准备工作:确定电脑上有requests,bs4,wordcloud,jieba这几个第三方包。
在终端里输入命令:pip show 包名
例如 首先第一步是爬取《三国演义》
首先第一步是爬取《三国演义》
分析要爬取的网页<-传送门
点击第一回,第二回,第三回,发现了规律:url的倒数第6个字符随着章回的变化而变化,其他都是不变的,测试后发现不需要伪造请求头。url变化的问题写一个120次for循环就能解决问题。
先看部分代码
以下为每个函数的代码,函数功能看注释。
#把指定的文件放入指定的文件夹,一招解决所有路径问题
def getFilepath(filename):#参数为文件名
'''
无论用的是什么系统,当前工作目录是哪个文件夹
都能准确获取源代码同级目录下的文件完整路径
'''
#将源代码的绝对路径拆分成两部分:源代码所在目录的路径,源代码名
workpath, scourceFile = os.path.split(sys.argv[0])
#返回接合后的路径
return os.path.join(workpath, filename)
# 爬取整个Html文件
def getHtml(url, page):
try:
#按照目前爬取的章回跟新url
url = url.replace(url[-6], page)
r = requests.get(url)
r.raise_for_status()
r.encoding = 'utf-8'
return r.text
except Exception as ex:
print('第{}回爬取出错,出错原因:{}'.format(page, ex))
# 从Html代码中筛选指定内容
def getContent(html):
content = []#存放每一个章回的内容
soup = BeautifulSoup(html, 'html.parser')
div = soup.find('div', class_='card bookmark-list')
#在爬取每一个章回时,为了确保完整性,首先把标题放入列表中
h = div.find('h1')
content.append(h.string)
#寻找'p'标签,爬取每一个段落
for p in div.find_all('p'):
content.append(p.string.strip())#先取出内容,再把每一段开头和结尾的空格去掉
return content
'''
以下部分将和统计词频和制作词云的调用操作一并放入main()函数中
'''
#假的url,在getHtml()中跟新
url = 'http://www.shicimingju.com/book/sanguoyanyi/0.html'
all_content=[]#存放全部内容
for p in range(1,121):
html=getHtml(url,str(p))
page_content=getContent(html)
#将这一章回列表的每一个元素添加到总列表后,不能用append()!
all_content.extend(page_content)
#time.sleep(2) #如果爬取速度过快,可能遇到网站的反爬虫机制,不过这个网站是没有的
print('第{}回爬取完成.'.format(p))
print('网页爬取结束,写入文件...')
target_name = '三国演义.txt' # 目标文件名
#把此文件和源代码放入同一文件夹中,不管目录结构有多么复杂
target_path = getFilepath(target_name)
with open(target_path, 'w', encoding='utf-8') as file:
file.writelines(all_content)
第二步统计词频
这是最烦的一部,虽然jieba库能对字符串进行分词断句,但它终究不认识武将名,所以想要得到武将名,就要进行人为的过滤。把与武将名无关的词语,全部过滤掉,看一下效果就知道:
过滤前: 可以看到,除了29行和33行是武将名之外,其他的都是啥玩意啊。
可以看到,除了29行和33行是武将名之外,其他的都是啥玩意啊。
再看看过滤后: 哇!这正是我想要的!
哇!这正是我想要的!
