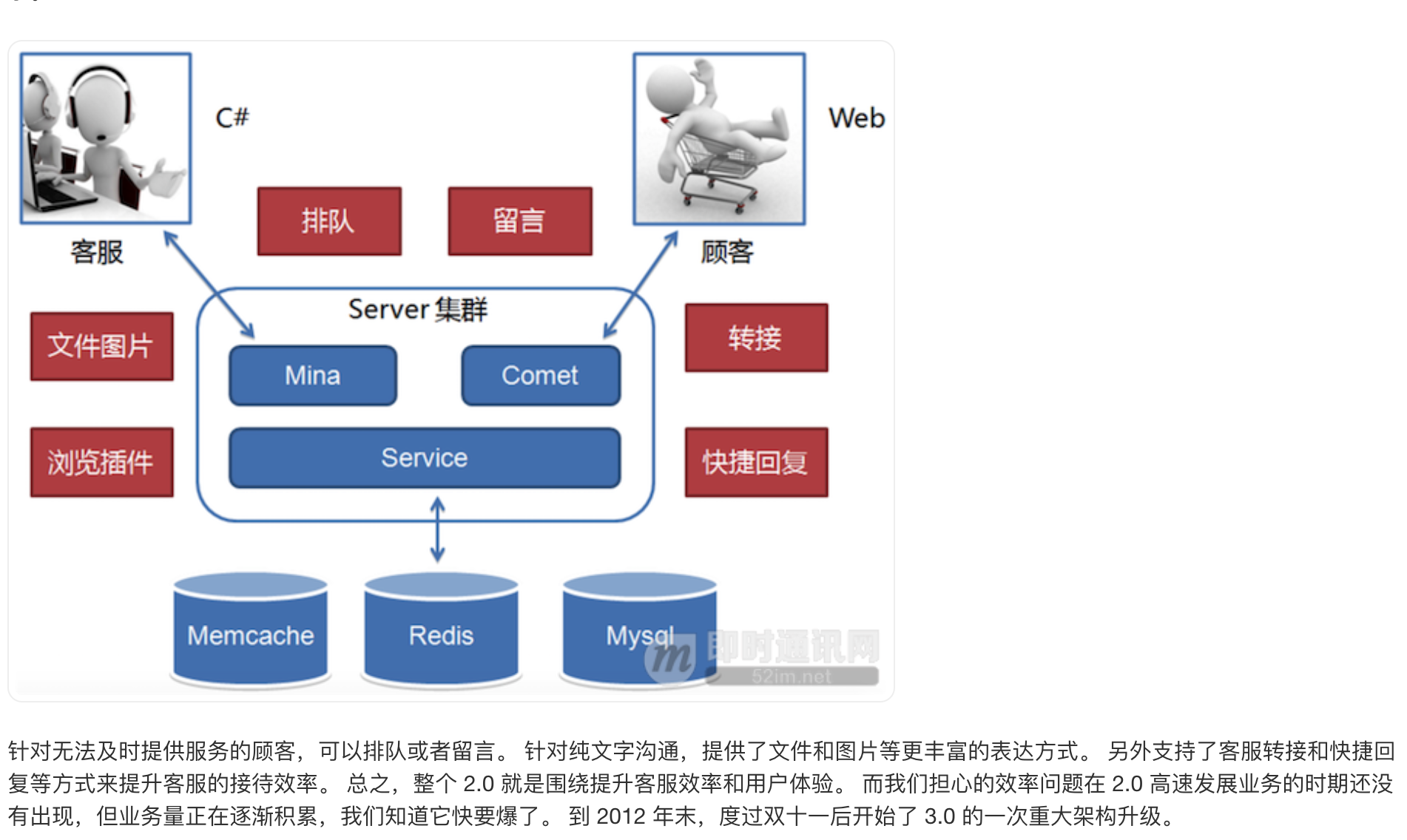
我们刚接手时 1.0 已在线上运行并支持京东 POP(开放平台)业务,之后京东打算组建自营在线客服团队并落地在成都。 不管是自营还是 POP 客服咨询业务当时都起步不久,1.0 架构中的性能和效率缺陷问题还没有达到引爆的业务量级。 而自营客服当时还处于起步阶段,客服人数不足,服务能力不够,顾客咨询量远远超过客服的服务能力。 超出服务能力的顾客咨询,当时我们的系统统一返回提示客服繁忙,请稍后咨询。 