这一篇呢,是相对于自己的理解,说一说HashMap的底层原理,希望能以简单的方式来说明,便于去理解。。。。
一、HashMap特点
首先说到表,那一定伴随着数据的增删改查和遍历;
那HashMap同样也有着这样的功能;
那到底什么是HashMap,我们先说一下他的两个特点;
1.存取无序
2.键唯一
那,HashMap中有两个参数,一个是key,一个是value;
这个key是唯一的,也就对应了HashMap的查找方式;
二、HashMap的创建
我们从创建一个HashMap对象开始说起,当我们创建一个HashMap对象时;
在jdk1.8以前:在构造方法中创建一个长度是16的Entry[]table的数组来存储数据。
在jdk1.8以后:在第一次调用put方法时创建一个长度16的数组Node[]table来存储数据。
对于这两句话,我们只要理解,在1.8这个分割线下,数组是什么时候创建的;
三、数据的添加
然后刚才提到了put这个方法,显而易见,这个方法就是向HashMap存入数据;
那么存入数据这个过程他是怎么实现的呢?
我们举个例子来说明;
这四个数据的插入,我们就假设出四种插入情况
HashMap<String,Integer> hm=new HashMap<>();
hm.put("张三",18);
hm.put("李四",18);
hm.put("王二麻子",18);
hm.put("张三",20);
在第一行我们创建了一个HashMap对象;
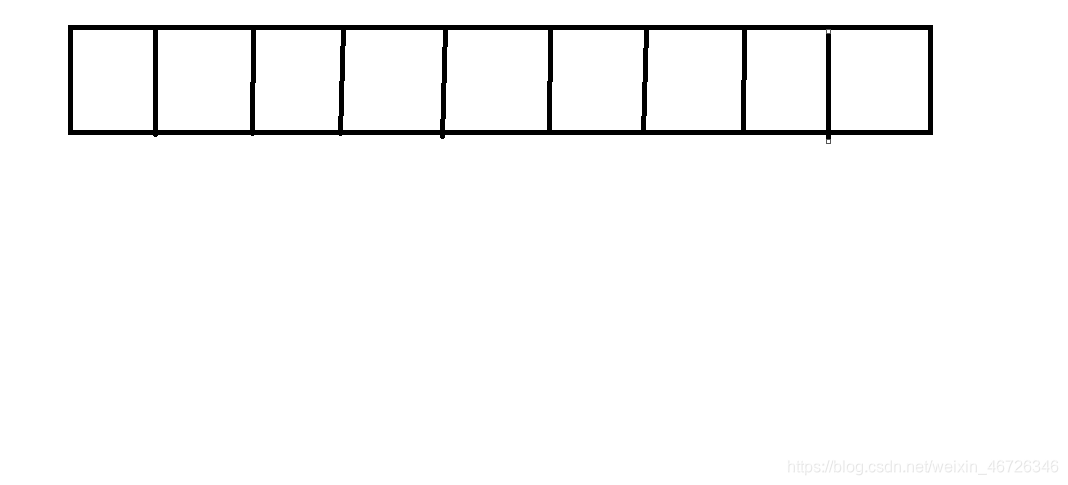
然后在第一次调用put方法的时候,我们会创建一个大小为16的数组;
1.
这里我就不画出16个了,为了方便一点。
我们第一次调用put方法,key存的是“张三”,value存的是18;
那我们到底是怎么存放进去的呢;
首先用这个key调用Hashcode函数来求出它的Hashcode值;
然后在用这个Hashcode值和(数组长度-1)进行按位与运算;
求出索引值,我们假设这个索引值为3,我们看到数组中第三个位置上没有数据;
我们就直接插入;

2.
