上个课时我们介绍了网页防护技术,包括接口加密和 JavaScript 压缩、加密和混淆。这就引出了一个问题,如果我们碰到了这样的网站,那该怎么去分析和爬取呢?
本课时我们就通过一个案例来介绍一下这种网站的爬取思路,本课时介绍的这个案例网站不仅在 API 接口层有加密,而且前端 JavaScript 也带有压缩和混淆,其前端压缩打包工具使用了现在流行的 Webpack,混淆工具是使用了 javascript-obfuscator,这二者结合起来,前端的代码会变得难以阅读和分析。
如果我们不使用 Selenium 或 Pyppeteer 等工具来模拟浏览器的形式爬取的话,要想直接从接口层面上获取数据,基本上需要一点点调试分析 JavaScript 的调用逻辑、堆栈调用关系来弄清楚整个网站加密的实现方法,我们可以称这个过程叫 JavaScript 逆向。这些接口的加密参数往往都是一些加密算法或编码的组合,完全搞明白其中的逻辑之后,我们就能把这个算法用 Python 模拟出来,从而实现接口的请求了。
案例介绍
案例的地址为:https://dynamic6.scrape.cuiqingcai.com/,页面如图所示。

初看之下并没有什么特殊的,但仔细观察可以发现其 Ajax 请求接口和每部电影的 URL 都包含了加密参数。
比如我们点击任意一部电影,观察一下 URL 的变化,如图所示。
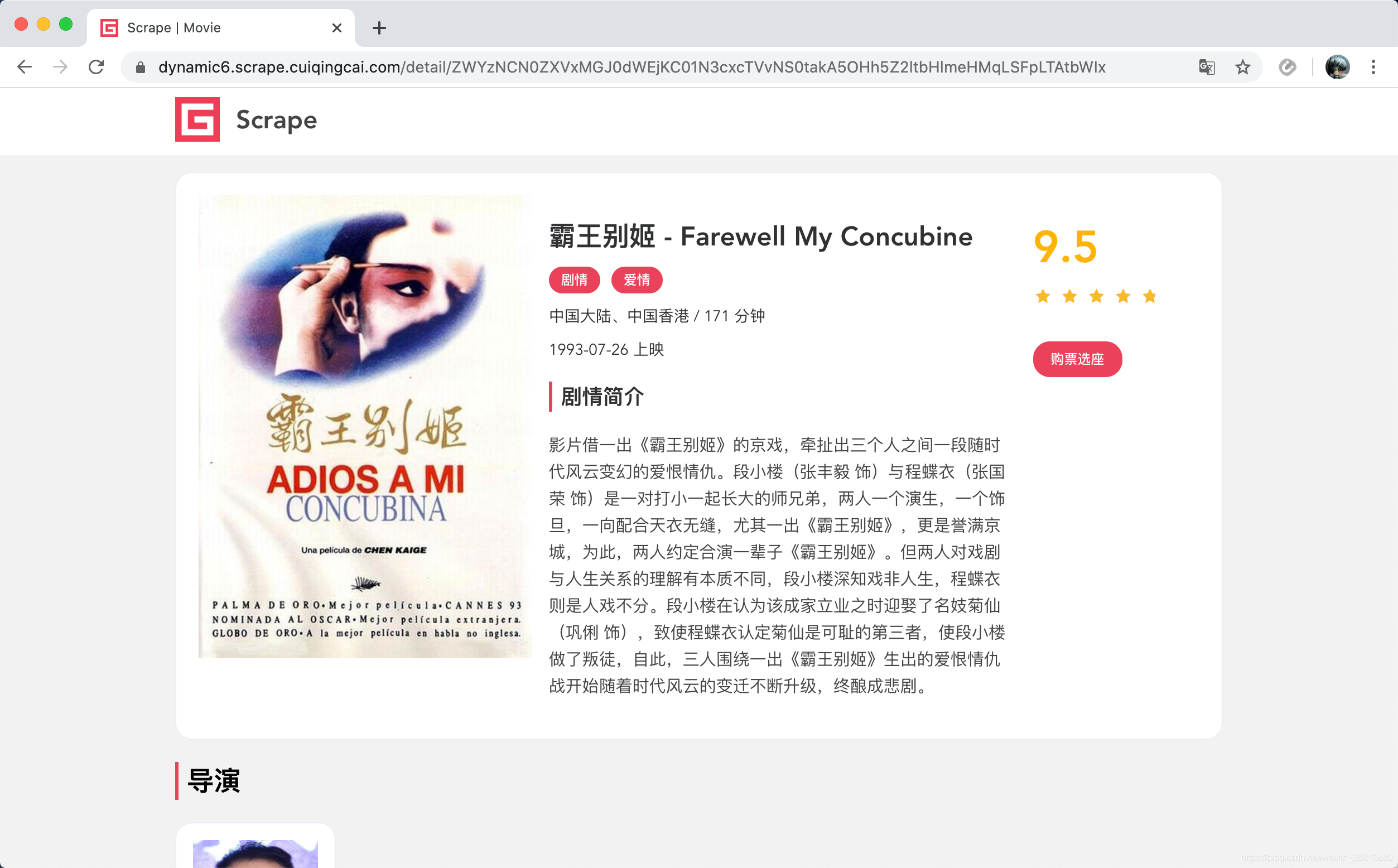
这里我们可以看到详情页的 URL 包含了一个长字符串,看似是一个 Base64 编码的内容。
那么接下来直接看看 Ajax 的请求,我们从列表页的第 1 页到第 10 页依次点一下,观察一下 Ajax 请求是怎样的,如图所示。
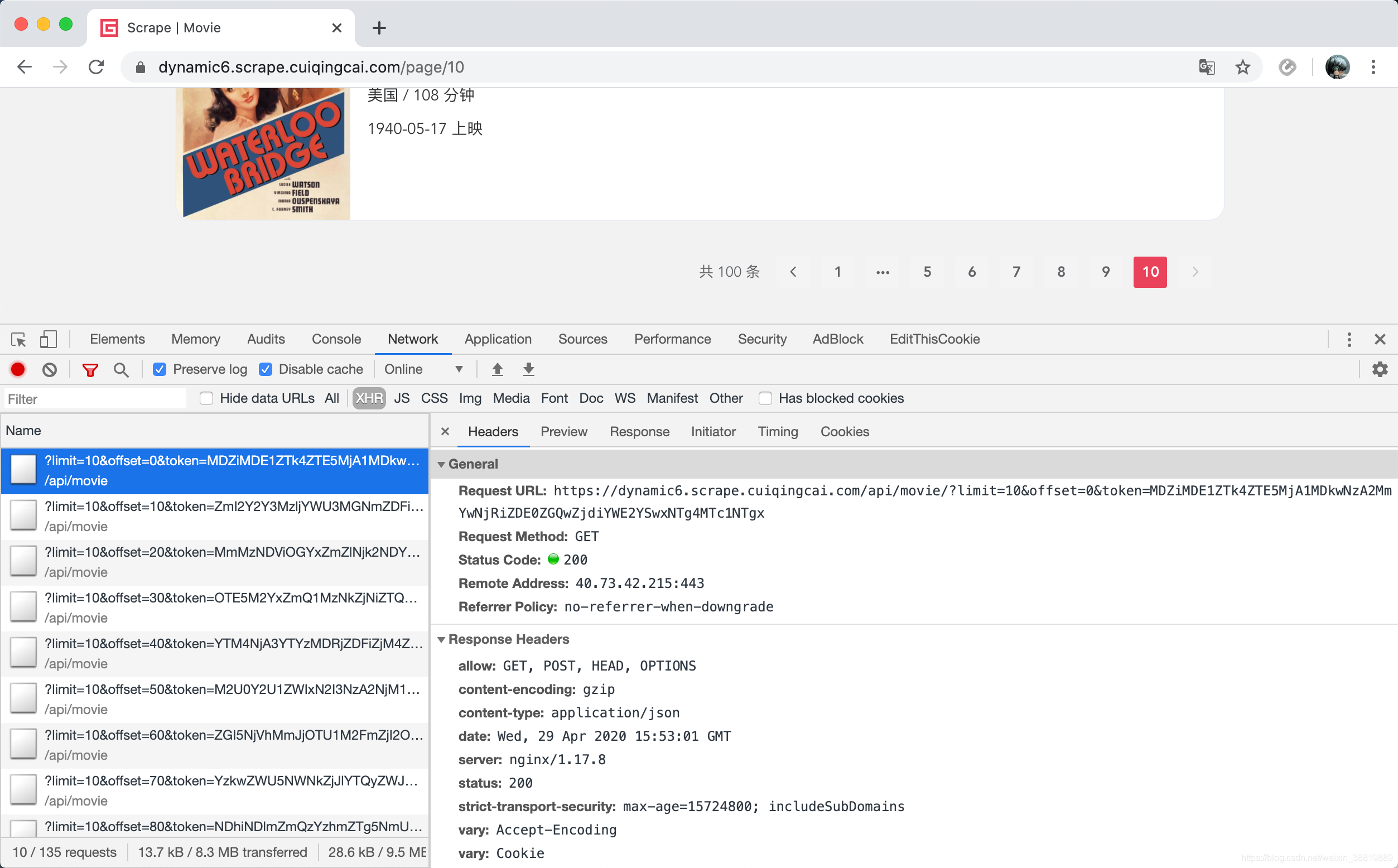
可以看到 Ajax 接口的 URL 里面多了一个 token,而且不同的页码 token 是不一样的,这个 token 同样看似是一个 Base64 编码的字符串。
另外更困难的是,这个接口还是有时效性的,如果我们把 Ajax 接口 URL 直接复制下来,短期内是可以访问的,但是过段时间之后就无法访问了,会直接返回 401 状态码。
接下来我们再看下列表页的返回结果,比如我们打开第一个请求,看看第一部电影数据的返回结果,如图所示。

这里我们把看似是第一部电影的返回结果全展开了,但是刚才我们观察到第一部电影的 URL 的链接却为 https://dynamic6.scrape.cuiqingcai.com/detail/ZWYzNCN0ZXVxMGJ0dWEjKC01N3cxcTVvNS0takA5OHh5Z2ltbHlmeHMqLSFpLTAtbWIx,看起来是 Base64 编码,我们解码一下,结果为 ef34#teuq0btua#(-57w1q5o5–j@98xygimlyfxs*-!i-0-mb1,但是看起来似乎还是毫无规律,这个解码后的结果又是怎么来的呢?返回结果里面也并不包含这个字符串,那这又是怎么构造的呢?
