简介
R-CNN的全称是Region-CNN,它可以说是是第一个成功将深度学习应用到目标检测上的算法。它是2014年发布的一篇论文,题目是 《Rich feature hierarchies for accurate oject detection and semantic segmentation》,通俗地来讲就是一个用来做目标检测和语义分割的神经网络。
原论文地址:https://arxiv.org/pdf/1311.2524.pdf
一、背景
在过去的十多年时间里,传统的机器视觉领域,通常采用特征描述子来应对目标识别任务,这些特征描述子最常见的就是 SIFT 和 HOG。 一般可以在图片上使用穷举法选出所所有物体可能出现的区域框,对这些区域框提取特征并使用图像识别方法分类, 得到所有分类成功的区域后,通过非极大值抑制(Non-maximumsuppression)输出结果。
R-CNN遵循传统目标检测的思路,同样采用提取框,对每个框提取特征、图像分类、 非极大值抑制四个步骤进行目标检测。只不过在提取特征这一步,将传统的特征(如 SIFT、HOG 特征等)换成了深度卷积网络提取的特征。
二、思路
受 AlexNet 启发,论文作者尝试将 AlexNet 在 ImageNet 目标识别的能力泛化到PASCAL VOC目标检测上面来。但一切开始之前,需要解决两个主要的问题。
- 如何利用深度的神经网络去做目标的定位?
- 如何在一个小规模的数据集上训练能力强劲的网络模型?
1、利用候选区域与 CNN 结合做目标定位。
借鉴了滑动窗口思想,R-CNN 采用对区域进行识别的方案:
- 给定一张输入图片,从图片中提取 2000 个类别独立的候选区域。
- 对每个候选区域,使用深度网络提取特征 (一个固定长度的特征向量)。
- 特征送入每一类的SVM 分类器,判别是否属于该类。
- 使用回归器精细修正候选框位置 。
2、利用预训练与微调解决标注数据缺乏的问题。
采用在 ImageNet 上已经训练好的模型,然后在 PASCAL VOC 数据集上进行fine-tune。
因为 ImageNet 的图像高达几百万张,利用卷积神经网络充分学习浅层的特征,然后在小规模数据集做规模化训练,从而可以达到好的效果。现在,我们称之为迁移学习,是必不可少的一种技能。
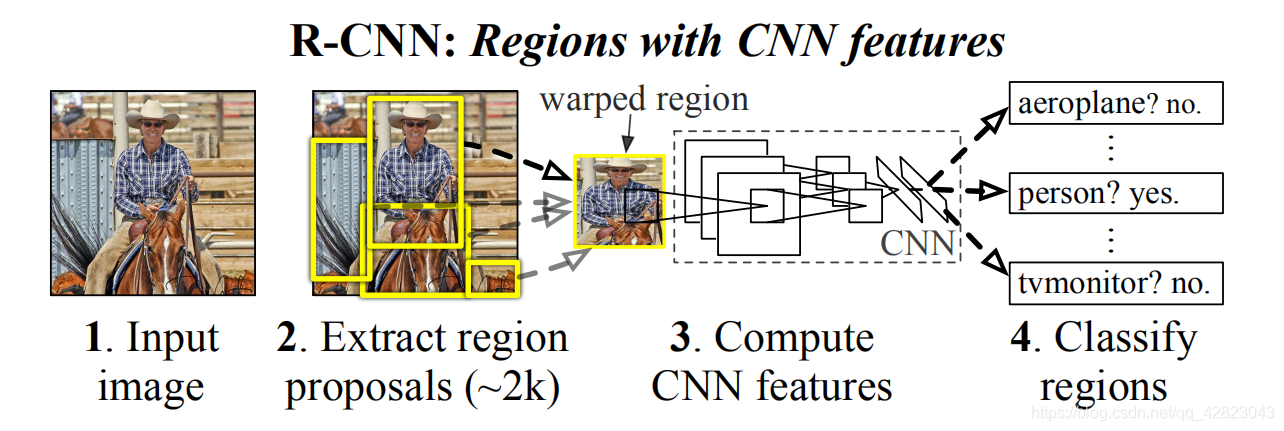
三、原理
1、候选区域生成阶段:
使用了Selective Search1方法从一张图像生成约2000-3000个候选区域。基本步骤如下:
– 使用一种过分割手段,将图像分割成小区域
– 查看现有小区域,合并可能性最高的两个区域。重复直到整张图像合并成一个区域位置
– 输出所有曾经存在过的区域,所谓候选区域
候选区域生成和后续步骤相对独立,实际可以使用任意算法进行。
2、CNN特征提取阶段:
物体检测的一个难点在于,物体标签训练数据少,如果要直接采用随机初始化CNN参数的方法,那么目前的训练数据量是远远不够的。这种情况下,最好的是采用某些方法,把参数初始化了,然后在进行有监督的参数微调,这边文献采用的是有监督的预训练。所以paper在设计网络结构的时候,是直接用Alexnet的网络,然后连参数也是直接采用它的参数,作为初始的参数值,然后再fine-tuning训练。
需要注意的是预训练的Alextnet 的输入图像大小是 227x227。而通过 Selective Search 产生的候选区域大小不一,为了与 Alexnet 兼容,R-CNN 采用了非常暴力的手段,那就是无视候选区域的大小和形状,统一变换到 227*227 的尺寸。有一个细节,在对 Region 进行变换的时候,首先对这些区域进行膨胀处理,在其 box 周围附加了 p 个像素,也就是人为添加了边框,在这里 p=16。
