- 版权声明:该文是博主个人的学习笔记,如有错误,恳请看官在评论区指出,在下不胜感激~如要转载注明出处即可~
人物出场设计对词汇的统计。中文文章需要分词才能进行词频统计,这需要用到jieba库。
《三国演义》文本保存为三国演义》.txt,实现代码如下:
#CalThreekingdomsV1.py
import jieba
txt =open("三国演义.txt", "r", encoding = 'utf - 8').read()
words = jieba.lcut(txt)
counts = {}
for word in words:
if len(word) == 1:#排除单个字符的分词结果
continue
else:
counts[word] = counts.get(word, 0) + 1
items = list(counts.items())
items.sort(key = lambda x:x[1], reverse=True)
for i in range (15):
word, count = items[i]
print("{0:<10}{1:>5}".format(word, count))

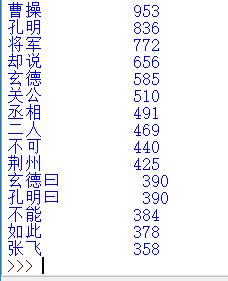
排除一些与人物名字无关的词汇,优化代码如下:
import jieba
excludes = {"将军","却说","荆州","二人","不可","不能","如此"}
txt = open("三国演义.txt", "r", encoding='utf-8').read()
words = jieba.lcut(txt)
counts = {}
for word in words:
if len(word) == 1:
continue
elif word == "诸葛亮" or word == "孔明曰":
rword = "孔明"
elif word == "关公" or word == "云长":
rword = "关羽"
elif word == "玄德" or word == "玄德曰":
rword = "刘备"
elif word == "孟德" or word == "丞相":
rword = "曹操"
else:
rword = word
counts[rword] = counts.get(rword,0) + 1
for word in excludes:
del counts[word]
items = list(counts.items())
items.sort(key=lambda x:x[1], reverse=True)
for i in range(10):
word, count = items[i]
print ("{0:<10}{1:>5}".format(word, count))