再然后,这仅仅是某一个详情页页面的 URL,其真实数据是通过 Ajax 加载的,那么 Ajax 请求又是怎样的呢,我们再观察下,如图所示。
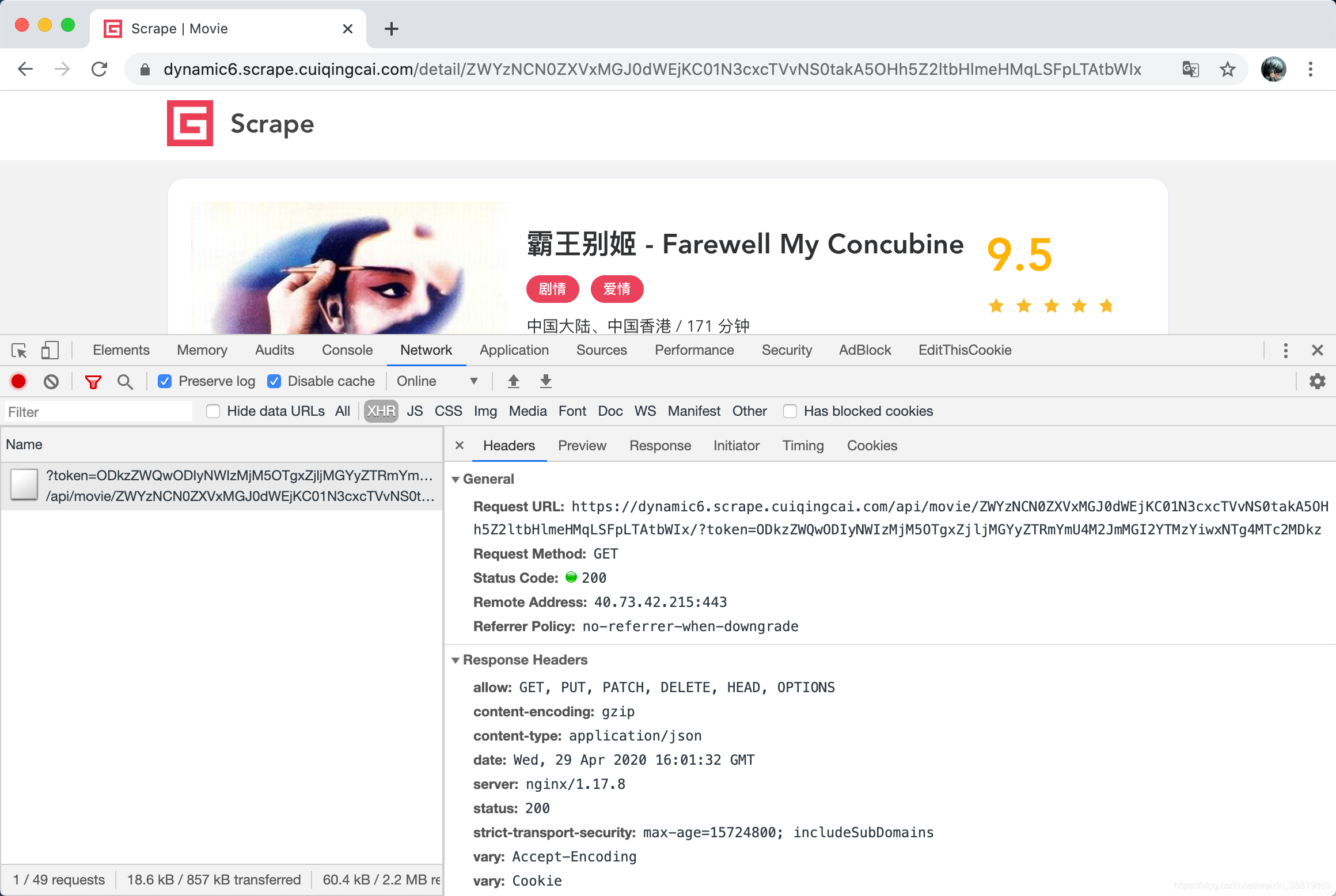
好,这里我们发现其 Ajax 接口除了包含刚才所说的 URL 中携带的字符串,又多了一个 token,同样也是类似 Base64 编码的内容。
那么总结下来这个网站就有如下特点:
- 列表页的 Ajax 接口参数带有加密的 token;
- 详情页的 URL 带有加密 id;
- 详情页的 Ajax 接口参数带有加密 id 和加密 token
那如果我们要想通过接口的形式来爬取,必须要把这些加密 id 和 token 构造出来才行,而且必须要一步步来,首先我们要构造出列表页 Ajax 接口的 token 参数,然后才能获取每部电影的数据信息,然后根据数据信息构造出加密 id 和 token。
OK,到现在为止我们就知道了这个网站接口的加密情况了,我们下一步就是去找这个加密实现逻辑了。
由于是网页,所以其加密逻辑一定藏在前端代码中,但前面我们也说了,前端为了保护其接口加密逻辑不被轻易分析出来,会采取压缩、混淆的方式来加大分析的难度。
接下来,我们就来看看这个网站的源代码和 JavaScript 文件是怎样的吧。
首先看看网站源代码,我们在网站上点击右键,弹出选项菜单,然后点击“查看源代码”,可以看到结果如图所示。
内容如下:
<!DOCTYPE html><html lang=en><head><meta charset=utf-8><meta http-equiv=X-UA-Compatible content="IE=edge"><meta name=viewport content="width=device-width,initial-scale=1"><link rel=icon href=/favicon.ico><title>Scrape | Movie</title><link href=/css/chunk-19c920f8.2a6496e0.css rel=prefetch><link href=/css/chunk-2f73b8f3.5b462e16.css rel=prefetch><link href=/js/chunk-19c920f8.c3a1129d.js rel=prefetch><link href=/js/chunk-2f73b8f3.8f2fc3cd.js rel=prefetch><link href=/js/chunk-4dec7ef0.e4c2b130.js rel=prefetch><link href=/css/app.ea9d802a.css rel=preload as=style><link href=/js/app.5ef0d454.js rel=preload as=script><link href=/js/chunk-vendors.77daf991.js rel=preload as=script><link href=/css/app.ea9d802a.css rel=stylesheet></head><body><noscript><strong>We're sorry but portal doesn't work properly without JavaScript enabled. Please enable it to continue.</strong></noscript><div id=app></div><script src=/js/chunk-vendors.77daf991.js></script><script src=/js/app.5ef0d454.js></script></body></html>
这是一个典型的 SPA(单页 Web 应用)的页面, 其 JavaScript 文件名带有编码字符、chunk、vendors 等关键字,整体就是经过 Webpack 打包压缩后的源代码,目前主流的前端开发,如 Vue.js、React.js 的输出结果都是类似这样的结果。
好,那么我们再看下其 JavaScript 代码是什么样子的,我们在开发者工具中打开 Sources 选项卡下的 Page 选项卡,然后打开 js 文件夹,这里我们就能看到 JavaScript 的源代码,如图所示。
我们随便复制一些出来,看看是什么样子的,结果如下:
\(window\['webpackJsonp'\]=window\['webpackJsonp'\]\|\|\[\]\)\['push'\]\(\[\['chunk\-19c920f8'\]\,\{'5a19':function\(\_0x3cb7c3\,\_0x5cb6ab\,\_0x5f5010\)\{\}\,'c6bf':function\(\_0x1846fe\,\_0x459c04\,\_0x1ff8e3\)\{\}\,'ca9c':function\(\_0x195201\,\_0xc41ead\,\_0x1b389c\)\{'use strict';var \_0x468b4e=\_0x1b389c\('5a19'\)\,\_0x232454=\_0x1b389c['n'](_0x468b4e);\_0x232454['a'];},'d504':...,[\_0xd670a1['\_v'](_0xd670a1%5B'_s'%5D(_0x2227b6)+'%5Cx0a%5Cx20%5Cx20%5Cx20%5Cx20%5Cx20%5Cx20%5Cx20%5Cx20%5Cx20%5Cx20%5Cx20%5Cx20%5Cx20%5Cx20')]);}),0x1),\_0x4ef533('div',{'staticClass':'m-v-sm\x20info'},[\_0x4ef533('span',[\_0xd670a1['\_v'](_0xd670a1%5B'_s'%5D(_0x1cc7eb%5B'regions'%5D%5B'join'%5D('%E3%80%81')))]),\_0x4ef533('span',[\_0xd670a1['\_v']('%5Cx20/%5Cx20')]),\_0x4ef533('span',[\_0xd670a1['\_v'](_0xd670a1%5B'_s'%5D(_0x1cc7eb%5B'minute'%5D)+'%5Cx20%E5%88%86%E9%92%9F')])]),\_0x4ef533('div',...,\_0x4ef533('el-col',{'attrs':{'xs':0x5,'sm':0x5,'md':0x4}},[\_0x4ef533('p',{'staticClass':'score\x20m-t-md\x20m-b-n-sm'},[\_0xd670a1['\_v'](_0xd670a1%5B'_s'%5D(_0x1cc7eb%5B'score'%5D%5B'toFixed'%5D(0x1)))\]\)\,\_0x4ef533\('p'\,\[\_0x4ef533\('el\-rate'\,\{'attrs':\{'value':\_0x1cc7eb\['score'\]/0x2\,'disabled':''\,'max':0x5\,'text\-color':'\#ff9900'\}\}\)\]\,0x1\)\]\)\]\,0x1\)\]\,0x1\);\}\)\,0x1\)\]\,0x1\)\,\_0x4ef533\('el\-row'\,\[\_0x4ef533\('el\-col'\,\{'attrs':\{'span':0xa\,'offset':0xb\}\}\,\[\_0x4ef533\('div'\,\{'staticClass':'pagination\x20m\-v\-lg'\}\,\[\_0x4ef533\('el\-pagination'\,\.\.\.:function\(\_0x347c29\)\{\_0xd670a1\['page'\]=\_0x347c29;\}\,'update:current\-page':function\(\_0x79754e\)\{\_0xd670a1\['page'\]=\_0x79754e;\}\}\}\)\]\,0x1\)\]\)\]\,0x1\)\]\,0x1\);\}\,\_0x357ebc=\[\]\,\_0x18b11a=\_0x1a3e60\('7d92'\)\,\_0x4369=\_0x1a3e60\('3e22'\)\,\.\.\.;var \_0x498df8=\.\.\.\['then'\]\(function\(\_0x59d600\)\{var \_0x1249bc=\_0x59d600\['data'\]\,\_0x10e324=\_0x1249bc\['results'\]\,\_0x47d41b=\_0x1249bc\['count'\];\_0x531b38\['loading'\]=\!0x1\,\_0x531b38\['movies'\]=\_0x10e324\,\_0x531b38\['total'\]=\_0x47d41b;\}\);\}\}\}\,\_0x28192a=\_0x5f39bd\,\_0x5f5978=\(\_0x1a3e60\('ca9c'\)\,\_0x1a3e60\('eb45'\)\,\_0x1a3e60\('2877'\)\)\,\_0x3fae81=Object\(\_0x5f5978\['a'\]\)\(\_0x28192a\,\_0x443d6e\,\_0x357ebc\,\!0x1\,null\,'724ecf3b'\,null\);\_0x6f764c\['default'\]=\_0x3fae81\['exports'\];\}\,'eb45':function\(\_0x1d3c3c\,\_0x52e11c\,\_0x3f1276\)\{'use strict';var \_0x79046c=\_0x3f1276\('c6bf'\)\,\_0x219366=\_0x3f1276['n'](_0x79046c);\_0x219366['a'];}}]);
就是这种感觉,可以看到一些变量都是一些十六进制字符串,而且代码全被压缩了。
没错,我们就是要从这里面找出 token 和 id 的构造逻辑,看起来是不是很崩溃?
