from pandas import Series,DataFrame
import pandas as pd
import numpy as np
一、索引和切片
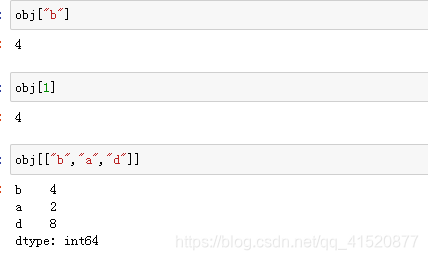
索引
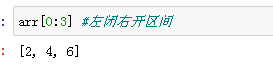
obj=Series([2,4,6,8],index=["a","b","c","d"])
obj

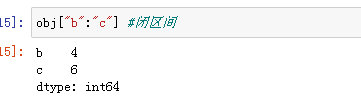
切片

二、运算
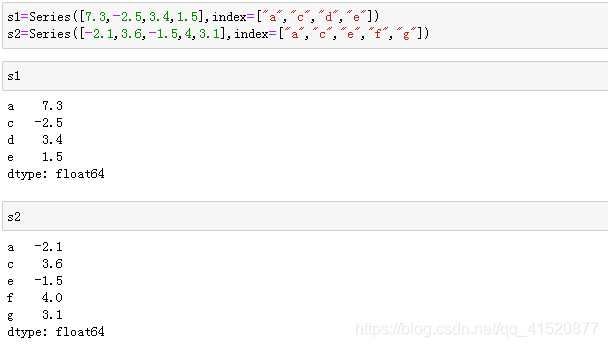

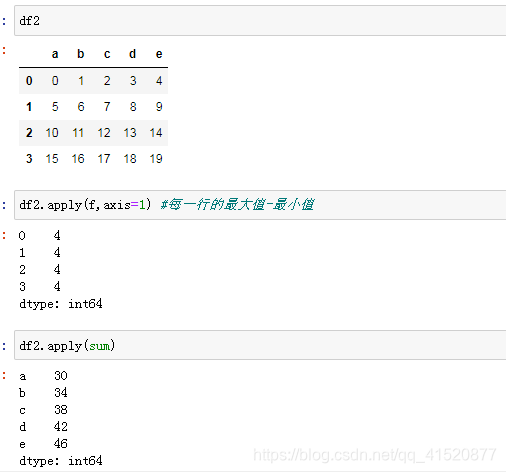
df1=DataFrame(np.arange(12).reshape((3,4)),columns=list("abcd"))
df1

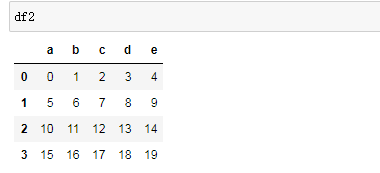
df2=DataFrame(np.arange(20).reshape((4,5)),columns=list("abcde"))
df2

df1+df2

df1.add(df2,fill_value=0) #填充空缺的值再相加

df1.add(df2).fillna(0) #将相加后的结果中NaN置为0

三、函数应用与映射
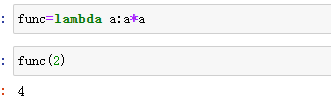
#函数应用与映射
f=lambda x:x.max()-x.min() #取一列中的最大值-一列中的最小值

#针对DataFrame的每一个元素进行映射
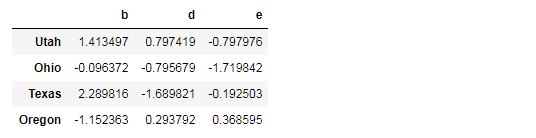
test=DataFrame(np.random.randn(4,3),
columns=list("bde"),
index=["Utah","Ohio","Texas","Oregon"])
test
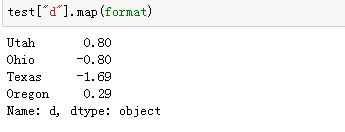
format=lambda x:"%.2f" % x #输入一个浮点数,保留两位小数
a=3.1415926
format(a)