这种状况导致高峰期大量顾客无论怎么刷新请求,都很可能无法接入客服,体验很差。 所以 2.0 重点放在了业务功能体验的提升上,如下图所示。
3.0 版:爆发阶段(时间:2013 - 2014)
经历了 2.0 时代一整年的业务高速发展,实际上代码规模膨胀的很快。 与代码一块膨胀的还有团队,从最初的 4 个人到近 30 人。 团队大了后,一个系统多人开发,开发人员层次不一,规范难统一,系统模块耦合重,改动沟通和依赖多,上线风险难以控制。 一个单独 tomcat 应用多实例部署模型终于走到头了,这个版本架构升级的主题就是服务化。
服务化的第一个问题如何把一个大的应用系统切分成子服务系统。 当时的背景是京东的部署还在半自动化年代,自动部署系统刚起步,子服务系统若按业务划分太细太多,部署工作量很大且难管理。 所以当时我们不是按业务功能分区服务的,而是按业务重要性级别划分了 0、1、2 三个级别不同的子业务服务系统。 另外就是独立了一组接入服务,针对不同渠道和通信方式的接入端,见下图。
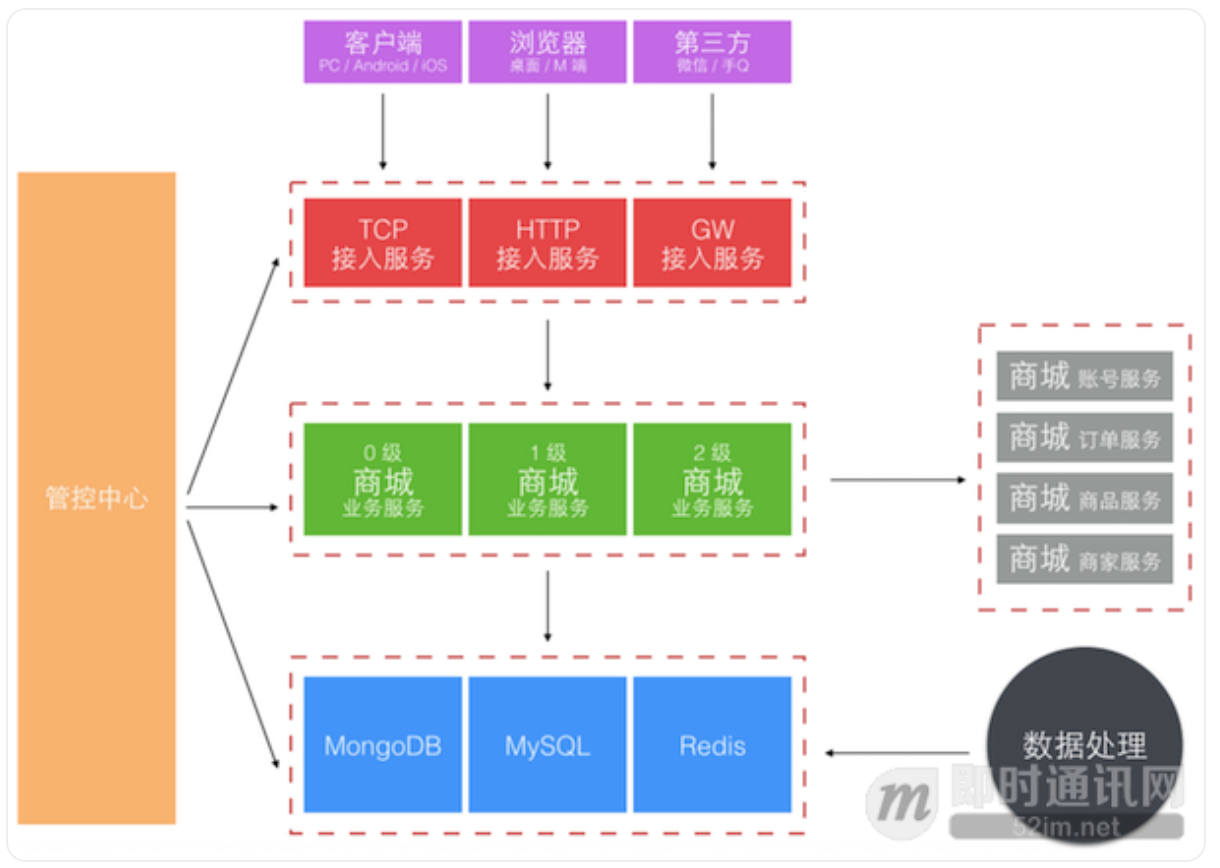
这次大的架构升级,主要考虑了三个方面:稳定性、效率和容量。 做了下面这些事情:
