假设一个公司只有一个老板,现在有n个人,而且知道这些人之间的一些关系。我们想知道他们属于几个公司,以及判断任意指定的两个人是不是属于同一个公司的问题。
在初始状态中,我们可以认为每个人都是自己的老板。在这里,某个人是老板的唯一标志:他的编号与他的老板编号 (头顶上的编号) 相同。
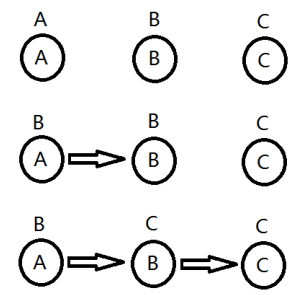
接下去开始合并。
第一步:A和B进行合并,我们假设编号比较大的人作为老板。那么B就是A的老板,当然,B还是B自己的老板。
第二步:B和C进行合并。C是B的老板。
如果我们这时查找A的老板,我们可以发现A的老板是B,但B说自己已经不当老板好多年了,C才是老板,于是再去找C。C说:“不错,我就是你的老板,赶紧去乖乖的干活。”于是我们确认A的老板是C。这是一个递归的过程。
我们把这个过程用代码表示:
int findBoss(int i) //找i的老板
{
//如果自己和自己的老板是同一个人,说明找到老板了
if(arr[i] == i)
{
return i; //返回老板的编号即可
}
//如果i不是老板,那递归就查找i的老板是不是最终的老板
return findBoss(arr[i]); //递归找老板的编号
}
这个过程的时间复杂度为O(N)。下面对这个过程进行优化:
我们发现,在A => B => C这个过程结束时,可以让A直接记住自己的老板是C,而不是每次都通过B再找到C。这样就相当于压缩了查找路径,提高了查找效率。

如果在上述B => C <= A的基础上,继续让C与D合并,D变成C的老板。这时如果通过A => C => D这个路径找老板,我们可以把D设置为A的老板。但是这时B的直接领导仍然是C,而不是D。需要再次访问B => C => D之后,才能确定B的真正老板。当所有人的关系都最终确定之后,这个结构就变成了一对多的树状结构:老板是树根,其他人都是叶子。所以从树叶找老板 (树根) 的时间复杂度为 O(1)。但是在确定所有的关系之前,时间复杂度为O(N)。优化之前,任何查找老板的时间复杂度都为 O(N),显然优化之后的查找效率更高。

上面的过程说起来挺麻烦,但是其实只需要在原来的基础上修改两行内容就可以了,代码实现如下:
int findBoss(int i) //找i的老板
{
//如果自己和自己的老板是同一个人,说明找到老板了
if(arr[i] == i)
{
return i; //返回老板的编号即可
}
//在递归找老板时,顺便把查找路径上的arr[i]的值改成真正的老板的编号
arr[i] = findBoss(arr[i]); //压缩路径,提高效率
return arr[i]; //返回老板的编号
}
有了查找老板的函数之后,我们就可以很容易的判断两个人是不是在同一个公司。只要分别查找两个人对应的老板,然后比较一下这两个人的老板是不是同一个人即可。代码如下:
void isInSameCompany(int a, int b) //判断两个数是不是属于同一个集合
{
int bossA = findBoss(a); //找a的老板
int bossB = findBoss(b); //找b的老板
//如果两个老板是同一个人,说明已经是同一个公司的了
if(bossA == bossB)
{
printf("%d和%d是同一个公司的。\r\n", a, b);
}
else
{
printf("%d和%d不是同一个公司的。\r\n", a, b);
}
}
合并两个人的归属时,我们需要确定一下这两个人的老板是不是同一个人。如果是同一个人,那就说明这两个人已经在同一个公司了,不需要合并了;如果他们的老板不是同一个人,那么就合并一下。代码如下:
int merge(int a, int b) //合并两个人的归属
{
int bossA = findBoss(a); //找a的老板
int bossB = findBoss(b); //找b的老板
//如果两个老板是同一个人,说明已经是同一个公司的了,不需要合并
if(bossA == bossB)
{
return 0; //不合并,返回0
}
//如果两个老板不是同一个人,说明需要合并一下
//就是把其中一个老板(bossB)的值改成bossA
//也就是把bossA设定为bossB的老板
else
{
arr[bossB] = bossA;
return 1; //合并,返回1
}
}
下面是完整的并查集代码:
#include <stdio.h>
#include <stdlib.h>
int size = 10;
int arr[10];
void init() //初始化
{
// 每一个人都是自己的老板
for(int i = 1; i < size; i++)
{
arr[i] = i;
}
}
int findBoss(int i) //找i的老板
{
//如果自己和自己的老板是同一个人,说明找到老板了
if(arr[i] == i)
{
return i; //返回老板的编号即可
}
//否则就要递归找老板。顺便把arr[i]的值改了,改成真正的老板的编号
arr[i] = findBoss(arr[i]); //压缩路径,提高效率
return arr[i]; //返回老板的编号
}
int merge(int a, int b) //合并两个人的归属
{
int bossA = findBoss(a); //找a的老板
int bossB = findBoss(b); //找b的老板
//如果两个老板是同一个人,说明已经是同一个公司的了,不需要合并
if(bossA == bossB)
{
return 0;
}
//如果两个老板不是同一个人,说明需要合并一下
//就是把其中一个老板(bossB)的值改成bossA
//也就是把bossA设定为bossB的老板
else
{
arr[bossB] = bossA;
return 1;
}
}
void isInSameCompany(int a, int b) //判断两个数是不是属于同一个集合
{
int bossA = findBoss(a); //找a的老板
int bossB = findBoss(b); //找b的老板
//如果两个老板是同一个人,说明已经是同一个公司的了
if(bossA == bossB)
{
printf("%d和%d是同一个公司的。\r\n", a, b);
}
else
{
printf("%d和%d不是同一个公司的。\r\n", a, b);
}
}
int main()
{
int count = 0; //记录有几个公司
init(); //初始化
merge(1, 2); //合并1和2
merge(1, 3);
merge(3, 4);
merge(4, 5);
merge(1, 6);
merge(2, 6);
merge(7, 8);
merge(7, 9);
//遍历。如果某个人就是他自己的老板,那么这个人一定是老板。
//由于一个公司只有一个老板。所有有几个老板,就有几个公司。
for(int i = 1; i < size; i++)
{
if(arr[i] == i) //如果某个人就是他自己的老板
{
count++; //计数,一共有几个老板
}
}
printf("一共有几个公司:count = %d。\r\n", count); //显示一共有几个老板,几个公司
isInSameCompany(3, 9); //判断两个数是不是属于同一个集合
isInSameCompany(4, 6);
return 0;
}
主函数中各元素之间的关系如下:
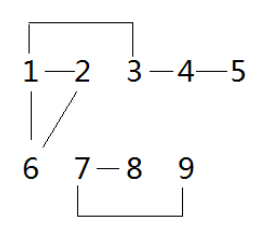
运行结果如下:

并查集算法中的查找老板的算法效率是很高的,而且存在多次查询后,效率进一步提升的情况。时间复杂度最终降低到O(1)。具体的中间状态请读者自己实现吧。
并查集算法主要是用来判断两个元素是否属于同一个集合。它在Kruskal算法中也有应用。Kruskal算法用来计算图的最小生成树,这部分内容我们将在图的章节中进行讲解。