test.applymap(format) #apply与applymap的区别

四、排序
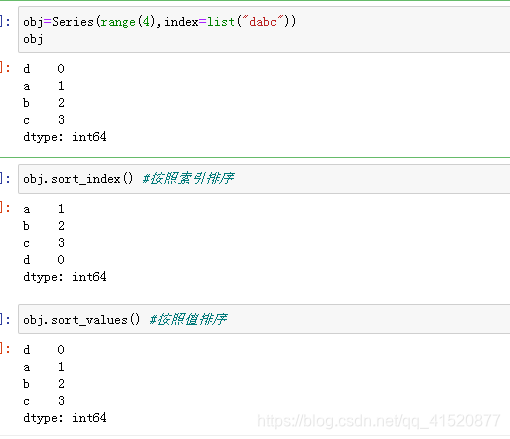
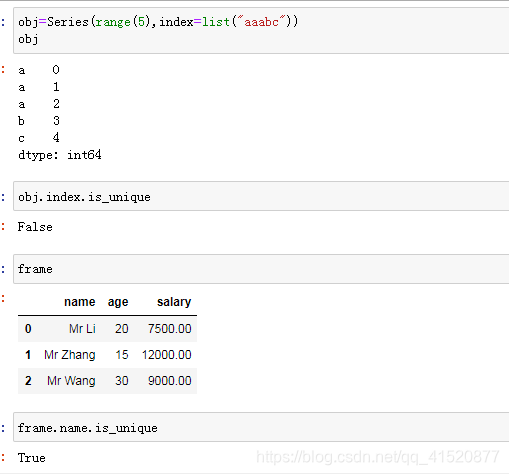
dir(obj) #查看属性方法
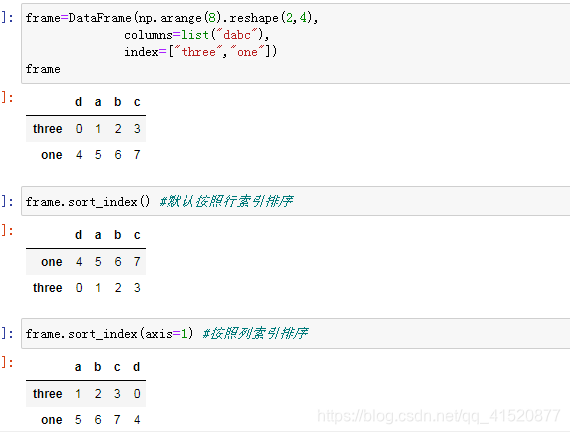
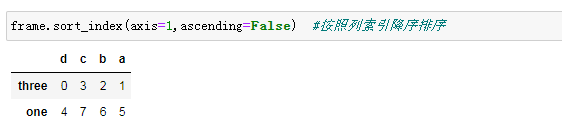
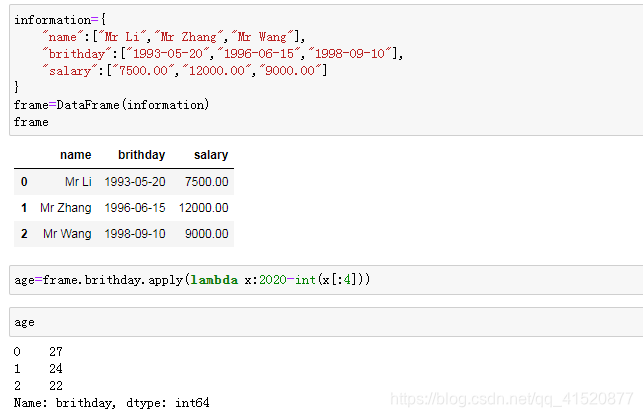
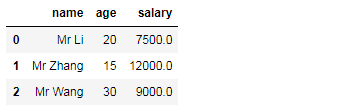
information={
"name":["Mr Li","Mr Zhang","Mr Wang"],
"age":[20,15,30],
"salary":[7500.00,12000.00,9000.00]
}
frame=DataFrame(information)
frame
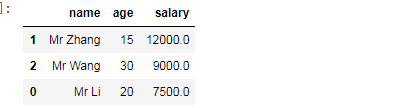
#按照某一列的值进行排序 降序排序
frame.sort_values(by="salary",ascending=False)
五、查重
六、汇总与统计


