什么是多线程
线程(Thread)也叫轻量级进程,是操作系统能够进行运算调度的最小单位,它被包涵在进程之中,是进程中的实际运作单位。线程自己不拥有系统资源,只拥有一点儿在运行中必不可少的资源,但它可与同属一个进程的其它线程共享进程所拥有的全部资源。
多线程解决一些什么问题
在日常的开发中,为了要提升性能,我们一般会采用多线程或者多进程的方式,“同时”处理多个任务,或者将一个任务分段处理。关于并发和并行的区别,在这里引用知乎上点赞最高的一个举例简单说明:
你吃饭吃到一半,电话来了,你一直到吃完了以后才去接,这就说明你不支持并发也不支持并行。
你吃饭吃到一半,电话来了,你停了下来接了电话,接完后继续吃饭,这说明你支持并发。
你吃饭吃到一半,电话来了,你一边打电话一边吃饭,这说明你支持并行。
并发的关键是你有处理多个任务的能力,不一定要同时。
并行的关键是你有同时处理多个任务的能力。
所以我认为它们最关键的点就是:是否是『同时』。
——来源知乎问题:并发与并行的区别是什么?
线程的实现
python 中线程主要引用threading模块实现,有两种实现的方式。
- 普通方式
import threading
import time
def task(thread_name):
for i in range(5):
print(f'{thread_name}-运行task{i}')
time.sleep(2)
if __name__ == '__main__':
t1 = threading.Thread(target=task, args=("t1",))
t2 = threading.Thread(target=task, args=("t2",))
t1.start()
t2.start()
- 继承threading.Thread类
本质是重构Thread类中的run方法
import threading
import time
class MyThread(threading.Thread):
def __init__(self, thread_name):
super(MyThread, self).__init__() # 重构run函数必须要写
self.thread_name = thread_name
def run(self):
for i in range(5):
print(f'{self.thread_name}-运行task{i}')
time.sleep(2)
if __name__ == "__main__":
t1 = MyThread("t1")
t2 = MyThread("t2")
t1.start()
t2.start()
主线程等待子线程
我们先看一个例子
import threading
import time
def task(thread_name):
for i in range(5):
print(f'{thread_name}-运行task{i}')
time.sleep(2)
if __name__ == '__main__':
t1 = threading.Thread(target=task, args=("t1",))
t2 = threading.Thread(target=task, args=("t2",))
t1.start()
t2.start()
print("执行结束")
执行结果如下
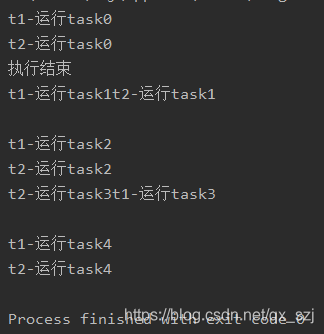
从执行结果可以看出,程序并没有按照我们期望的那样输出,我们本想等任务全部执行完以后打印执行结束,但是实际结果并没有等执行完成就打印了执行结束。
为了让主线程等待子线程执行结束后再执行剩下的代码,我们使用join,阻塞主线程等待子线程全部执行完成后再执行剩余的代码。修改代码如下:
import threading
import time
def task(thread_name):
for i in range(5):
print(f'{thread_name}-运行task{i}')
time.sleep(2)
if __name__ == '__main__':
t1 = threading.Thread(target=task, args=("t1",))
t2 = threading.Thread(target=task, args=("t2",))
t1.start()
t2.start()
t1.join()
t2.join()
print("执行结束")
执行结果如下:
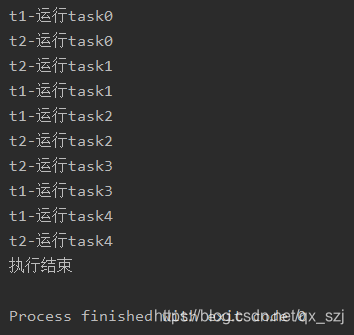
守护进程
如果希望主线程结束的时候子线程就不执行了,那就设置子线程的daemon属性为true
import threading
import time
def task(thread_name):
for i in range(5):
print(f'{thread_name}-运行task{i}')
time.sleep(2)
if __name__ == '__main__':
