简介
Mask R-CNN是ICCV 2017的best paper,彰显了机器学习计算机视觉领域在2017年的最新成果。在机器学习2017年的最新发展中,单任务的网络结构已经逐渐不再引人瞩目,取而代之的是集成,复杂的多任务网络模型。文章的主要思路就是把原有的Faster R-CNN进行扩展,添加一个分支使用现有的检测对目标进行并行预测。
原论文地址:https://arxiv.org/pdf/1703.06870v3
一、整体框架
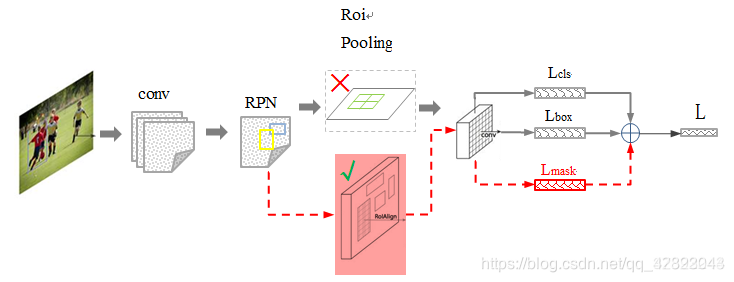
Mask R-CNN是在Faster R-CNN的基础上添加了一个预测分割mask的分支,如上图所示。其中黑色部分为原来的Faster-RCNN,红色部分为在Faster-RCNN网络上的修改。将RoI Pooling 层替换成了RoIAlign层;添加了并列的FCN层(mask层)。
二、ROI Align的基本原理
- ROI Pooling的局限性:
首先介绍一下RoI Pooling,它的目的是为了根据预选框的位置坐标在特征图中将相应区域池化为固定尺寸的特征图,以便进行后续的分类和包围框回归操作。但是在模型中,回归模型得到的坐标都是浮点数,而池化后的特征图要求尺寸固定,为此ROI Pooling进行了两次量化操作。
1、将候选框边框量化为整数坐标。
2、将量化后的边界区域平均分成k * k个单元,对每一个单元的边界进行量化。
在经过这两次量化后,此时的边框已经和最开始回归得到的坐标有了一定的偏差,这个偏差会影响检测或分割的准确度,这就是misalignment的问题。
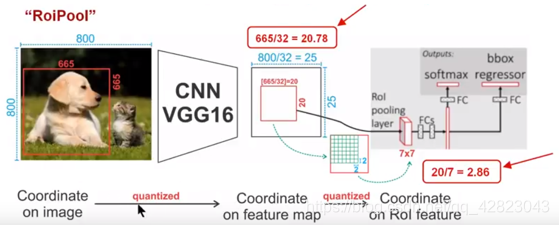
下面举个例子,下图中的图片长宽为800800,其中有一个665665的包围框,经过VGG16特征图缩放到原来的原来的1/32,其中800/32=25,但是665/32=20.78,ROI Pooling直接把它量化为20。接下来把框内的特征池化为77这么大,因此将上述包围框平均分割成77个矩形区域。显然,每个矩形区域的边长为2.86,ROI Pooling直接把它量化为2。经过这两次量化,候选区域已经出现了明显的偏差(图中绿色的部分)。更重要的是,在该层特征图上0.1个像素偏差,缩放到原图就是3.2个,那么0.8的偏差在原图上就是接近30个像素点的偏差,这一点差别不容小觑。
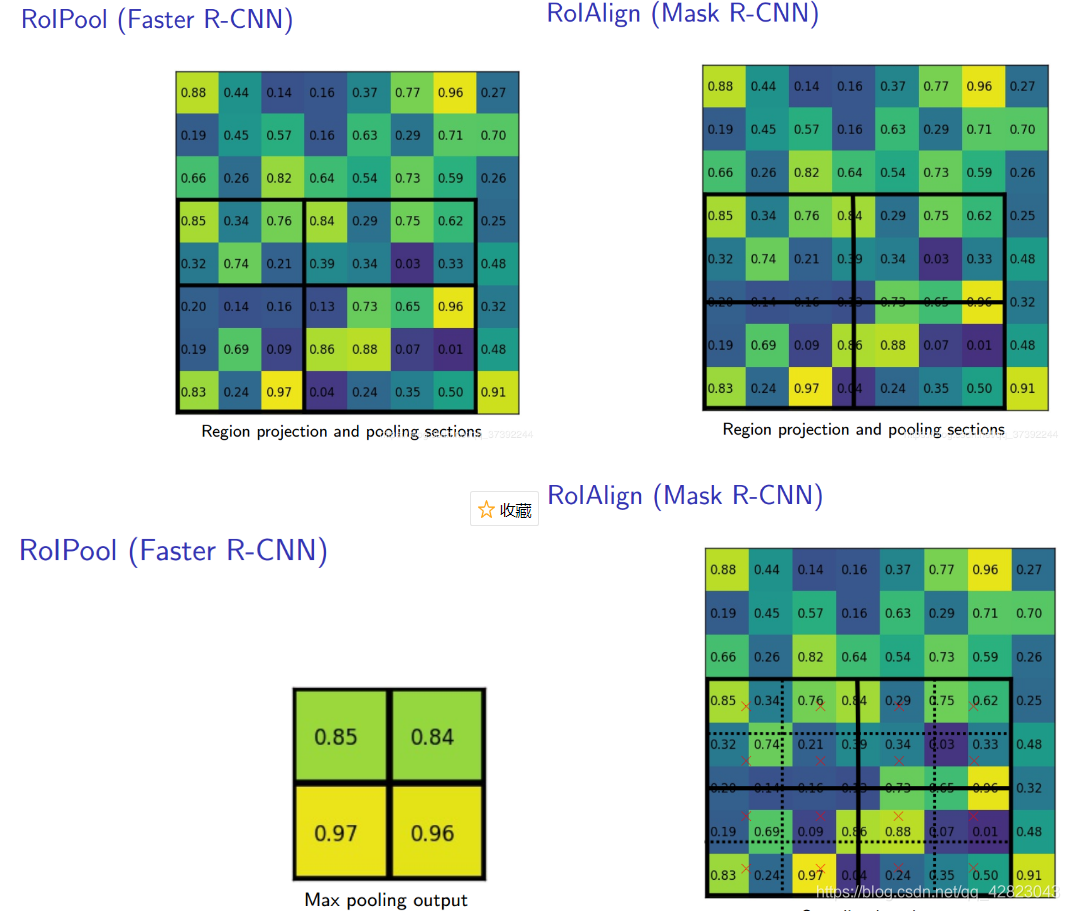
- ROI Align的主要思想和方法(取消了量化操作!)
- 遍历每一个候选区域,保持浮点数边界不做量化。
- 将候选区域分割成k * k个单元,每个单元的边界也不做量化。
- 将每个单元中计算固定四个坐标位置,用双线性插值的方法计算出这四个位置的值,然后进行最大池化操作。
双线性插值是一种比较好的图像缩放算法,它充分的利用了原图中虚拟点(比如20.56这个浮点数,像素位置都是整数值,没有浮点值)四周的四个真实存在的像素值来共同决定目标图中的一个像素值,即可以将20.56这个虚拟的位置点对应的像素值估计出来。
系列传送门:
目标检测——R-CNN(一)
目标检测——Fast R-CNN(二)
目标检测——Faster R-CNN(三)
目标检测——R-FCN(五)
目标检测——YOLOv3(六)
目标检测——YOLOv4(七)