要完全分析出整个网站的加密逻辑还是有一定难度的,不过不用担心,我们本课时会一步步地讲解逆向的思路、方法和技巧,如果你能跟着这个过程学习完,相信还是能学会一定的 JavaScript 逆向技巧的。
为了适当降低难度,本课时案例的 JavaScript 混淆其实并没有设置的特别复杂,并没有开启字符串编码、控制流扁平化等混淆方式。
列表页 Ajax 入口寻找
接下来,我们就开始第一步入口的寻找吧,这里简单介绍两种寻找入口的方式:
- 全局搜索标志字符串;
- 设置 Ajax 断点。
全局搜索标志字符串
一些关键的字符串通常会作为找寻 JavaScript 混淆入口的依据,我们可以通过全局搜索的方式来查找,然后根据搜索到的结果大体观察是否是我们想找的入口。
然后,我们重新打开列表页的 Ajax 接口,看下请求的 Ajax 接口,如图所示。
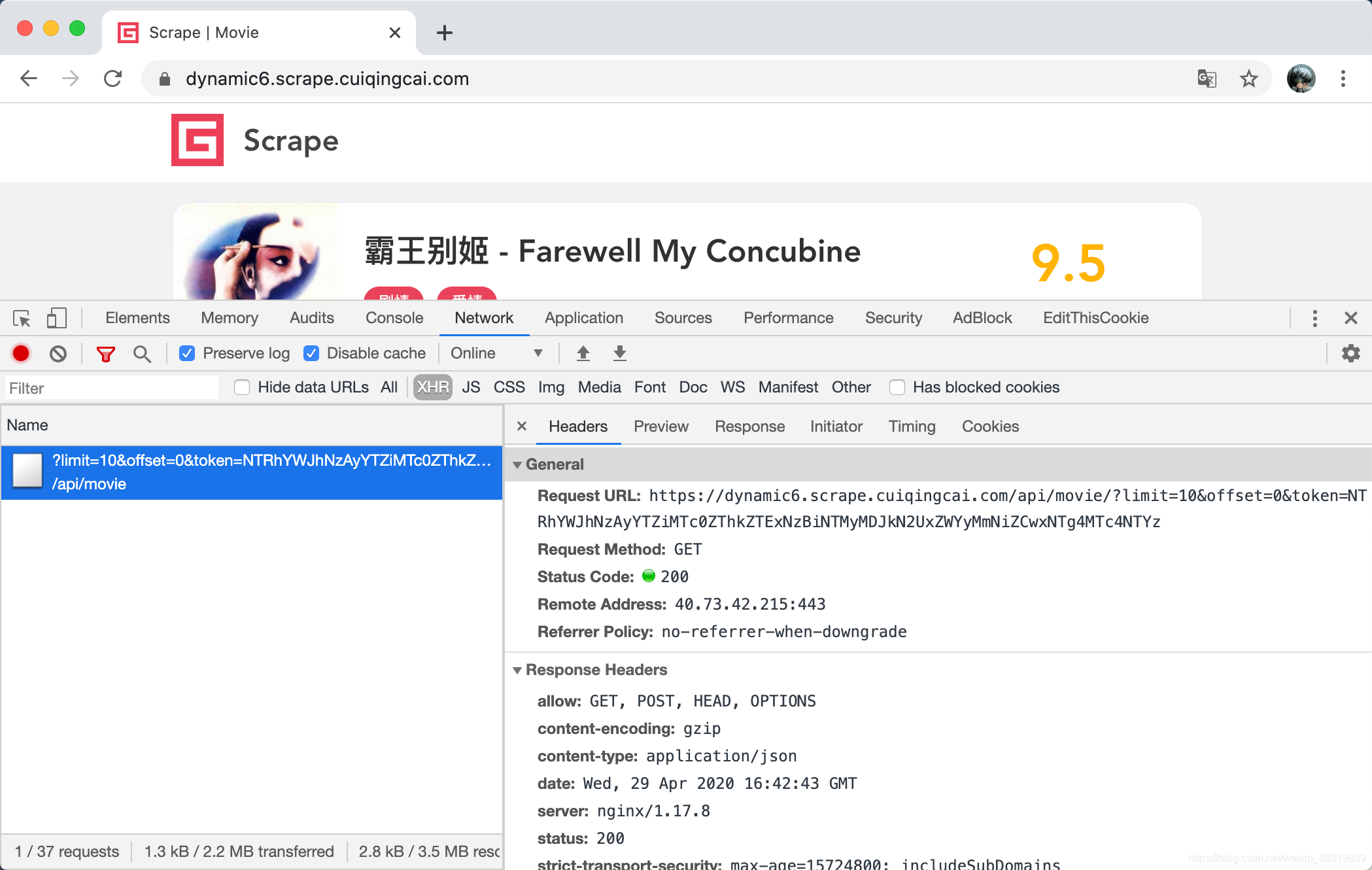
这里的 Ajax 接口的 URL 为 https://dynamic6.scrape.cuiqingcai.com/api/movie/?limit=10&offset=0&token=NTRhYWJhNzAyYTZiMTc0ZThkZTExNzBiNTMyMDJkN2UxZWYyMmNiZCwxNTg4MTc4NTYz,可以看到带有 offset、limit、token 三个参数,入口寻找关键就是找 token,我们全局搜索下 token 是否存在,可以点击开发者工具右上角的下拉选项卡,然后点击 Search,如图所示。
这样我们就能进入到一个全局搜索模式,我们搜索 token,可以看到的确搜索到了几个结果,如图所示。
观察一下,下面的两个结果可能是我们想要的,我们点击进入第一个看下,定位到了一个 JavaScript 文件,如图所示。
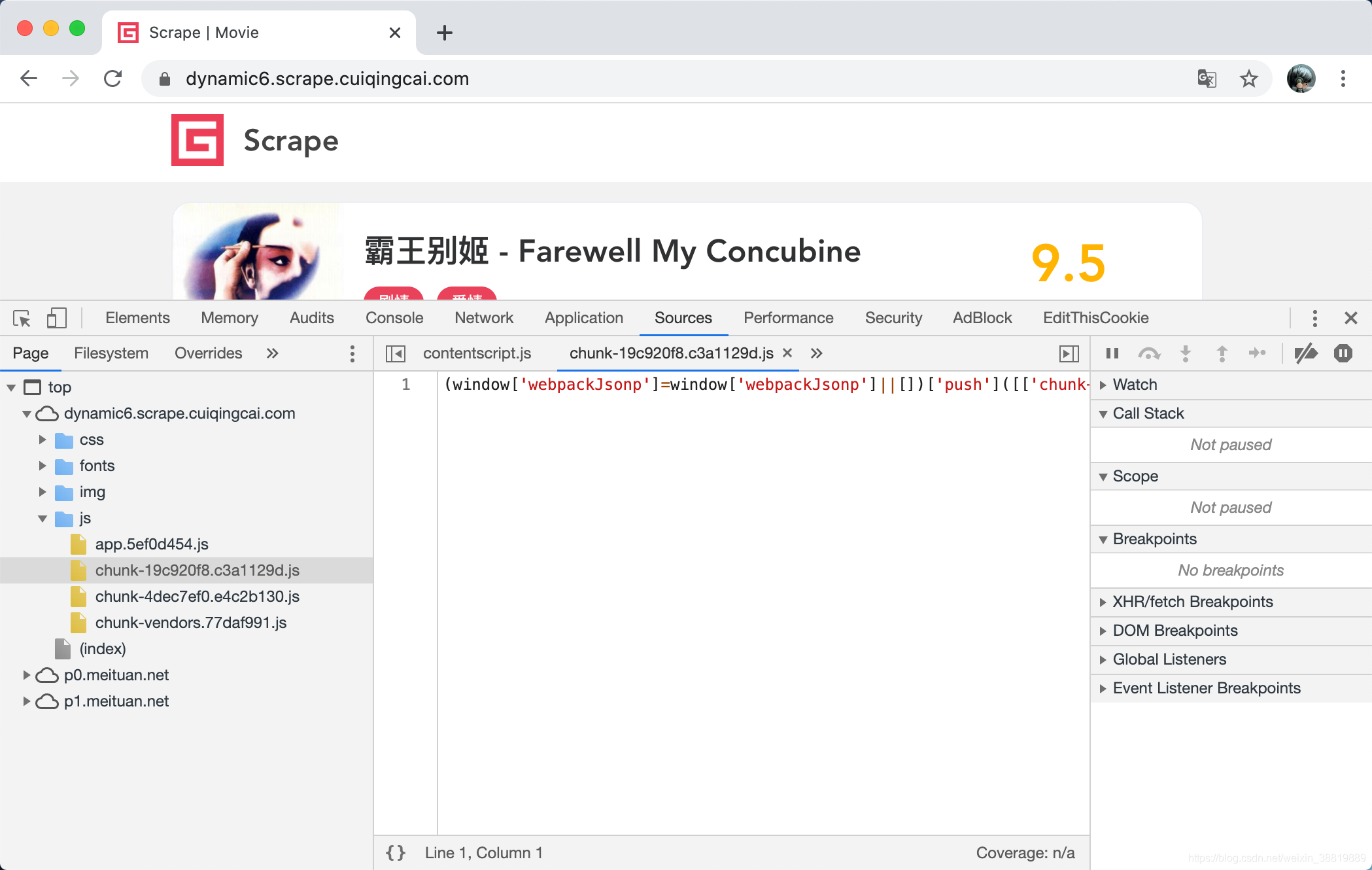