- 业务分级、核心、非核心业务隔离
- 多机房部署,流量分流、容灾冗余、峰值应对冗余
- 读库多源,失败自动转移
- 写库主备,短暂有损服务容忍下的快速切换
- 外部接口,失败转移或快速断路
- Redis 主备,失败转移
- 大表迁移,MongoDB 取代 MySQL 存储消息记录
- 改进消息投递模型
前 6 条基本属于考虑系统稳定性、可用性方面的改进升级。 这一块属于陆续迭代完成的,承载很多失败转移的配置和控制功能在上面图中是由管控中心提供的。 第 7 条主要是随着业务量的上升,单日消息量越来越大后,使用了 MongoDB 来单独存储量最大的聊天记录
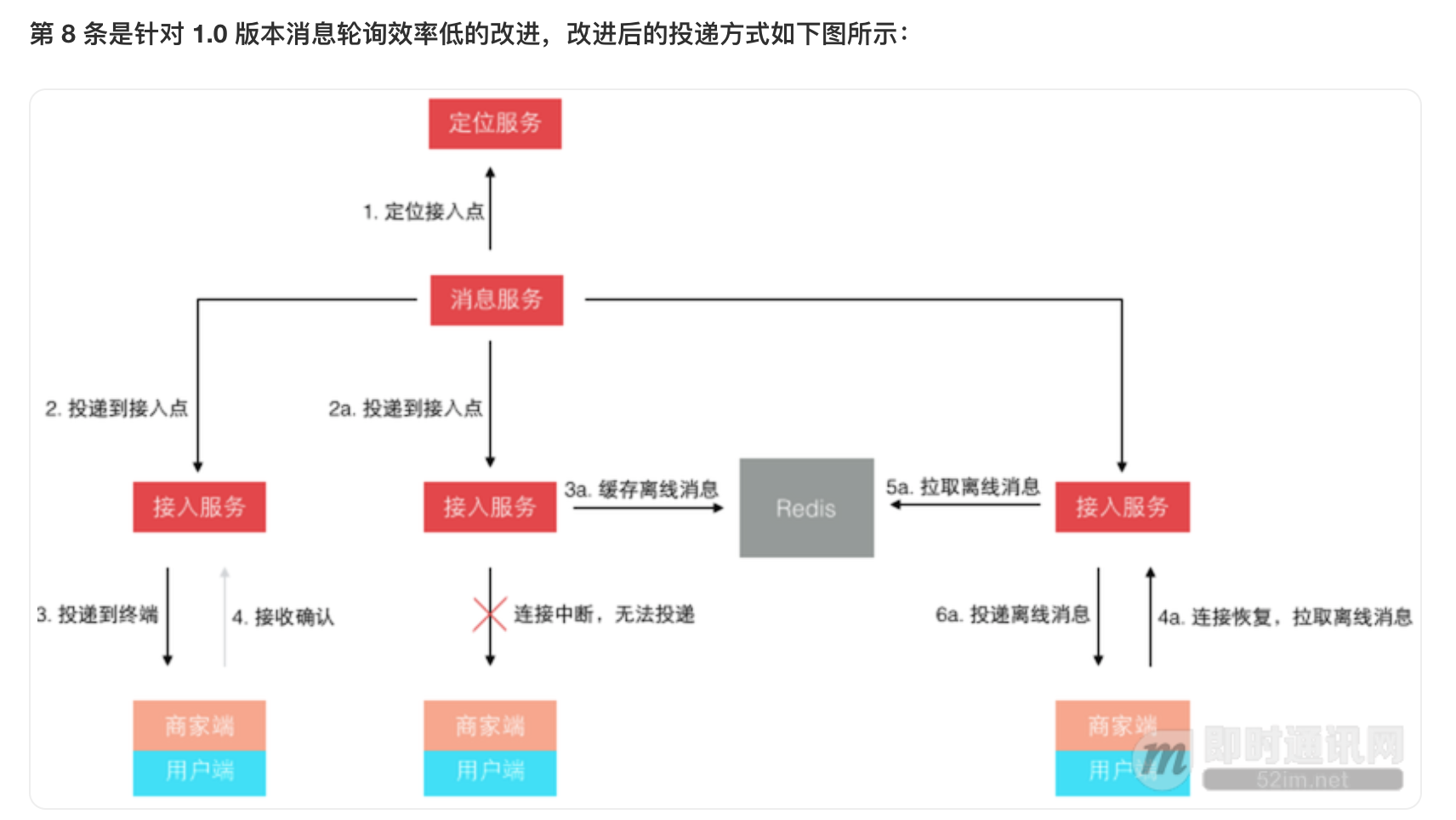
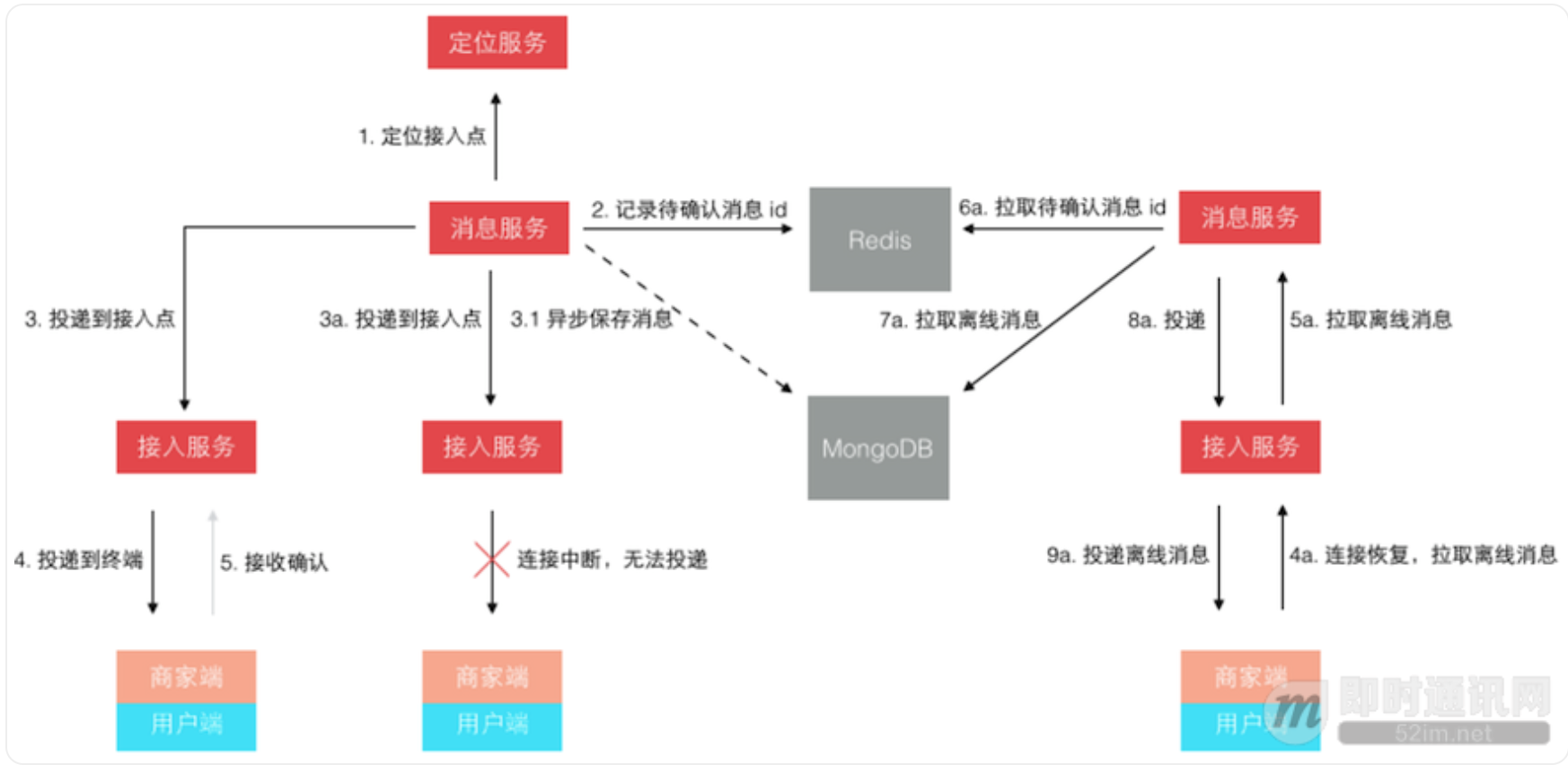
不再是轮询了,而是让终端每次建立连接后注册接入点位置,消息投递前定位连接所在接入点位置再推送过去。 这样投递效率就是恒定的了,而且很容易扩展,在线人数越多则连接数越多,只需要扩展接入点即可。 其实,这个模型依然还有些小问题,主要出在离线消息的处理上,可以先思考下,我们最后再讲。