不过这两张图片之间的过程还是很艰辛的,要人为写一个停用词文件,把与武将名无关的词放进去,将(差不多就行,因为我们只统计前100名),jieba分好的词与停用词进行比较,如果在停用词里面就直接跳过,不写入最后的文件。还有一种办法和这个相反,去网上找到全部的武将名,然后进行比对,写入或不写入。但是网上怎么就会有全部的武将名呢?肯定是第一种方法一个个人为过滤出来的啊。所以我们使用第一种方法实际上就是写一些源代码。
停用词文件部分展示: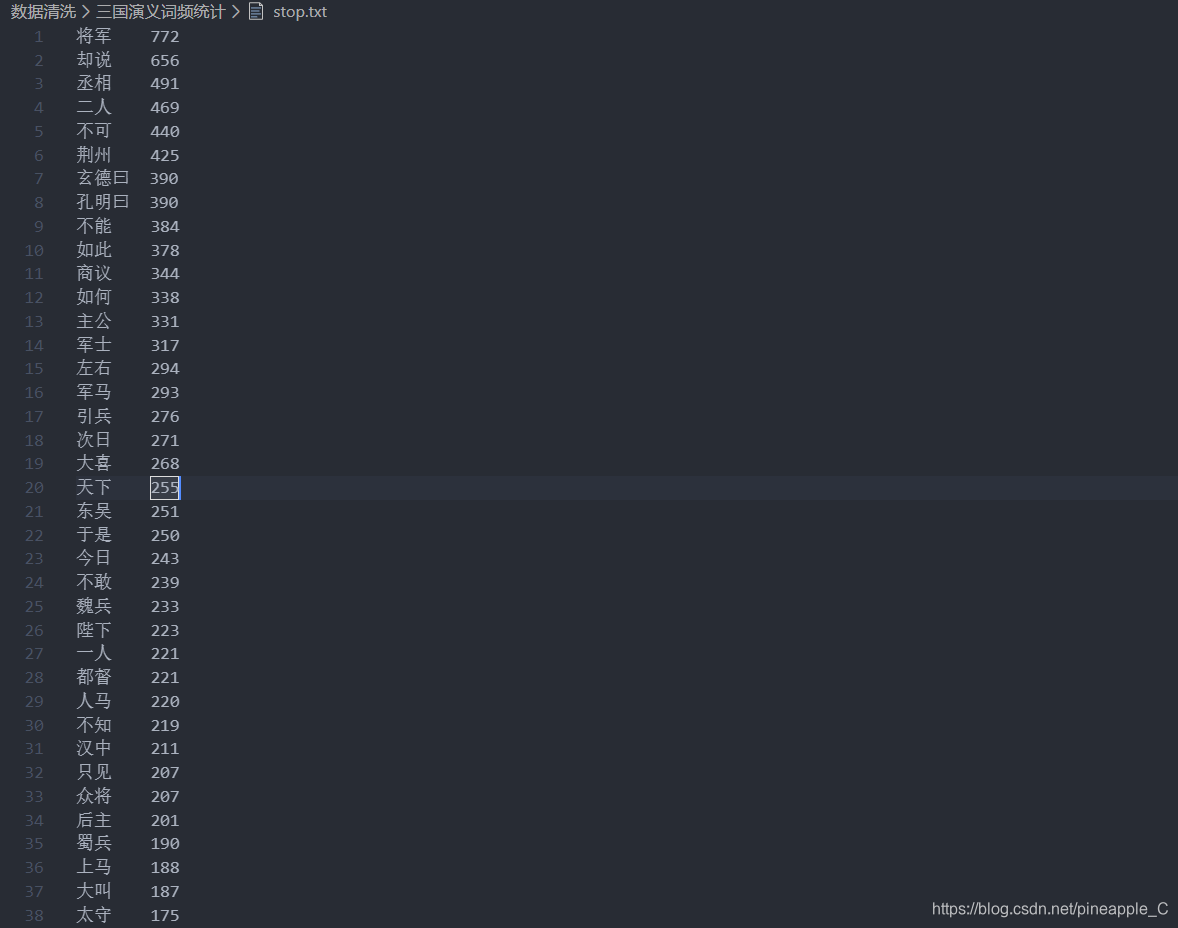
下面看看部分代码,每一个函数:
# 获取目标文件内容
def getTarget_text(targetpath):
f = open(targetpath, 'r', encoding='utf-8')
targettext = f.read()
f.close()
return targettext
# 获取停用词
def stopwordslist(stoppath):
# 利用正则表达式去掉第二列的数字,然后掉多余空格
stopwords = [re.sub('\d', '', line).strip() for line in open(
stoppath, 'r', encoding='utf-8').readlines()]
return stopwords
# 获取词频
def getFreq(targetpath, target_text, lines, stoppath):
words = jieba.lcut(target_text.strip()) # 去掉字符串头尾指定的字符。默认为空格或换行
counts = {}#存放统计的词频数据,武将对应出现次数
freqfile = targetpath.split('.')[0]+'_freq.txt' # 指定词频文件路径
stopwords = stopwordslist(stoppath)
for word in words:
if len(word) == 1:
continue
elif word not in stopwords:
#这些词都是指的同一个人,当然还有很多很多
if word == '皇叔' or word == '刘玄德' or word == '刘皇叔' or word == '刘豫州' or word == '玄德':
word = '刘备'
elif word == '孔明' or word == '诸葛' or word == '武侯' or word == '卧龙':
word = '诸葛亮'
elif word == '孟德' or word == '曹贼' or word == '魏王' or word == '曹公':
word = '曹操'
elif word == '关公' or word == '云长' or word == '关云长':
word = '关羽'
elif word == '公瑾' or word == '周郎':
word = '周瑜'
elif word == '赵子龙':
word = '赵云'
elif word == '吴侯':
word = '孙权'
elif word == '孙夫人':
word = '孙尚香'
elif word == '翼德':
word = '张飞'
counts[word] = counts.get(word, 0)+1 # 找到字典中键所对应的值,没找到则返回0
items = sorted(counts.items(), key=lambda x: x[1], reverse=True)#字典按照值进行排序
f = open(freqfile, 'w', encoding='utf-8')
for i in range(lines):
word, count = items[i]
f.writelines('{}\t{}\n'.format(word, count))
f.close()
return freqfile
def getWcloud(freqpath):
f = open(freqpath, 'r', encoding='utf-8')
text = f.read()
wcloud = wordcloud.WordCloud(font_path=r'C:\Windows\Fonts\STXINWEI.TTF',
background_color='white',
width=1000,
max_words=500,
height=860,
margin=2).generate(text)
wcloud.to_file(freqpath.split('_')[0]+'cloud.png')#指定词云文件路径