这时候可以看到整个代码都是压缩过的,只有一行,不好看,我们可以点击左下角的 {} 按钮,美化一下 JavaScript 代码,如图所示。

美化后的结果就是这样子了,如图所示。
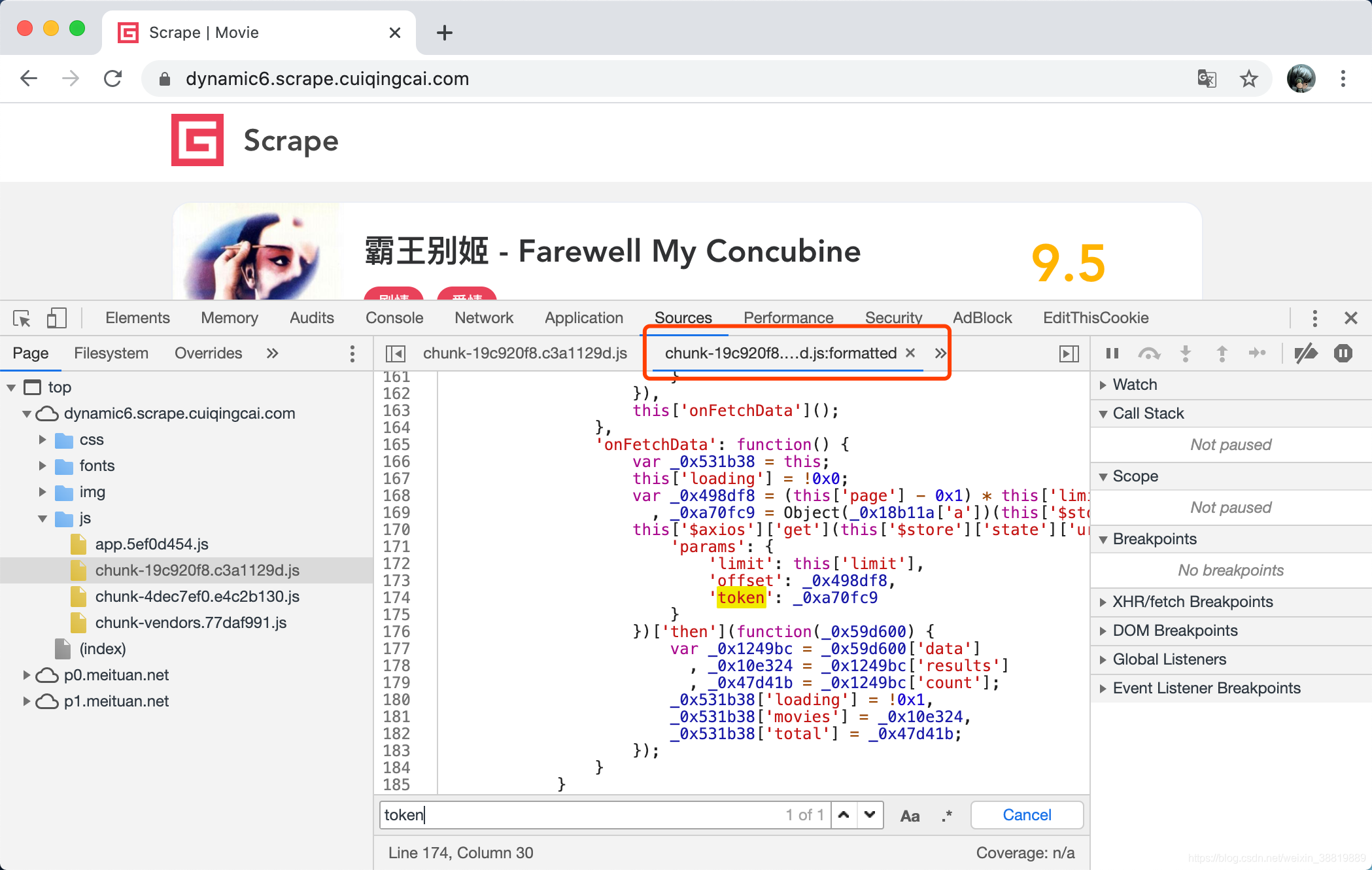
这时可以看到这里弹出来了一个新的选项卡,其名称是 JavaScript 文件名加上了 :formatted,代表格式化后代码结果,在这里我们再次定位到 token 观察一下。
可以看到这里有 limit、offset、token,然后观察下其他的逻辑,基本上能够确定这就是构造 Ajax 请求的地方了,如果不是的话可以继续搜索其他的文件观察下。
那现在,混淆的入口点我们就成功找到了,这是一个首选的找入口的方法。
XHR 断点
由于这里的 token 字符串并没有被混淆,所以上面的这个方法是奏效的。之前我们也讲过,这种字符串由于非常容易成为找寻入口点的依据,所以这样的字符串也会被混淆成类似 Unicode、Base64、RC4 的一些编码形式,这样我们就没法轻松搜索到了。
那如果遇到这种情况,我们该怎么办呢?这里再介绍一种通过打 XHR 断点的方式来寻找入口。
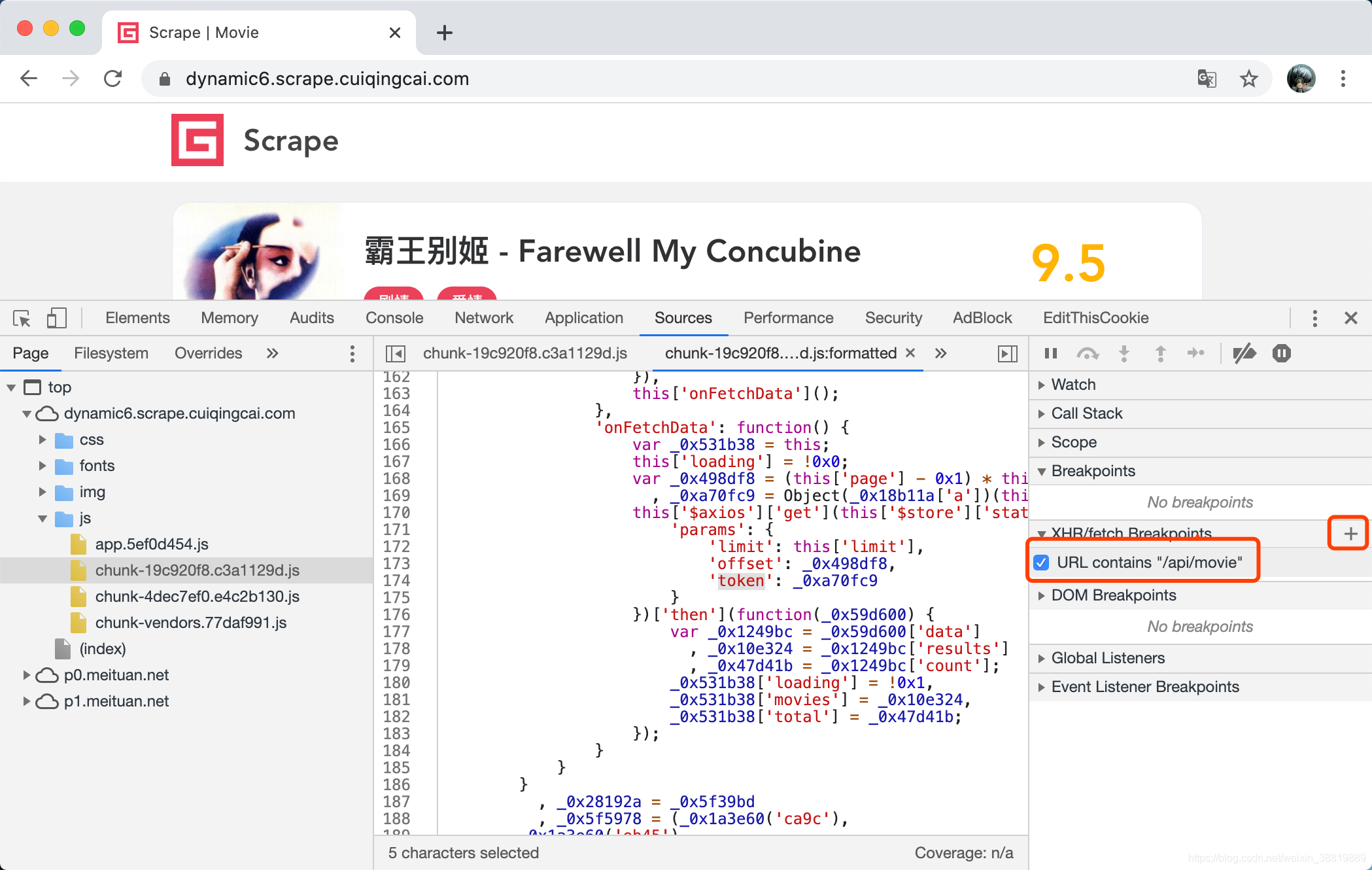
XHR 断点,顾名思义,就是在发起 XHR 的时候进入断点调试模式,JavaScript 会在发起 Ajax 请求的时候停住,这时候我们可以通过当前的调用栈的逻辑顺着找到入口。怎么设置呢?我们可以在 Sources 选项卡的右侧,XHR/fetch Breakpoints 处添加一个断点选项。
首先点击 + 号,然后输入匹配的 URL 内容,由于 Ajax 接口的形式是 /api/movie/?limit=10… 这样的格式,所这里我们就截取一段填进去就好了,这里填的就是 /api/movie,如图所示。