3.0 经过了两年的迭代式升级,单纯从业务量上来说还可以继续支撑很长时间的增长。 但实际上到 2014 年底我们面对的不再是业务量的问题,而是业务模式的变化。 这直接导致了一个全新时代的到来
IM 咚咚使用的配置中心
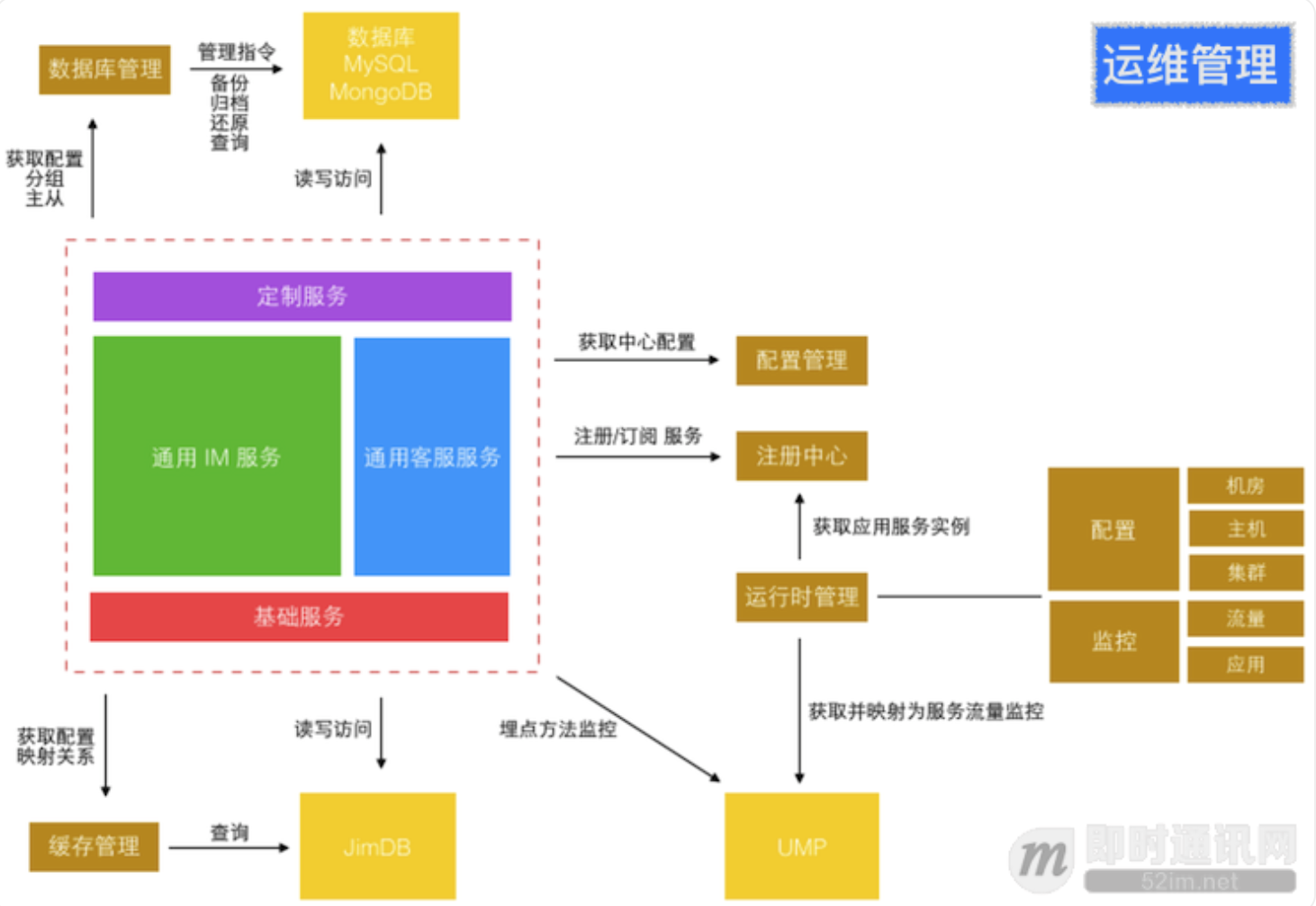
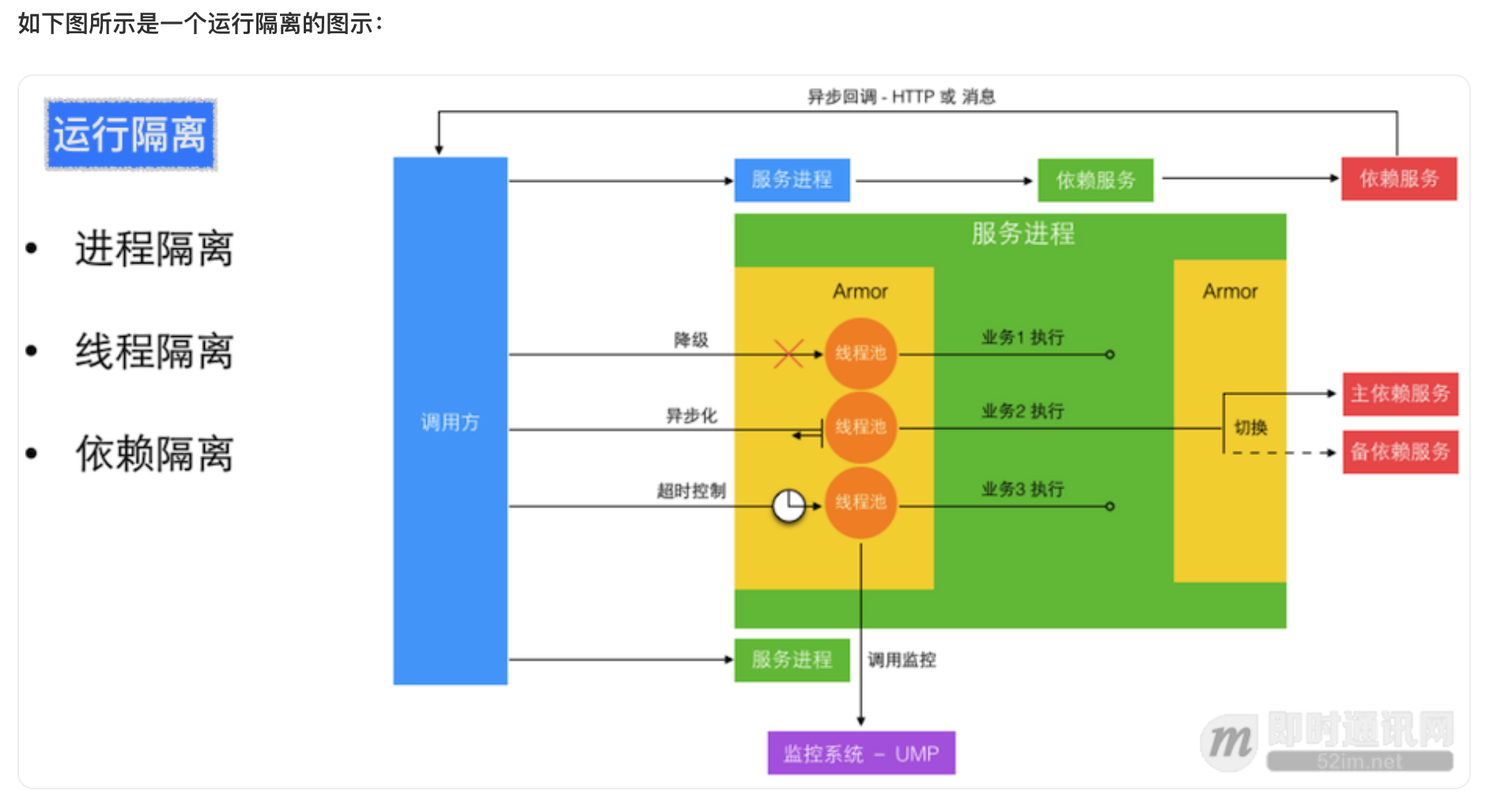
细粒度的微服务做到了进程间隔离,严格的开发规范和工具库帮助实现了异步消息和异步 HTTP 来避免多个跨进程的同步长调用链。 