继续对上面预训练的cnn模型进行fine-tuning训练。假设要检测的物体类别有N类,那么我们就需要把上面预训练阶段的CNN模型的最后一层给替换掉,替换成N+1个输出的神经元(加1,表示还有一个背景),然后这一层直接采用参数随机初始化的方法,其它网络层的参数不变;接着就可以开始继续SGD训练了。
注:CNN在训练的时候,对训练数据做了比较宽松的标注,比如一个bounding box可能只包含物体的一部分,那么我也把它标注为正样本,用于训练CNN;采用这个方法的主要原因在于因为CNN容易过拟合,所以需要大量的训练数据,所以在CNN训练阶段我们是对Bounding box的位置限制条件限制的比较松(IOU只要大于0.5都被标注为正样本了);然而svm训练的时候,因为svm适用于少样本训练,所以对于训练样本数据的IOU要求比较严格,我们只有当bounding box把整个物体都包含进去了,我们才把它标注为物体类别,然后训练svm。
3、SVM训练、测试阶段:
这是一个二分类问题,我么假设我们要检测车辆。我们知道只有当bounding box把整量车都包含在内,那才叫正样本;如果bounding box 没有包含到车辆,那么我们就可以把它当做负样本。但问题是当我们的检测窗口只有部分包好物体,那该怎么定义正负样本呢?作者测试了IOU阈值各种方案数值0,0.1,0.2,0.3,0.4,0.5。最后通过训练发现,如果选择IOU阈值为0.3效果最好,即当重叠度小于0.3的时候,我们就把它标注为负样本。一旦CNN f7层特征被提取出来,那么我们将为每个物体累训练一个svm分类器。当我们用CNN提取2000个候选框,可以得到2000 * 4096这样的特征向量矩阵,然后我们只需要把这样的一个矩阵与svm权值矩阵4096 * N点乘(N为分类类别数目,因为我们训练的N个svm,每个svm包好了4096个W),就可以得到结果了。
IOU的定义:
IOU定义了两个bounding box的重叠度,如下图所示: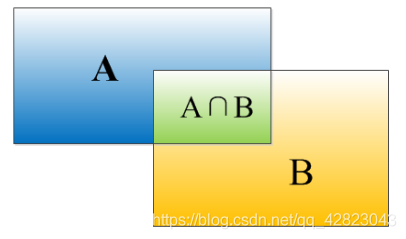
矩形框A、B的一个重合度IOU计算公式为:IOU=(A∩B)/(A∪B)
就是矩形框A、B的重叠面积占A、B并集的面积比例: IOU=SI/(SA+SB-SI)
非极大值抑制:
从一张图片中找出n多个可能是物体的矩形框,然后为每个矩形框为做类别分类概率:
就像上面的图片一样,定位一个车辆,最后算法就找出了一堆的方框,我们需要判别哪些矩形框是没用的。非极大值抑制:先假设有6个矩形框,根据分类器类别分类概率做排序,从小到大分别属于车辆的概率分别为A、B、C、D、E、F。
(1)从最大概率矩形框F开始,分别判断A~E与F的重叠度IOU是否大于某个设定的阈值;
(2)假设B、D与F的重叠度超过阈值,那么就扔掉B、D;并标记第一个矩形框F,是我们保留下来的。
(3)从剩下的矩形框A、C、E中,选择概率最大的E,然后判断E与A、C的重叠度,重叠度大于一定的阈值,那么就扔掉;并标记E是我们保留下来的第二个矩形框。
就这样一直重复,找到所有被保留下来的矩形框。
算法基本步骤和代码:https://blog.csdn.net/zhangyoufei9999/article/details/80406423
系列传送门:
目标检测——Fast R-CNN(二)
目标检测——Faster R-CNN(三)
目标检测——Mask R-CNN(四)
目标检测——R-FCN(五)
目标检测——YOLOv3(六)
目标检测——YOLOv4(七)