添加完毕之后重新刷新页面,可以发现进入了断点模式,如图所示。
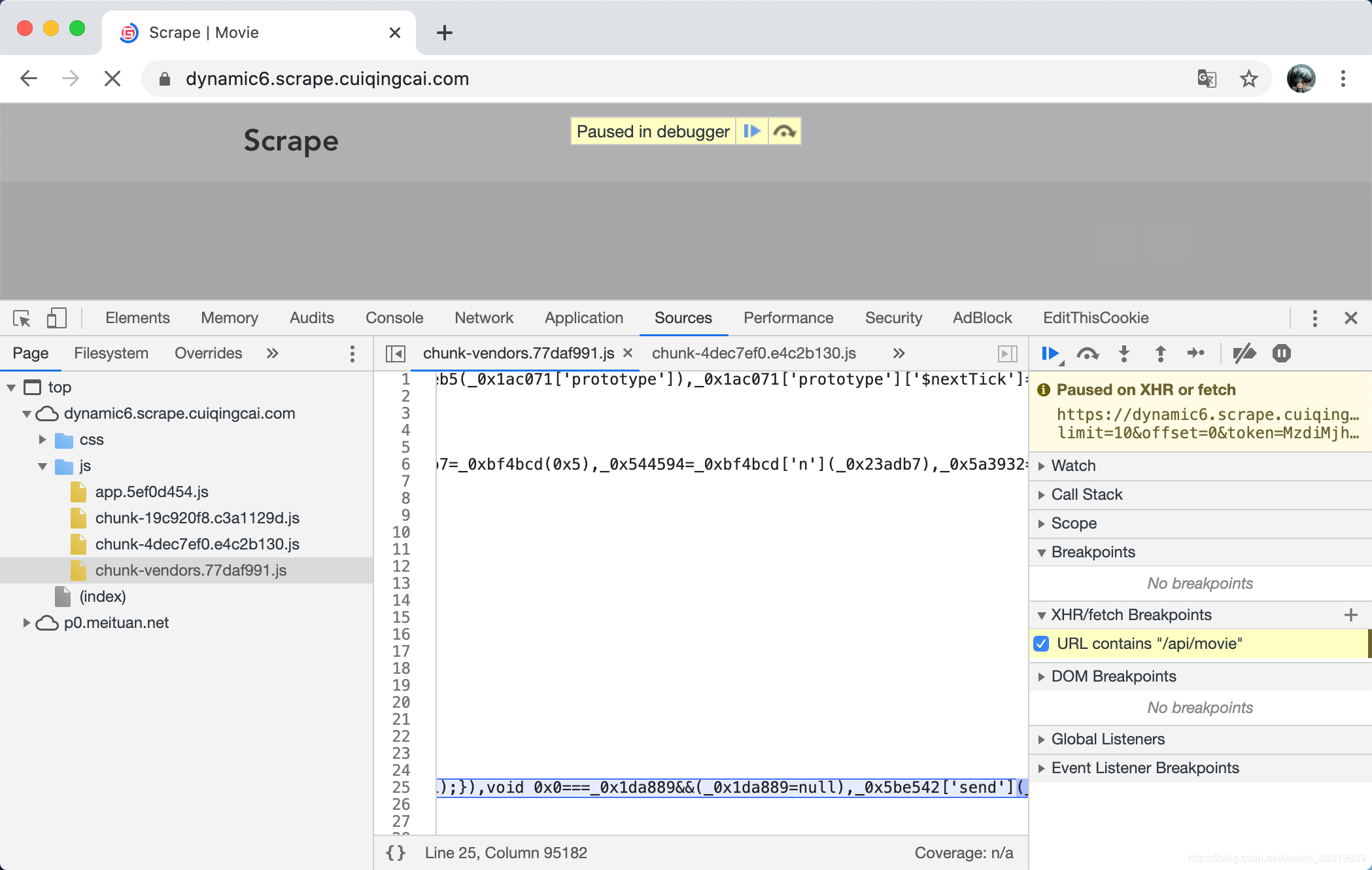
那这里看到有个 send 的字符,我们可以初步猜测这就是相当于发送 Ajax 请求的一瞬间。
到了这里感觉 Ajax 马上就要发出去了,是不是有点太晚了,我们想找的是构造 Ajax 的时刻来分析 Ajax 参数啊!不用担心,这里我们通过调用栈就可以找回去。我们点击右侧的 Call Stack,这里记录了 JavaScript 的方法逐层调用过程,如图所示。
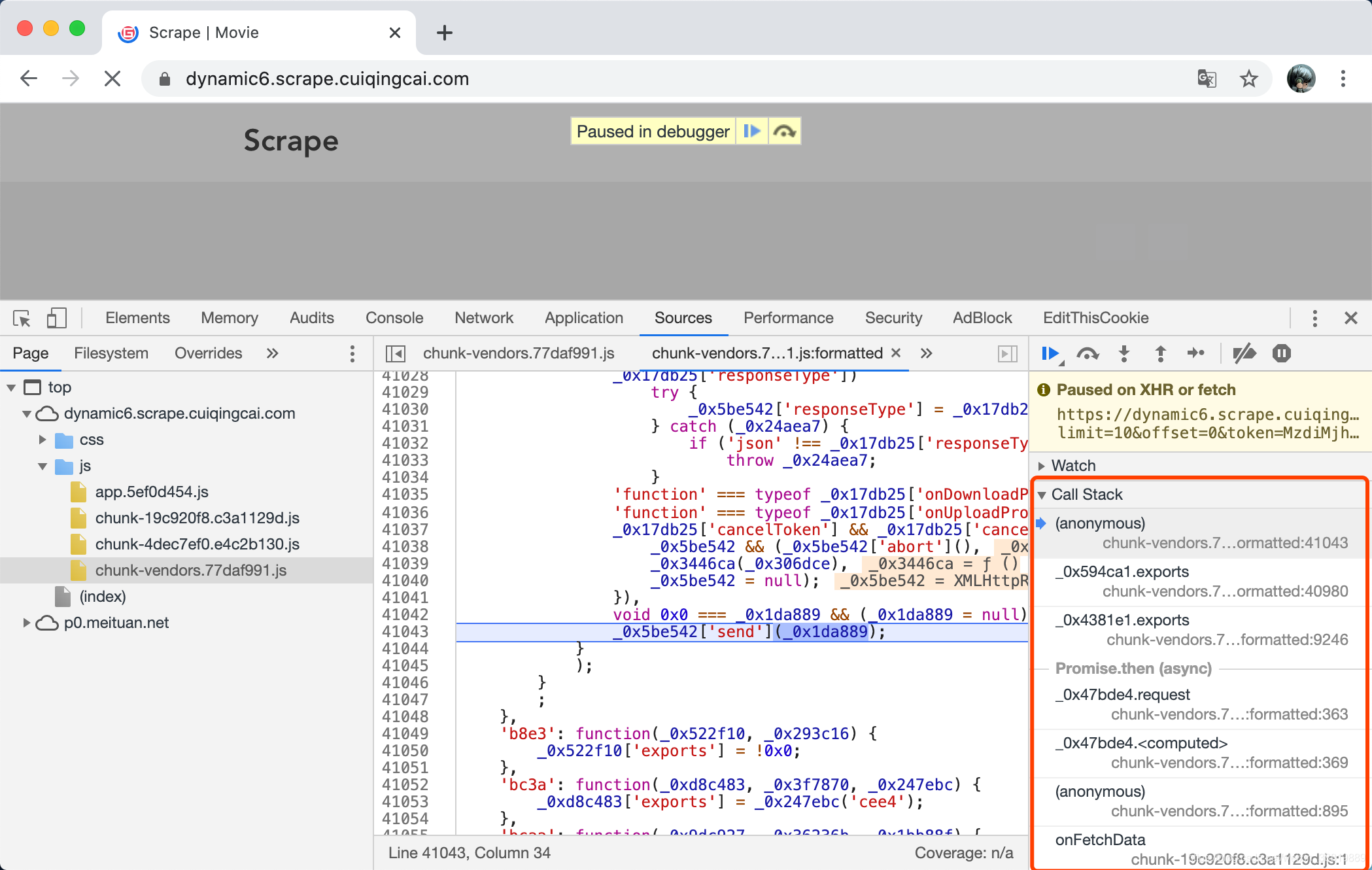
这里当前指向的是一个名字为 anonymouns,也就是匿名的调用,在它的下方就显示了调用这个 anonymouns 的方法,名字叫作 _0x594ca1,然后再下一层就又显示了调用 _0x594a1 这个方法的方法,依次类推。
这里我们可以逐个往下查找,然后通过一些观察看看有没有 token 这样的信息,就能找到对应的位置了,最后我们就可以找到 onFetchData 这个方法里面实现了这个 token 的构造逻辑,这样我们也成功找到 token 的参数构造的位置了,如图所示。
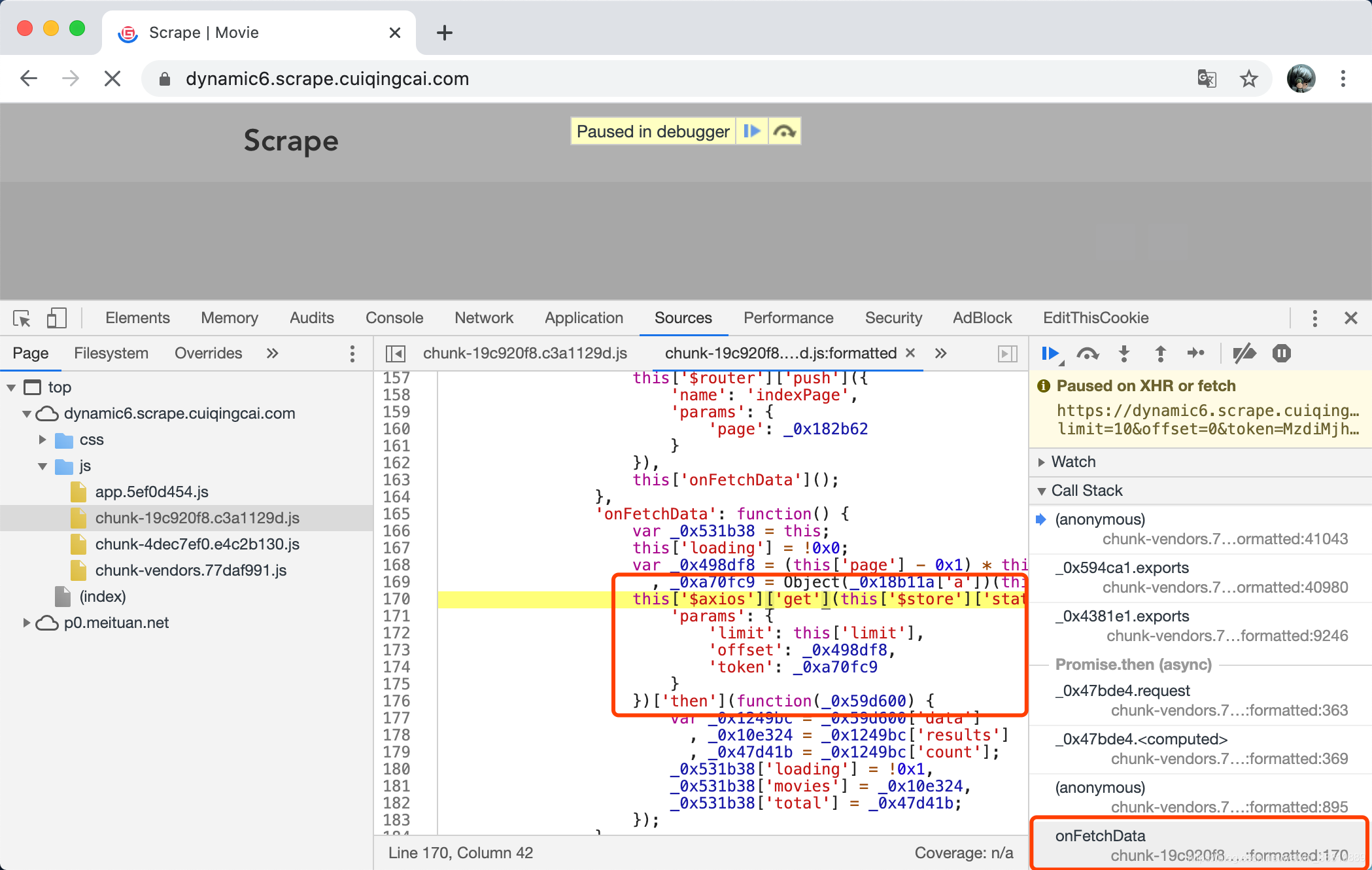
好,到现在为止我们就通过两个方法找到入口点了。
其实还有其他的寻找入口的方式,比如 Hook 关键函数的方式,稍后的课程里我们会讲到,这里就暂时不讲了。
列表页加密逻辑寻找
接下来我们已经找到 token 的位置了,可以观察一下这个 token 对应的变量叫作 _0xa70fc9,所以我们的关键就是要找这个变量是哪里来的了。
怎么找呢?我们打个断点看下这个变量是在哪里生成的就好了,我们在对应的行打一个断点,如果打了刚才的 XHR 断点的话可以先取消掉,如图所示。