进程内部通过切面方式引入了服务增强容器 Armor 来隔离线程, 并支持进程内的单独业务降级和同步转异步化执行。而所有这些工具和库服务都是为了两个目标
- 让服务进程运行时状态可见
- 让服务进程运行时状态可被管理和改变
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
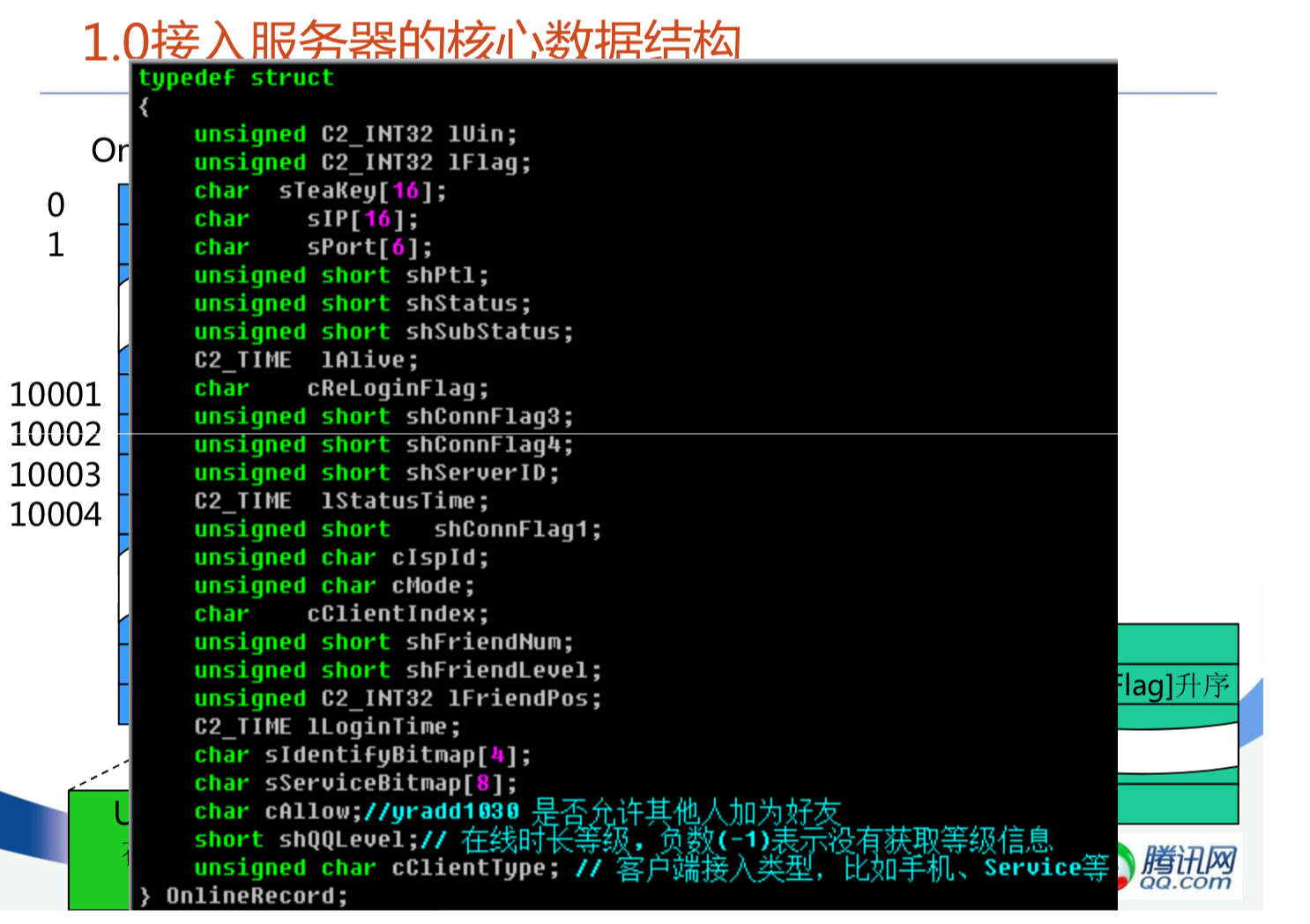
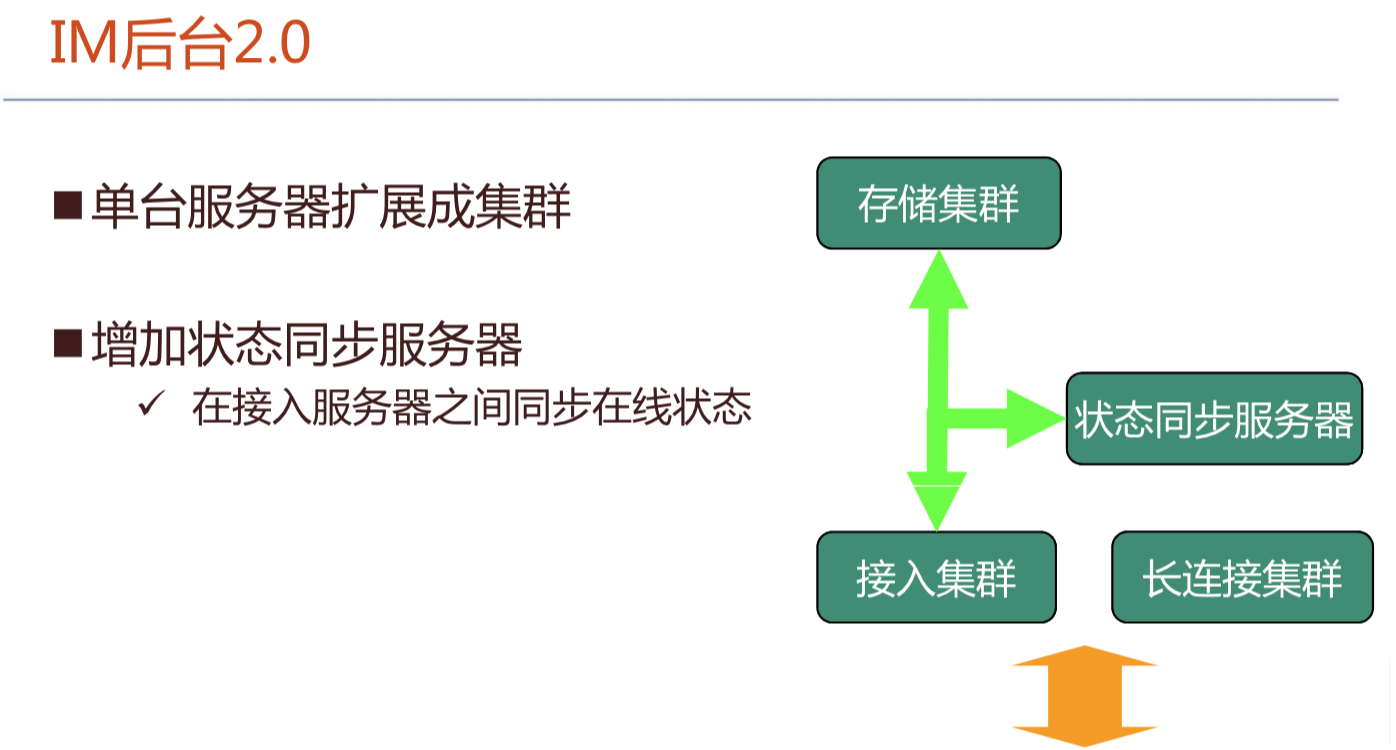