然后我们看第二个数据,通过刚才的步骤依旧计算出他的索引值;
这个时候,如果我们假设他的索引值依旧为3;那怎么办呢;
数组在3的这个位置已经有值了,这个时候,就要进行下面的步骤;
我们计算“李四”的Hashcode值,发现啊,和我原来3位置上的“张三”的Hashcode值不一样;
哎,那不一样就好办了,我们就直接用拉链法,在张三这个位置,添加一个节点,把第二个数据存进去不就完了吗,从而形成一个链表;
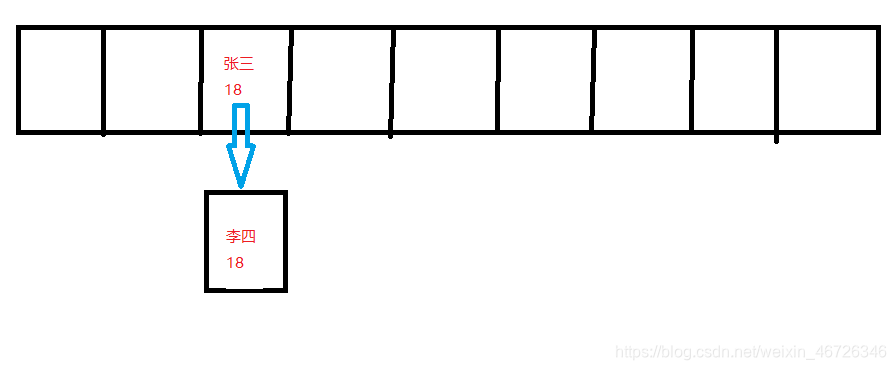
这里面提一嘴,就算是两个不一样的key,Hashcode值有可能一样;
3.
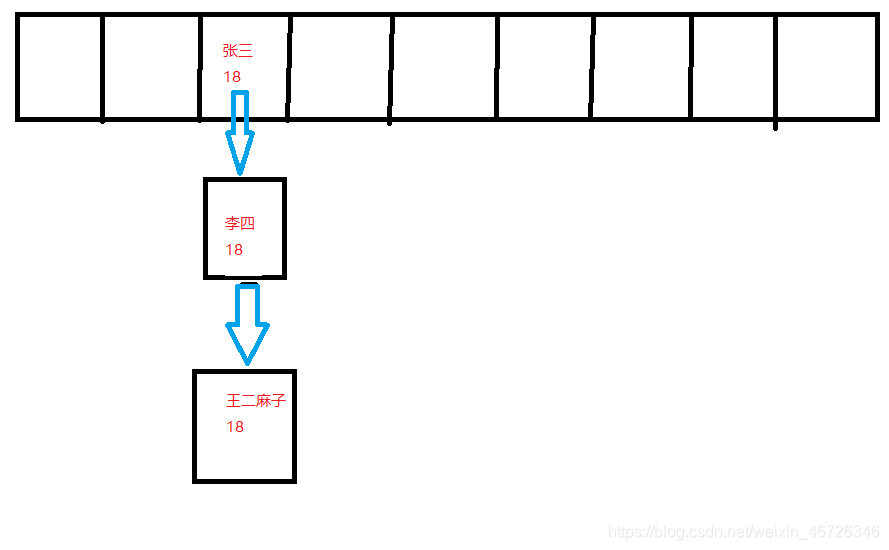
然后我们再看插入的第三个数据,依旧和之前一样,我们计算它的索引值,然后啊;
我发现这TM又是一个3;
这我已经有经验了,分别比较呗,我看看“王二麻子”的Hashcode值和里面的那俩一不一样,这一计算发现,竟然和“张三”的Hashcode值一样,刚才提的那一嘴就在这里用到,该怎么办呢;
不要慌,继续下一步,我Hashcode值和你一样,那我就在调用一个key的equals方法,看看我们的key值是不是一样的,那显而易见了,一个“张三”,一个“王二麻子”;equals方法一定会返回false啊;
好家伙那明确了;
又是一个新来的,插!
4.
然后就剩最后一个数据了,来吧!