这时候我们就设置了一个新的断点了。由于只有一个断点,可以重新刷新下网页,这时候我们会发现网页停在了新的断点上面。
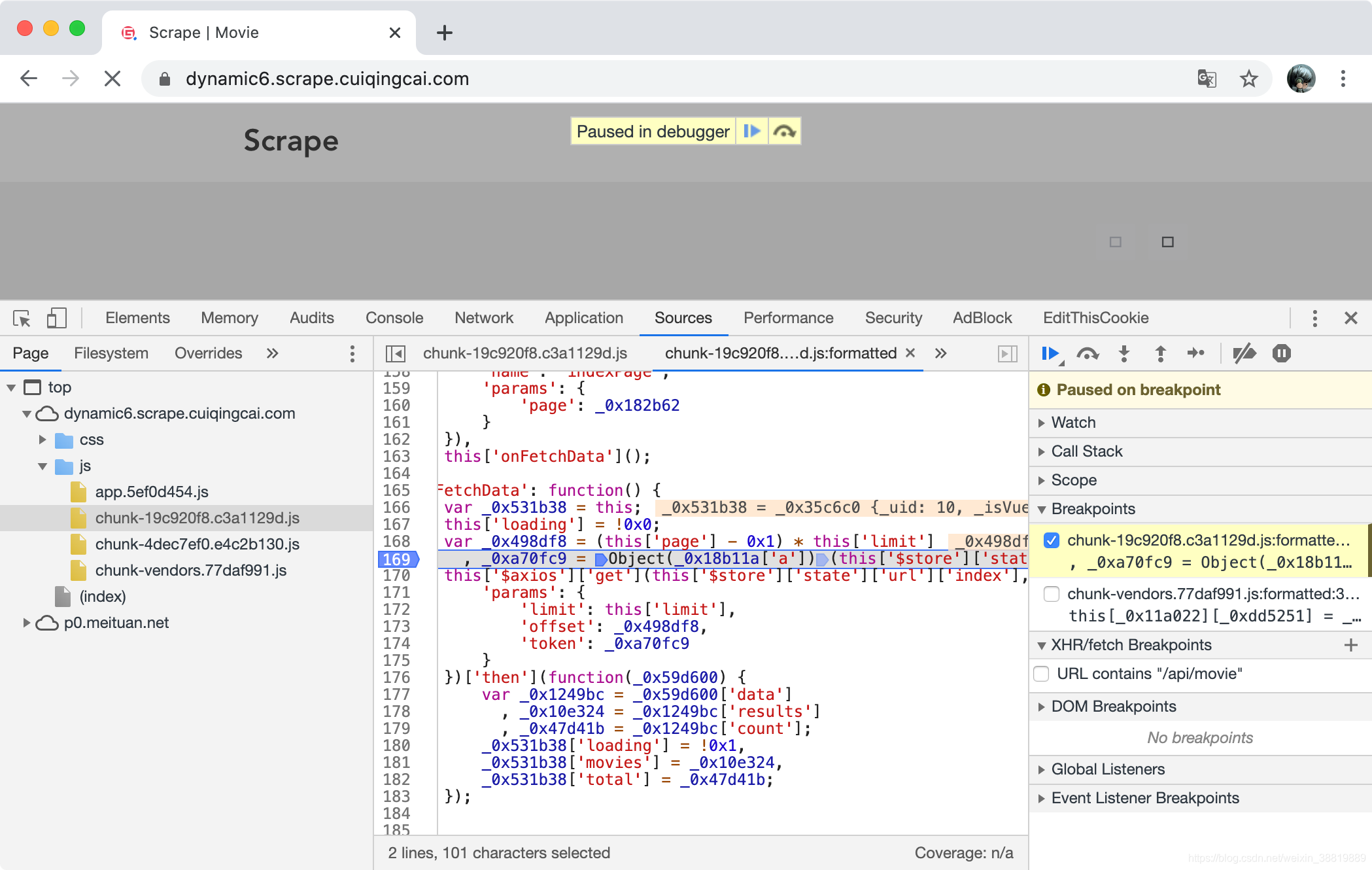
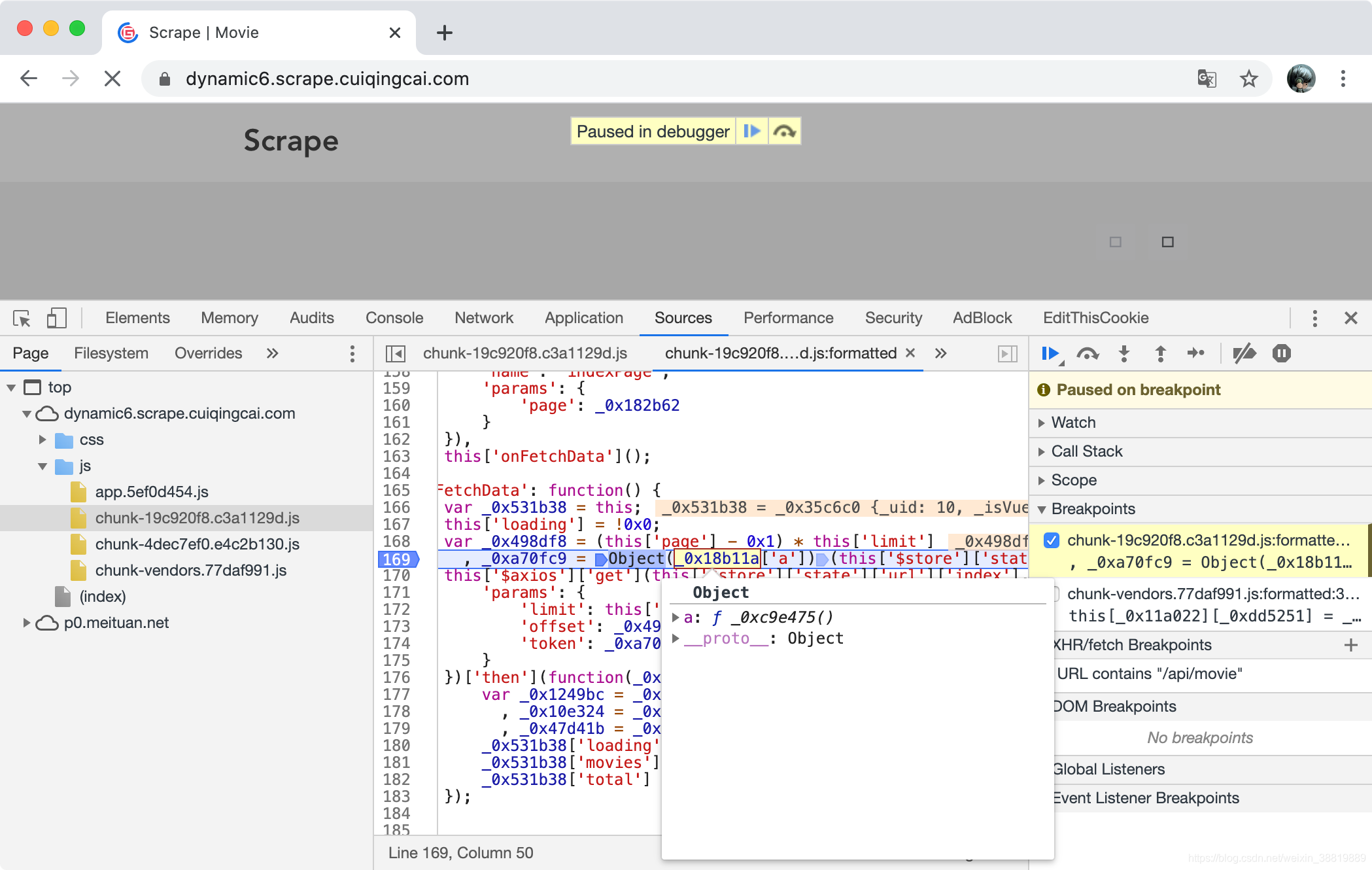
这里我们就可以观察下运行的一些变量了,比如我们把鼠标放在各个变量上面去,可以看到变量的一些值和类型,比如我们看 _0x18b11a 这个变量,会有一个浮窗显示,如图所示。
另外我们还可以通过在右侧的 Watch 面板添加想要查看的变量名称,如这行代码的内容为:
, _0xa70fc9 = Object(_0x18b11a['a'])(this['$store']['state']['url']['index']);
我们比较感兴趣的可能就是 _0x18b11a 还有 this 里面的这个值了,我们可以展开 Watch 面板,然后点击 + 号,把想看的变量添加到 Watch 面板里面,如图所示。
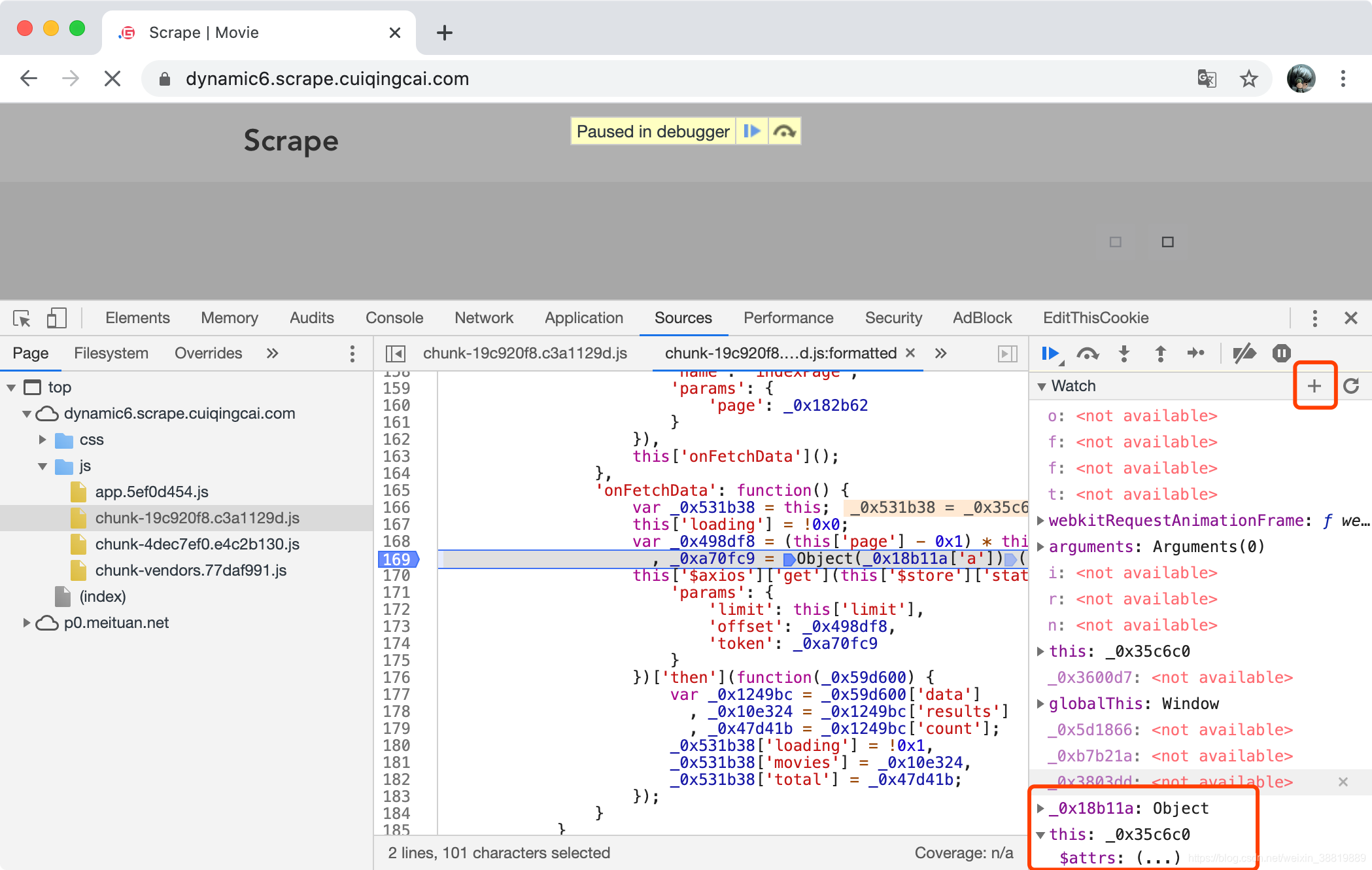
观察下可以发现 _0x18b11a 是一个 Object,它有个 a 属性,其值是一个 function,然后 this[’$store’][‘state’][‘url’][‘index’] 的值其实就是 /api/movie,就是 Ajax 请求 URL 的 Path。_0xa70fc9 就是调用了前者这个 function 然后传入了 /api/movie 得到的。
那么下一步就是去寻找这个 function 在哪里了,我们可以把 Watch 面板的 _0x18b11a 展开,这里会显示一个 FunctionLocation,就是这个 function 的代码位置,如图所示。
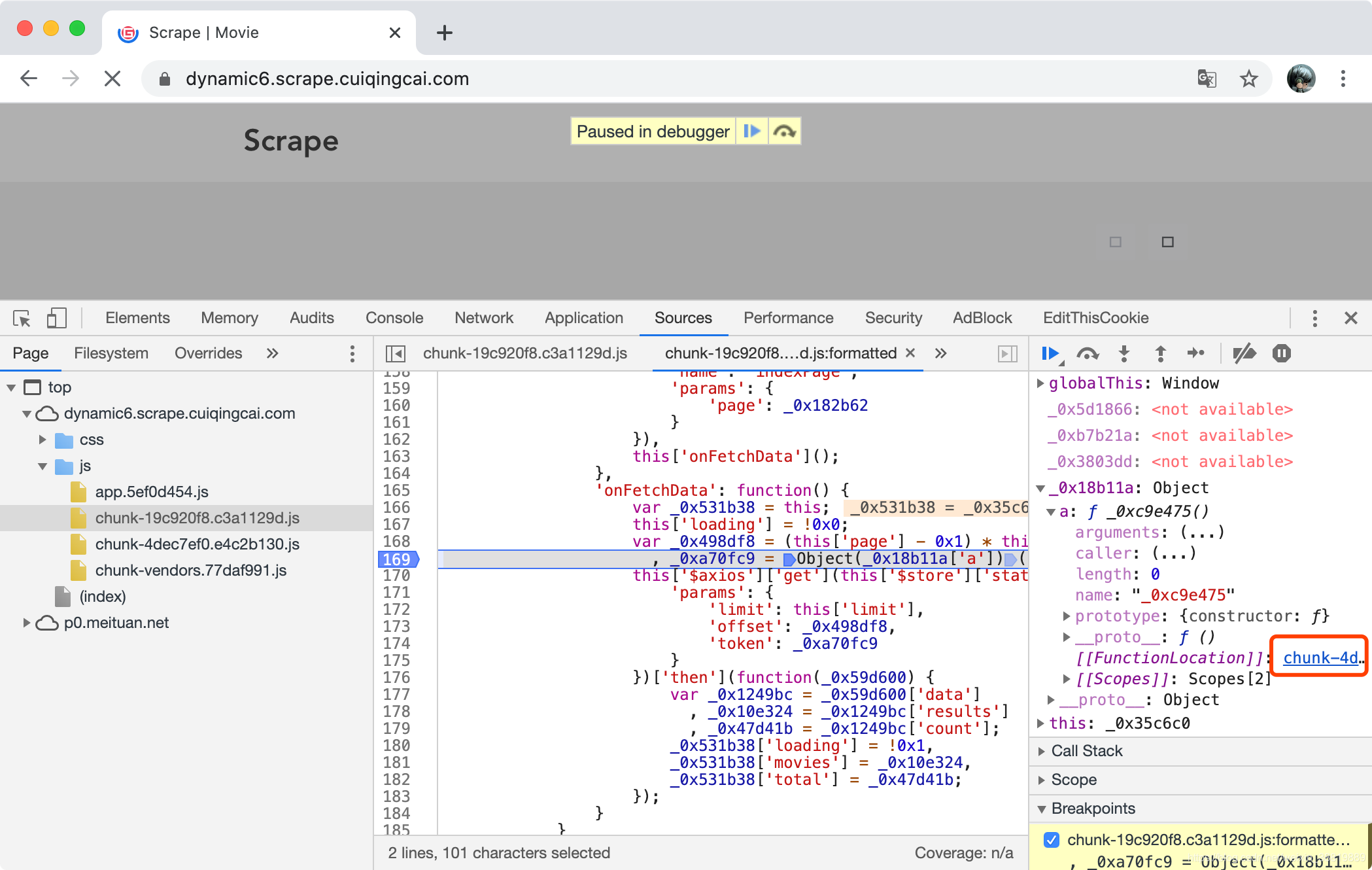
点击进入之后发现其仍然是未格式化的代码,再次点击 {} 格式化代码。