t1 = threading.Thread(target=task, args=("t1",))
t2 = threading.Thread(target=task, args=("t2",))
t1.setDaemon(True) # 一定要在start之前设置好,不然会报Runtime的错
t2.setDaemon(True)
t1.start()
t2.start()
print("执行结束")
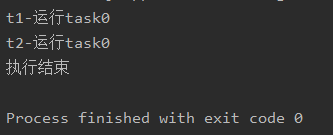
从结果看到,主线程结束的时候,子线程不会再继续执行。守护线程就是指将子线程设置成主线程的守护线程,子线程随主线程的结束而结束。
互斥锁
文章的开头我们介绍到,同一进程中的所有子线程是共享进程所拥有的全部资源。由于线程的调度是随机的,在除了CPython之外的其他解释器中,如JPython,IronPython,有可能会存在多个线程同时修改同一数据的情况,这时数据就有可能出现错乱,我们称为不安全的线程。因此引入了线程锁得概念。(CPython为啥不会出现,后面会介绍)由于楼主是CPython的解释器,这里就直接给出加上了互斥锁的代码。
from threading import Thread, Lock
import time
def task(i):
global num
lock.acquire()
time.sleep(1)
num += 1
print(f't{i} set num to {str(num)}')
lock.release()
if __name__ == '__main__':
num = 0
lock = Lock()
for i in range(5):
t1 = Thread(target=task, args=(i,))
t1.start()
信号量
互斥锁在只允许某一时刻一个线程更改数据,而信号量是允许在某个时刻一定数量的线程更改数据 。举个例子:数据好比一个房间,门口有挂了三把钥匙,那么这个房间在某个时刻,就能进入三个人,但是互斥锁,门口只有一把钥匙,只能一个人进去,后面的人必须等这个人出来了以后,再拿钥匙开门进入。从某种角度上说,互斥锁是信号量为1的锁。
import threading
import time
def task(n):
semaphore.acquire() # 加锁
time.sleep(1)
print(f'thread{n} run\n')
semaphore.release() # 释放
if __name__ == '__main__':
semaphore = threading.BoundedSemaphore(3) # 最多允许3个线程同时运行
for i in range(7):
t = threading.Thread(target=task, args=(i,))
t.start()
重入锁
在解释重入锁的概念之前,我们先了解下什么是死锁,以及为什么会出现死锁。
死锁
死锁是指两个或两个以上的进程或线程在执行过程中,因争夺资源而造成的一种互相等待的现象,若无外力作用,它们都将无法推进下去。此时称系统处于死锁状态或系统产生了死锁,这些永远在互相等待的进程称为死锁进程。

from threading import Thread, Lock
import time
class MyThread(Thread):
def run(self):
self.task1()
self.task2()
def task1(self):
lock_A.acquire()
print(f'{self.name} 拿到A锁')
lock_B.acquire()
print(f'{self.name} 拿到B锁')
lock_B.release()
lock_A.release()
def task2(self):
lock_B.acquire()
print(f'{self.name} 拿到B锁')
time.sleep(2)
lock_A.acquire()
print(f'{self.name} 拿到A锁')
lock_A.release()
lock_B.release()
if __name__ == '__main__':
lock_A = Lock()
lock_B = Lock()
for i in range(5):
t = MyThread()
t.start()
执行结果如下
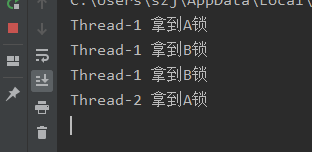
通过结果我们可以看出,程序就一直在卡在这不动了,造成上面的原因我们分析一下:
首先,线程1抢先拿到了A锁,但是没有释放,这时候,剩下的4个线程都没有拿到A锁,那么就只能等待,这时候,线程1并没有始放A锁,继续执行task1的代码,由于其线程都在等待A锁的始放,所以线程1十分顺利的拿到了B锁,继续向下执行,释放B锁,再释放A锁,此时线程1的task1的任务已经执行完成了,开始执行task2的任务,首先去拿到B锁,再等待两秒,再去拿A锁,注意!!!在线程1释放了A锁之后,其他线程会立马争抢A锁,假设线程2拿到了A锁,但是这时候,线程2要开始拿B锁,可是呢!!!这时候B锁在线程1的手上,可是线程1又要线程2手中的A锁,这就造成了死锁的现象。