f.close()
'''
下面的调用操作将放到main()函数内
'''
stop_name = 'stop.txt' # 停用词文件名
stop_path = getFilepath(stop_name)
target_text = getTarget_text(target_path)
lines = 100 # 选取出现次数前100的武将
freq_path = getFreq(target_path, target_text, lines, stop_path)
getWcloud(freq_path)
完整代码:
from bs4 import BeautifulSoup
import wordcloud
import requests
import jieba
import time
import sys
import re
import os
#把指定的文件放入指定的文件夹,一招解决所有路径问题
def getFilepath(filename):#参数为文件名
'''
无论用的是什么系统,当前工作目录是哪个文件夹
都能准确获取源代码同级目录下的文件完整路径
'''
#将源代码的绝对路径拆分成两部分:源代码所在目录的路径,源代码名
workpath, scourceFile = os.path.split(sys.argv[0])
#返回接合后的路径
return os.path.join(workpath, filename)
# 爬取整个Html文件
def getHtml(url, page):
try:
#按照目前爬取的章回跟新url
url = url.replace(url[-6], page)
r = requests.get(url)
r.raise_for_status()
r.encoding = 'utf-8'
return r.text
except Exception as ex:
print('第{}回爬取出错,出错原因:{}'.format(page, ex))
# 从Html代码中筛选指定内容
def getContent(html):
content = []#存放每一个章回的内容
soup = BeautifulSoup(html, 'html.parser')
div = soup.find('div', class_='card bookmark-list')
#在爬取每一个章回时,为了确保完整性,首先把标题放入列表中
h = div.find('h1')
content.append(h.string)
#寻找'p'标签,爬取每一个段落
for p in div.find_all('p'):
content.append(p.string.strip())#先取出内容,再把每一段开头和结尾的空格去掉
return content
# 获取目标文件内容
def getTarget_text(targetpath):
f = open(targetpath, 'r', encoding='utf-8')
targettext = f.read()
f.close()
return targettext
# 获取停用词
def stopwordslist(stoppath):
# 利用正则表达式去掉第二列的数字,然后掉多余空格
stopwords = [re.sub('\d', '', line).strip() for line in open(
stoppath, 'r', encoding='utf-8').readlines()]
return stopwords
# 获取词频
def getFreq(targetpath, target_text, lines, stoppath):
words = jieba.lcut(target_text.strip()) # 去掉字符串头尾指定的字符。默认为空格或换行
counts = {}#存放统计的词频数据,武将对应出现次数
freqfile = targetpath.split('.')[0]+'_freq.txt' # 指定词频文件路径
stopwords = stopwordslist(stoppath)
for word in words:
if len(word) == 1:
continue
elif word not in stopwords:
#这些词都是指的同一个人,当然还有很多很多
if word == '皇叔' or word == '刘玄德' or word == '刘皇叔' or word == '刘豫州' or word == '玄德':
word = '刘备'