这时候我们就进入了一个新的名字为 _0xc9e475 的方法里面,这个方法里面应该就是 token 的生成逻辑了,我们再打上断点,然后执行面板右上角蓝色箭头状的 Resume 按钮,如图所

这时候发现我们已经单步执行到这个位置了。
接下来我们不断进行单步调试,观察这里面的执行逻辑和每一步调试过程中结果都有什么变化,如图所示。
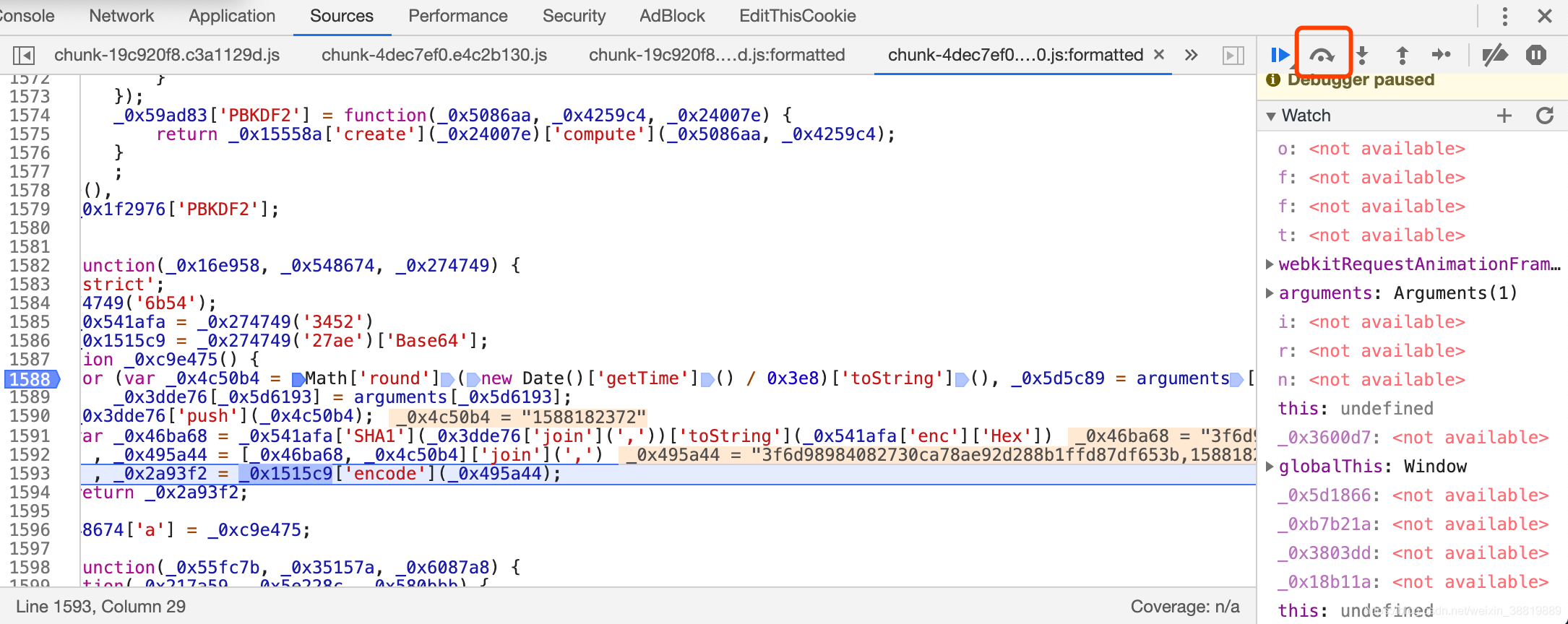
在每步的执行过程中,我们可以发现一些运行值会被打到代码的右侧并带有高亮表示,同时在 watch 面板还能看到每步的变量的具体结果。
最后我们总结出这个 token 的构造逻辑如下:
- 传入的 /api/movie 会构造一个初始化列表,变量命名为 _0x3dde76。
- 获取当前的时间戳,命名为 _0x4c50b4,push 到 _0x3dde76 这个变量里面。
- 将 _0x3dde76 变量用“,”拼接,然后进行 SHA1 编码,命名为 _0x46ba68。
- 将 _0x46ba68 (SHA1 编码的结果)和 _0x4c50b4 (时间戳)用逗号拼接,命名为 _0x495a44。
- 将 _0x495a44 进行 Base64 编码,命名为 _0x2a93f2,得到最后的 token。
以上的一些逻辑经过反复的观察就可以比较轻松地总结出来了,其中有些变量可以实时查看,同时也可以自己输入到控制台上进行反复验证,相信总结出这个结果并不难。
好,那现在加密逻辑我们就分析出来啦,基本的思路就是:
- 先将 /api/movie 放到一个列表里面;
- 列表中加入当前时间戳;
- 将列表内容用逗号拼接;
- 将拼接的结果进行 SHA1 编码;
- 将编码的结果和时间戳再次拼接;
- 将拼接后的结果进行 Base64 编码。
验证下逻辑没问题的话,我们就可以用 Python 来实现出来啦。
Python 实现列表页的爬取
要用 Python 实现这个逻辑,我们需要借助于两个库,一个是 hashlib,它提供了 sha1 方法;另外一个是 base64 库,它提供了 b64encode 方法对结果进行 Base64 编码。
代码实现如下:
import hashlib
import time
import base64
from typing import List, Any
import requests
INDEX\_URL = 'https://dynamic6.scrape.cuiqingcai.com/api/movie?limit={limit}&offset={offset}&token={token}'
LIMIT = 10
OFFSET = 0
def get\_token(args: List[Any]):
timestamp = str(int(time.time()))
args.append(timestamp)
sign = hashlib.sha1(','.join(args).encode('utf-8')).hexdigest()
return base64.b64encode(','.join([sign, timestamp]).encode('utf-8')).decode('utf-8')
args = ['/api/movie']
token = get\_token(args=args)
index\_url = INDEX\_URL.format(limit=LIMIT, offset=OFFSET, token=token)
response = requests.get(index\_url)
print('response', response.json())
这里我们就根据上面的逻辑把加密流程实现出来了,这里我们先模拟爬取了第一页的内容,最后运行一下就可以得到最终的输出结果了。