为了解决上面的现象,我们引入了重入锁。
重入锁也叫递归锁
在Python中为了支持在同一线程中多次请求同一资源,python提供了可重入锁RLock。这个RLock内部维护着一个Lock和一个counter变量,counter记录了acquire的次数,从而使得资源可以被多次require。直到一个线程所有的acquire都被release,其他的线程才能获得资源。
修改上个例子的代码:
from threading import Thread, RLock
import time
class MyThread(Thread):
def run(self):
self.task1()
self.task2()
def task1(self):
lock_A.acquire()
print(f'{self.name} 拿到A锁')
lock_B.acquire()
print(f'{self.name} 拿到B锁')
lock_B.release()
lock_A.release()
def task2(self):
lock_B.acquire()
print(f'{self.name} 拿到B锁')
time.sleep(2)
lock_A.acquire()
print(f'{self.name} 拿到A锁')
lock_A.release()
lock_B.release()
if __name__ == '__main__':
lock_A = lock_B = RLock()
# loch_A = Lock()
# lock_B = Lock()
for i in range(5):
t = MyThread()
t.start()
执行结果

从结果上就可以看到,没有死锁的现象了。
GIL(Global Interpreter Lock)全局解释器锁
文章前面提到,CPython中是不会出现多个线程同时修改共享数据的,原因就是存在一个全局解释器锁,开始介绍之前,我们先看两段代码的实例:
import time
def task():
global n
for i in range(100000000):
n += 1
if __name__ == '__main__':
n = 0
start_time = time.time()
task()
end_time = time.time()
print(f'exe_time: {end_time-start_time}')
print(f'sum_n: {n}')
执行结果如下:
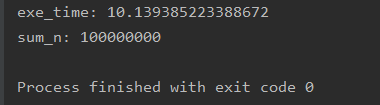
上面是单线程执行的时间,下面我们看一下开启5个线程再去执行,看一看结果。
import threading
import time
def task():
global n
for i in range(20000000):
n += 1
if __name__ == '__main__':
n = 0
start_time = time.time()
thread_list = [threading.Thread(target=task()) for i in range(5)]
for i in thread_list:
i.start()
for j in thread_list:
j.join()
end_time = time.time()
print(f'exe_time: {end_time-start_time}')
print(f'sum_n: {n}')
执行结果如下:
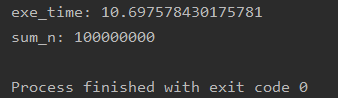
从执行结果中看到,多线程执行的时间竟然比单线程还要慢,这完全违背了多线程的意义了嘛,原因就是在CPython的解释器中,有一个全局解释器锁。
GIL的全称是Global Interpreter Lock(全局解释器锁),来源是python设计之初的考虑,为了数据安全所做的决定。某个线程想要执行,必须先拿到GIL,我们可以把GIL看作是“通行证”,并且在一个python进程中,GIL只有一个。拿不到通行证的线程,就不允许进入CPU执行。
回到上面的两个例子,python的多线程在CPython的解释器中由于存在一个全局解释器,即便是起了多线程,实际上也是不能同时运行的,由于要频繁切换调度线程,所以,花费的时间就比单线程还要长。
看到这里,不禁会生成一个疑问:python的多线程还有意义吗?
其实是有的,在执行IO密集型代码(文件处理、网络爬虫等涉及文件读写的操作),多线程能够有效提升效率(单线程下有IO操作会进行IO等待,造成不必要的时间浪费,而开启多线程能在线程A等待时,自动切换到线程B,可以不浪费CPU的资源,从而能提升程序执行效率)。所以python的多线程对IO密集型代码比较友好。