又是张三,这一计算,索引值必然是3,索引值一样,我们就算Hashcode值,那必然又和“张三”一样,好,Hashcode值一样,调用equals方法,都是“张三”,那equals也肯定返回true了。
这个时候就说明你这个键值,我表中确确实实已经有了,那我已经有了你又给我一个,好,懂你意思,换就完了被;
这个时候,就把新的value替换原先的value;
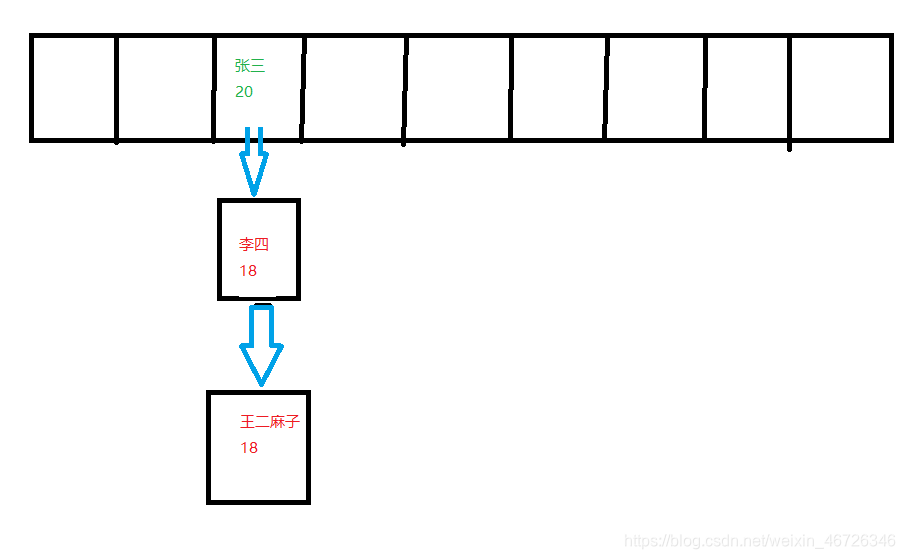
这样这四个数据也就全都add进去了,这四个数据也是对应的四种情况(当然是在索引值相同时的情况)
四、转换红黑树
那,在jdk1.8之前,数据的存储方式就是像这样,索引值相同的以链表方式这么存下去;
在jdk1.8之后,只要满足两个条件,那么链表就会转化成红黑树;
1.节点的长度大于8
2.数组长度大于64
必须同时满足这两个条件,链表才会被转换成红黑树;
这里呢,为什么节点的长度要大于8呢,这就涉及到了数学问题,具体资料就要在别处查阅了;
总之呢,基于时间和空间的权衡,最后选择了8这个数字;
五、计算索引值的方法
刚才在调用put方法的时候,我们只是说了,用key调用的Hashcode值,和数组长度来计算索引值,那到底底层是怎么计算这个索引值的呢?
我们以第一个例子来看,假设“张三”的Hashcode值为3;
数组长度初始值为16,减一为15;
我们把3和15转换成二进制;

后两位都是1,所以落下来的也是1,前两位并不都是1,所以落下来的是0;
那么,计算出的索引值就是3;
六、初始容量
之前我们一直在说数组长度为16,那么这个16是什么意思呢,就是HashMap的初始容量,可以在调用构造方法的时候写进参数里面的初始容量;
那如果像之前的例子的话,我调用的是无参数的构造函数,那么初始容量的默认值就是16;
这里值得注意的就是,初始容量必须是2的n次方;
哎?那我不写行不行,我就不信我写个10你会给我报错?
方然不会报错,在HashMap的底层下有一个方法,如果你传的参数不是2的n次方,那么他就会给你变成2的n次方,怎么变呢,比如你给个10,那真正称为参数的初始容量,会被改成16;
发现了吗,就是你给的数字后面的第一个2的n次方的数字;
具体底层的代码实现可以看看源码,非常牛逼(真是不知道这帮人为啥这么厉害)
七、加载因子
关于加载因子,在下一个小结会说是干什么用的,在这里我们先说一下,如果用HashMap无参数的构造函数,加载因子默认为0.75,当然你也可以改,只要是0-1的数字就行;
但是这里是不建议改的,为什么呢,那么牛逼的人通过计算和实验最终确定下来的值,肯定是最好的,所以就强烈不建议更改;
那加载因子是干什么的,现在开始说
八、扩容
resize这个方法,简单来说,就是把数组长度扩大乘2;
那什么时候会被调用呢,可以看之前我们说过,红黑树的转换条件,一个是节点数大于8,这个没说的了;
而另一个,就是数组长度要大于64,哎?那如果我只满足节点数大于8, 但是我的数组长度还没有到64啊,这个时候怎么办,这个时候就会扩容;
扩容呢还有别的条件,总结来说以下两个条件满足一个就要扩容;
1.当桶的占用数量大于(加载因子乘初始容量)
2.节点数大于8,数组长度小于64
只要满足这两个条件之一,就会调用resize方法;
那这时候又要分了;
jdk1.8之前:重新进行hash分配
数组长度都变了,那肯定要重新计算索引值呀,然后在重新分配
jdk1.8之后:计算新的索引的高位:
如果是0,新索引的位置就是原来索引的位置
如果是1,新索引的位置=原来索引的位置+原来数组的长度
这个特点通过刚才索引值的计算方法也可以算出来,这里我就不再算了;
那还有呢,由于这个高位时0/1完全随机,更好的避免了哈希碰撞;
然后因为扩容 是个很不好的东西,所以我们要尽量避免扩容,那刚才的加载因子,为什么要为0.75,就是因为加载因子的值,取决了是否要扩容,而0.75这个值,就是最好的;
哈,
关于我的HashMap学习的原理部分,我就全部分享完了,OK;
结束!