elif word == '孔明' or word == '诸葛' or word == '武侯' or word == '卧龙':
word = '诸葛亮'
elif word == '孟德' or word == '曹贼' or word == '魏王' or word == '曹公':
word = '曹操'
elif word == '关公' or word == '云长' or word == '关云长':
word = '关羽'
elif word == '公瑾' or word == '周郎':
word = '周瑜'
elif word == '赵子龙':
word = '赵云'
elif word == '吴侯':
word = '孙权'
elif word == '孙夫人':
word = '孙尚香'
elif word == '翼德':
word = '张飞'
counts[word] = counts.get(word, 0)+1 # 找到字典中键所对应的值,没找到则返回0
items = sorted(counts.items(), key=lambda x: x[1], reverse=True)#字典按照值进行排序
f = open(freqfile, 'w', encoding='utf-8')
for i in range(lines):
word, count = items[i]
f.writelines('{}\t{}\n'.format(word, count))
f.close()
return freqfile
def getWcloud(freqpath):
f = open(freqpath, 'r', encoding='utf-8')
text = f.read()
wcloud = wordcloud.WordCloud(font_path=r'C:\Windows\Fonts\STXINWEI.TTF',
background_color='white',
width=1000,
max_words=500,
height=860,
margin=2).generate(text)
wcloud.to_file(freqpath.split('_')[0]+'cloud.png')#指定词云文件路径
f.close()
def main():
url = 'http://www.shicimingju.com/book/sanguoyanyi/0.html'
all_content = []
for p in range(1, 121):
html = getHtml(url, str(p))
page_content = getContent(html)
all_content.extend(page_content)
# time.sleep(2)
print('第{}回爬取完成.'.format(p))
print('网页爬取结束,写入文件...')
target_name = '三国演义.txt' # 目标文件名
target_path = getFilepath(target_name)
with open(target_path, 'w', encoding='utf-8') as file:
file.writelines(all_content)
stop_name = 'stop.txt' # 停用词文件名,与源代码处于同一目录下
stop_path = getFilepath(stop_name)
target_text = getTarget_text(target_path)
lines = 100 # 选取出现次数前100的武将
freq_path = getFreq(target_path, target_text, lines, stop_path)
getWcloud(freq_path)
if __name__ == "__main__":
main()
终端输出:
(调试环境:vs code)

词云展示: 咋样,有没有你喜欢的武将呢,我喜欢左下角最大的那个哈哈。
咋样,有没有你喜欢的武将呢,我喜欢左下角最大的那个哈哈。
当然这只是出现次数排名,并不代表武将实力排名,可能是罗贯中“亲刘”的原因,出现了这么多蜀国的。想当年郭嘉造句风靡一时,郭嘉单刀赴会,郭嘉过五关斩六将,郭嘉水淹七军,郭嘉六出祁山,郭嘉草船借箭…我郭奉孝竟然不在此!“孙十万”都那么大的字了,“张八百”竟然也不在?
如果想快速尝试一下,懒的写停用词文件的话,可以直接用我的
链接:<-传送门
提取码:k9g5
直接运行就可以,不会存在路径的问题,运行analysis.py就可以,里面包含了crawl.py的内容。
如有错误,欢迎私信纠正
技术永无止境,谢谢支持!