df1=DataFrame(np.arange(20).reshape((5,4)),columns=list("abcd"))
df1

df1.cumsum() #列值累加覆盖

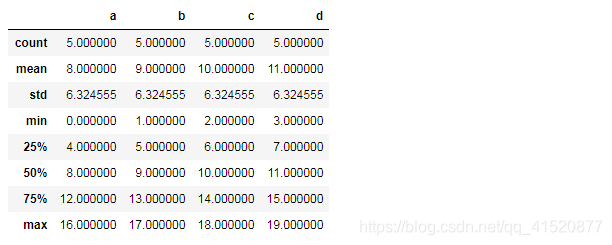
df1.describe() #对数值型的列进行描述性统计
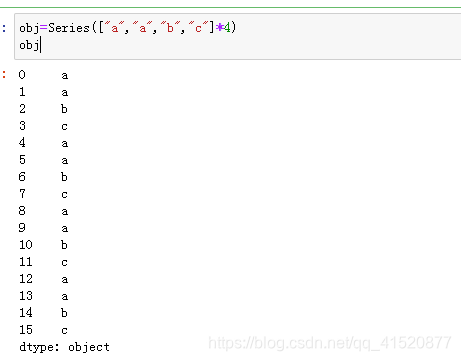
七、唯一值与频率统计
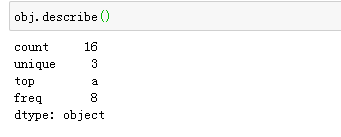
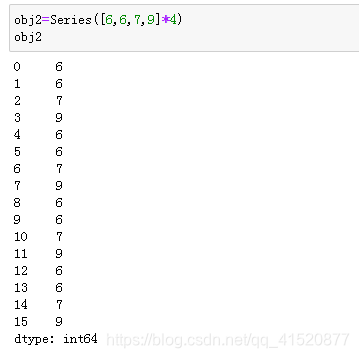
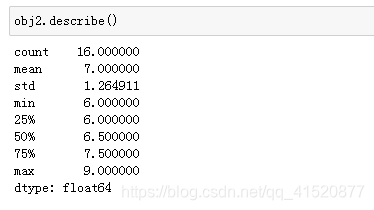
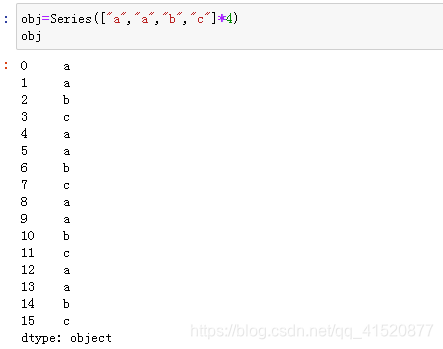
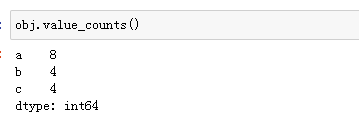