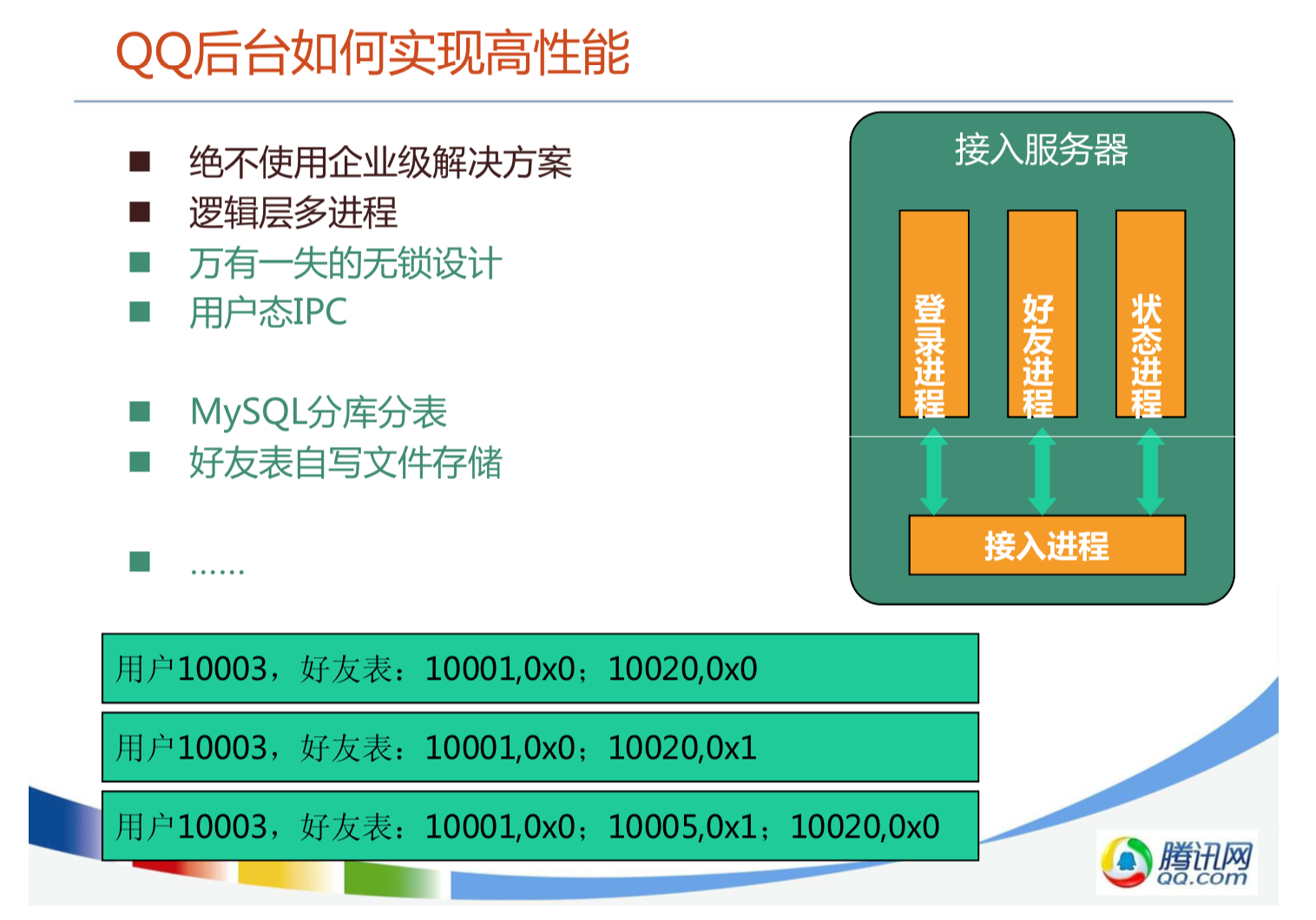
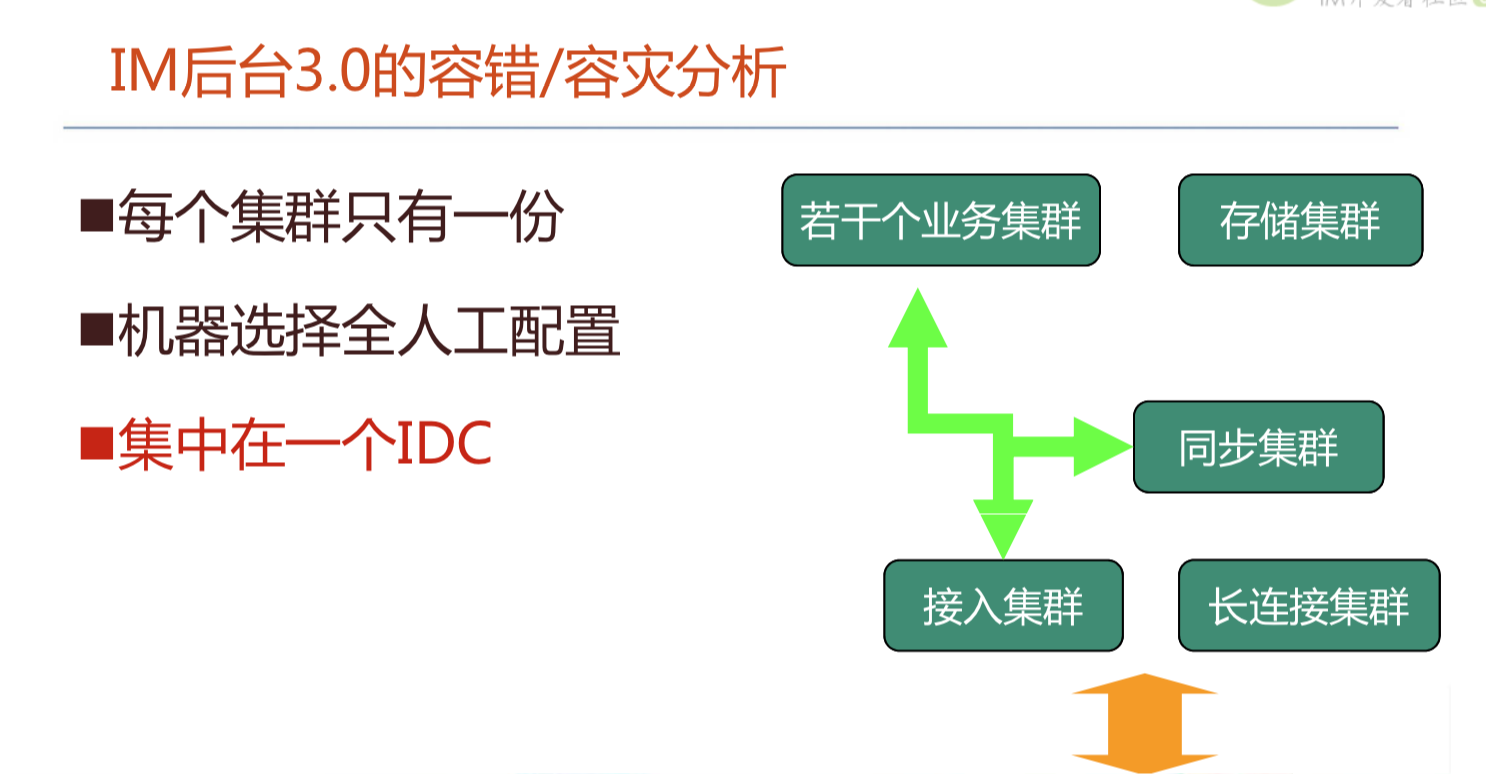
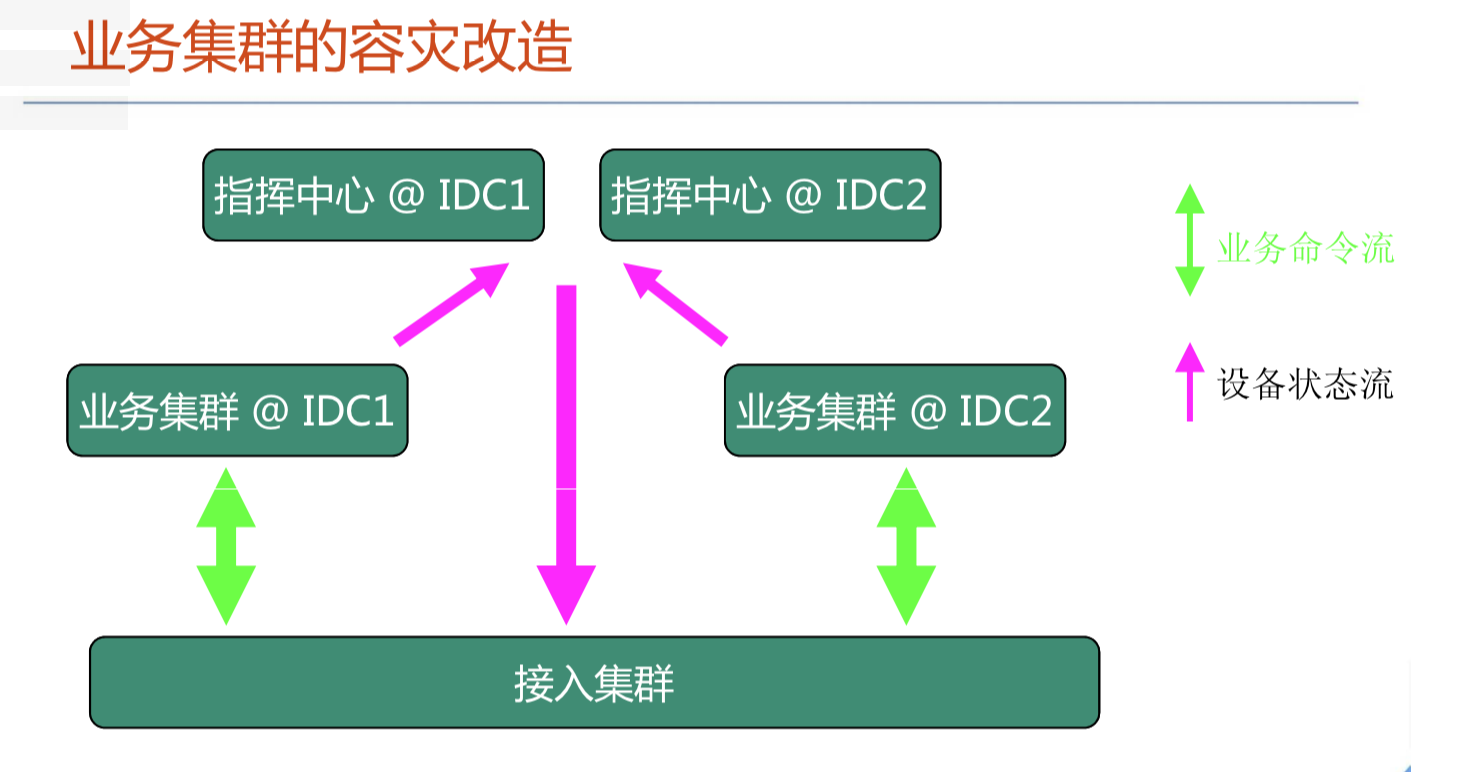
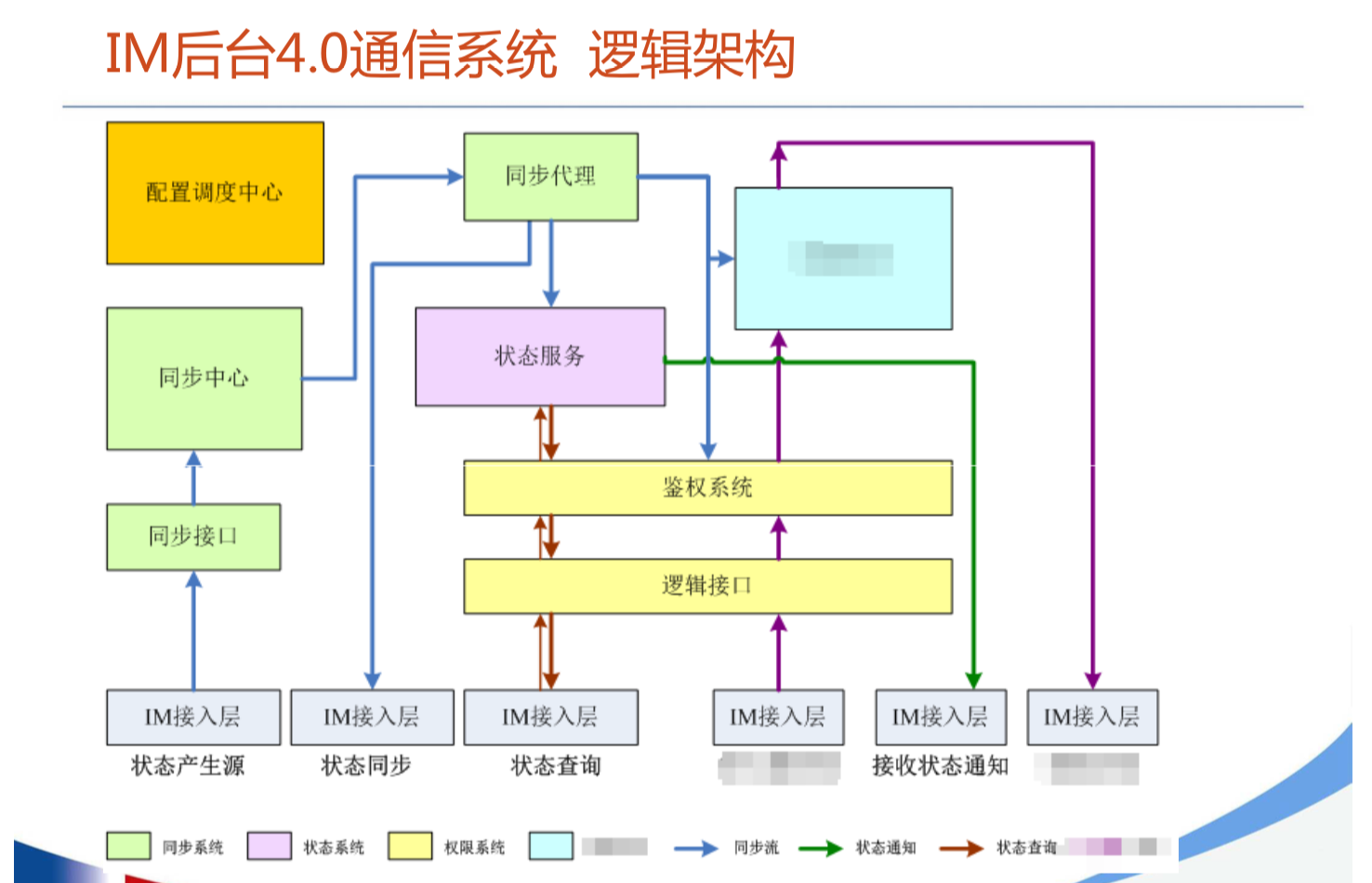
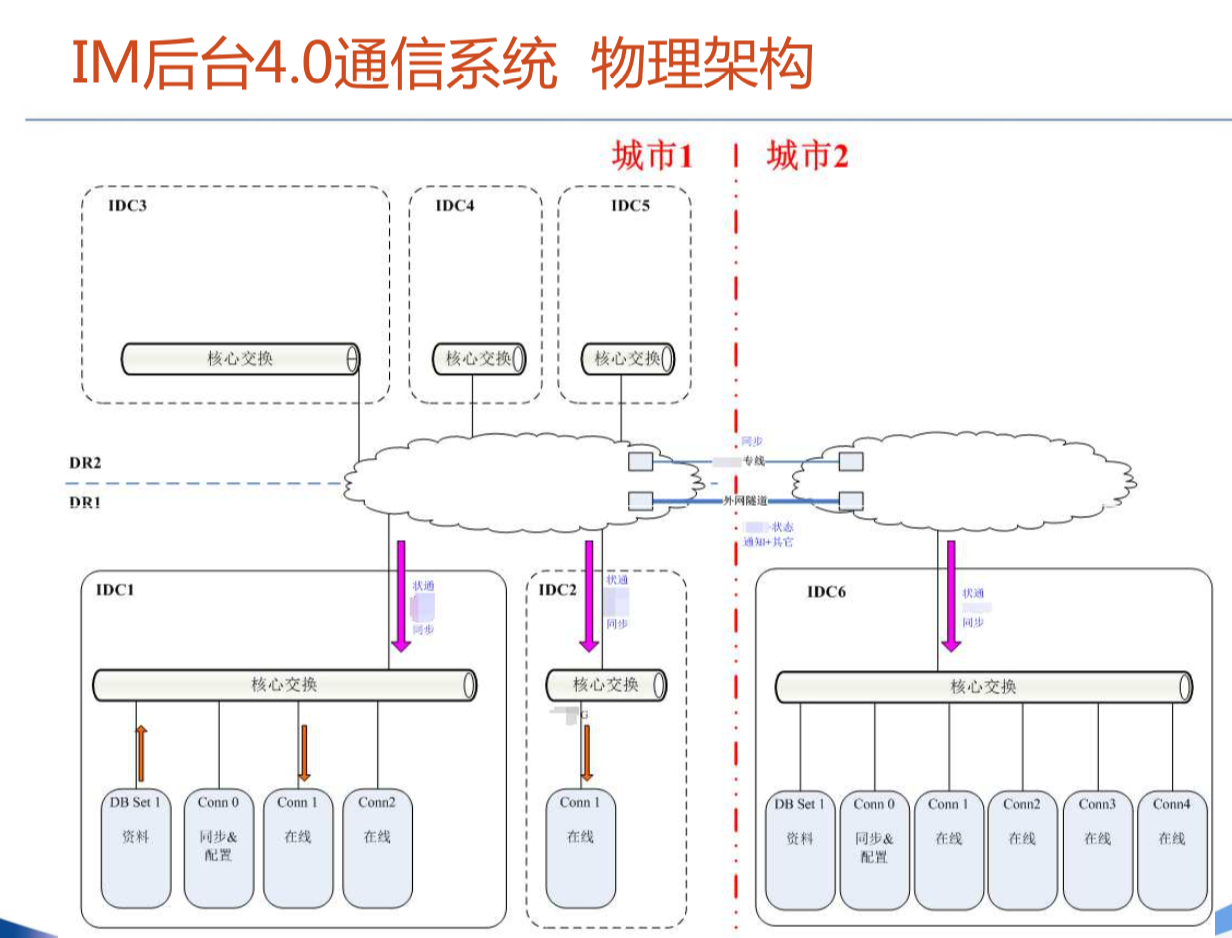
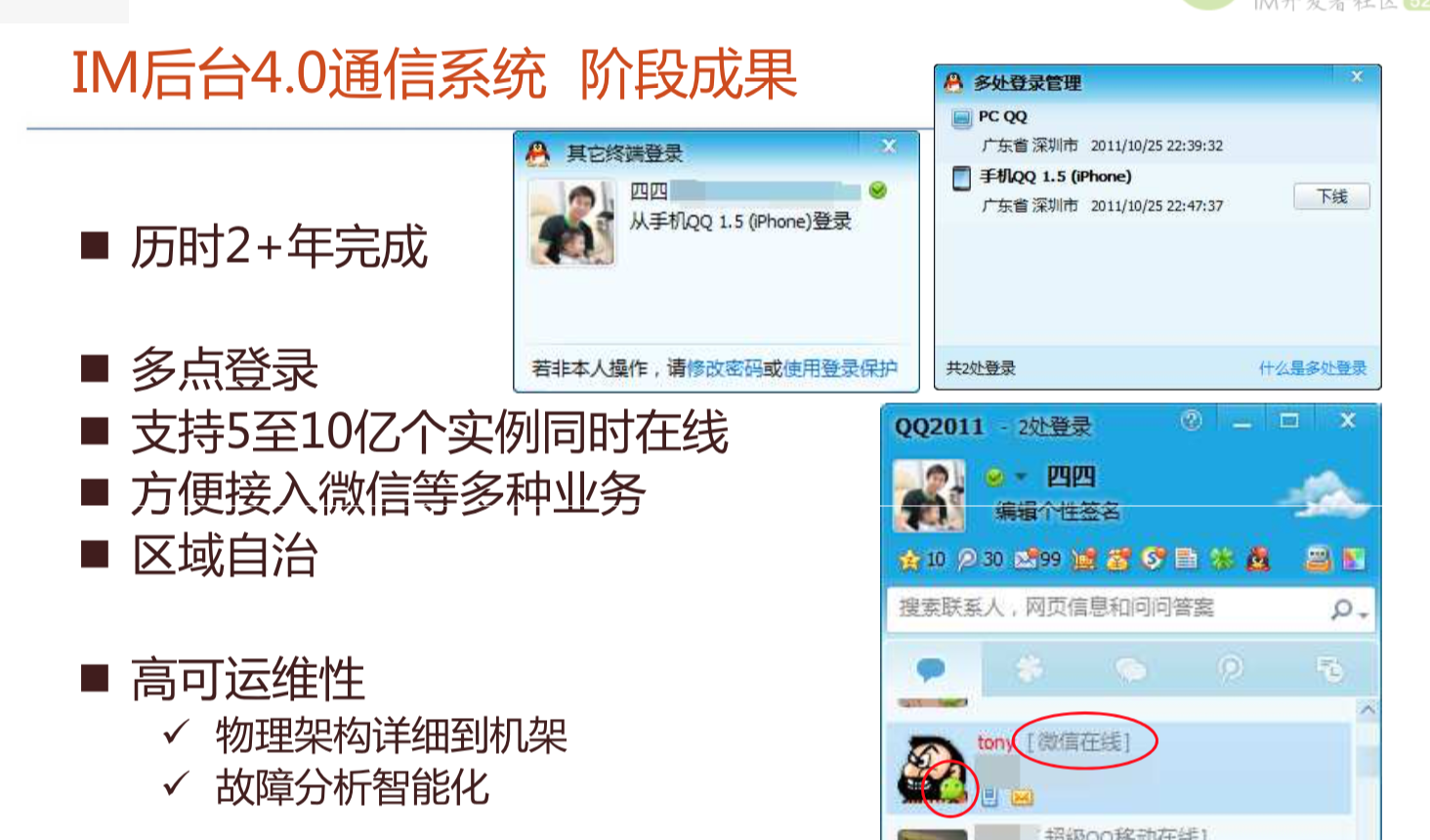
腾讯IM架构设计