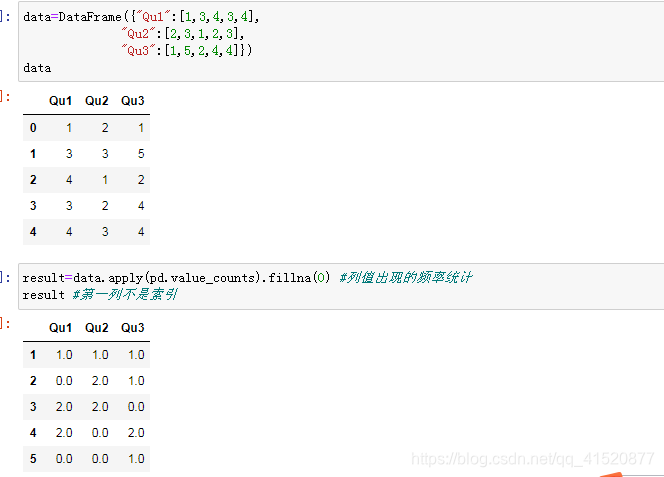
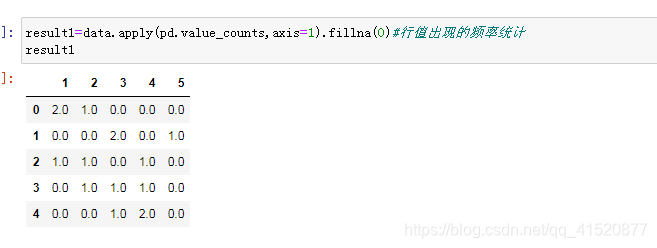
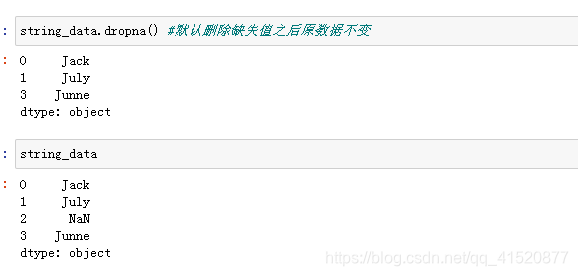
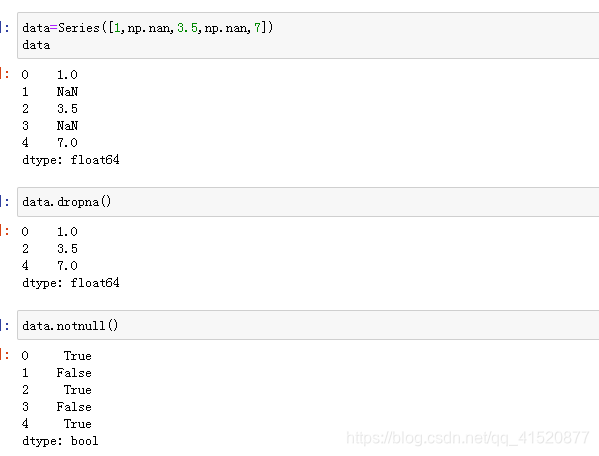
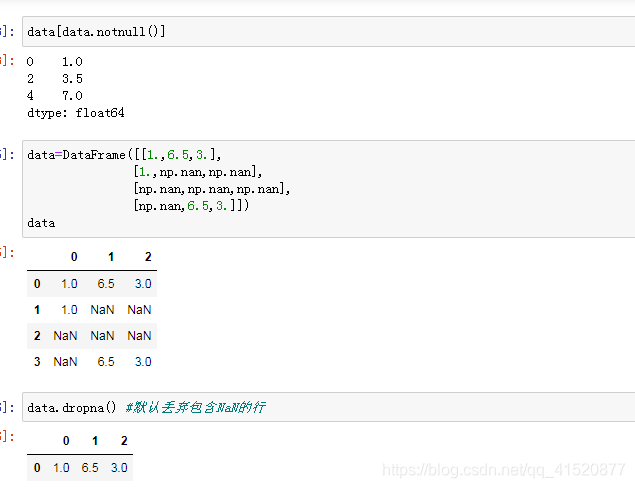
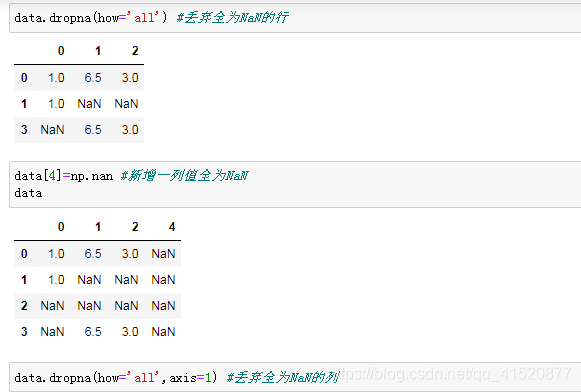
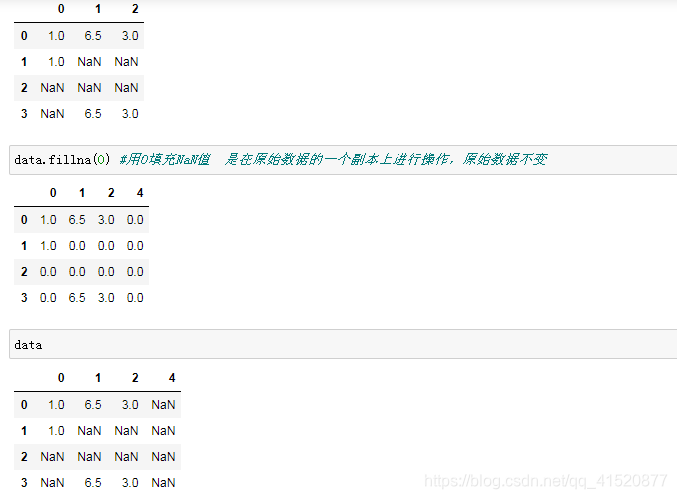
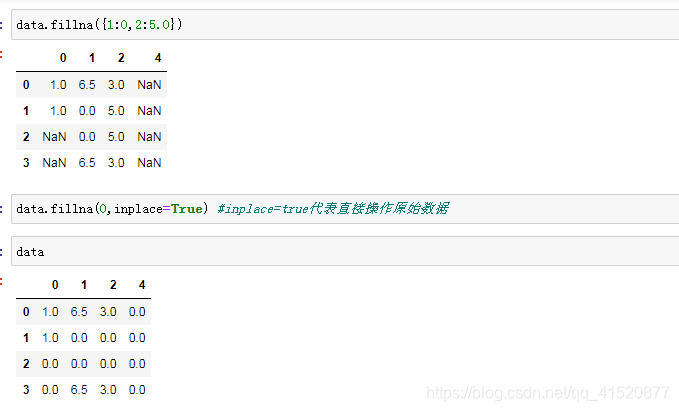
八、缺失值的处理
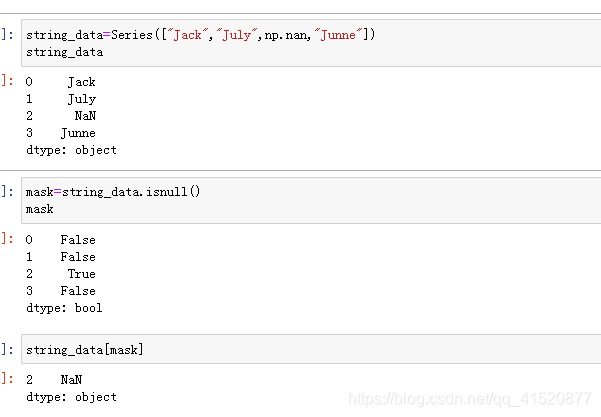
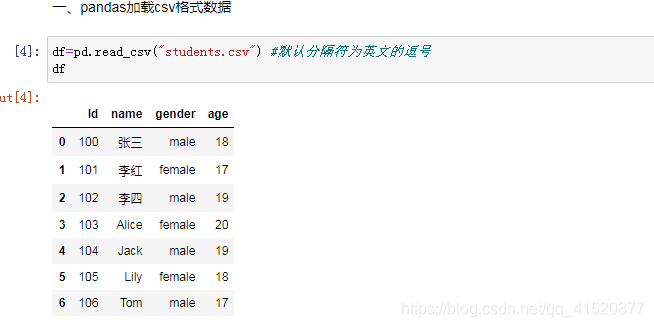
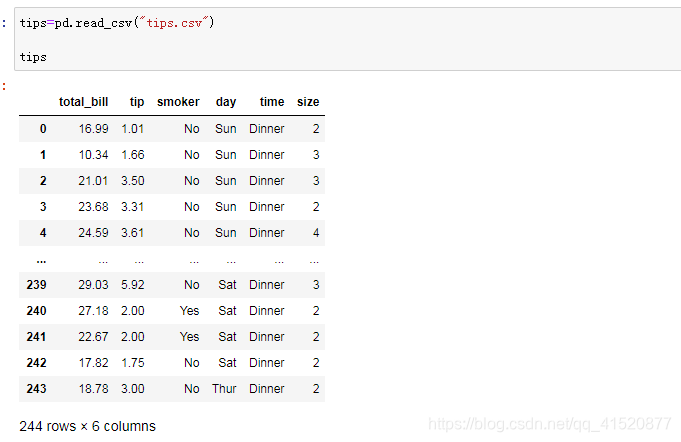
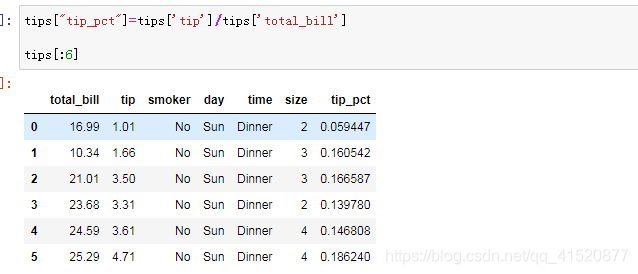
九 加载数据
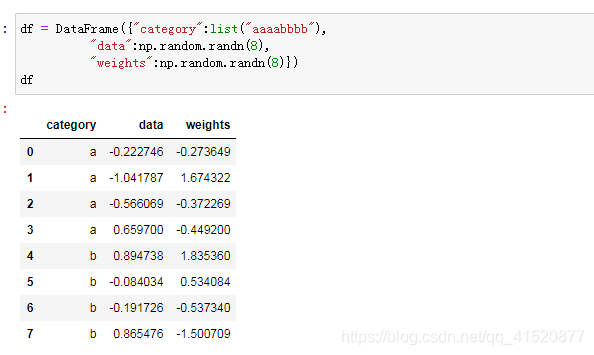
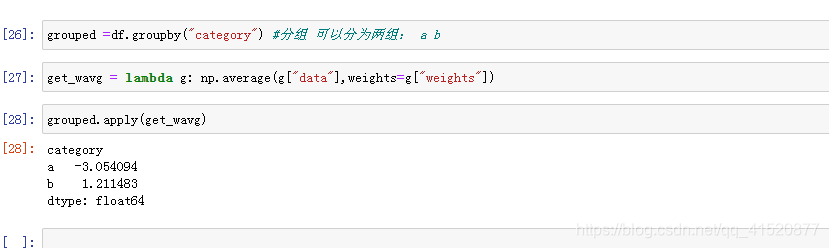
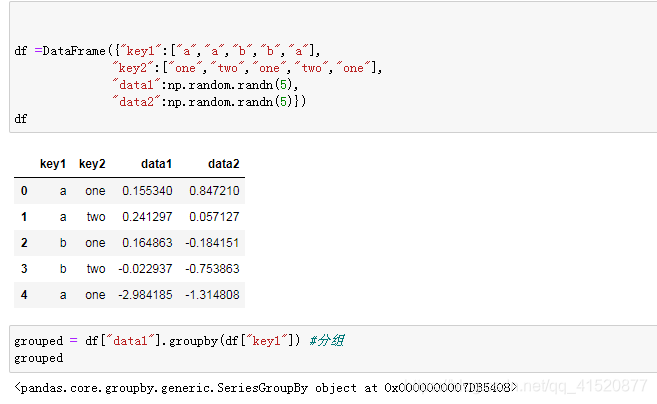
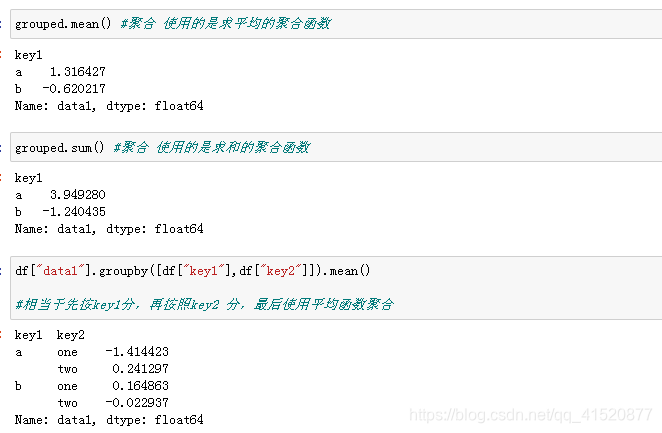
十 分组和聚合
十一 加权平均