SLAM的Bundle Adjustment上,随着时间的推移,路标特征点和相机的位姿越来越多,BA的计算量随着变量的增加而增加。因此,要限制优化变量的多少,不能只一味的增加待优化的变量到BA里,而应该去掉一些变量。如何丢变量就是很重要的问题!
比如有frame1,frame2,frame3 以及这些frame上的特征点pt1…ptn。新来了一个frame4,为了不再增加BA的变量,出现在脑海里的直接做法是把frame1以及相关特征点pt直接丢弃,只优化frame2,frame3,frame4及相应特征点。然而,直接丢掉变量,就导致损失了信息,frame1可能能更多的约束相邻的frame,直接丢掉的方式就破坏了这些约束。
在SLAM中,一般概率模型都是建模成高斯分布,如相机的位姿都是一个高斯分布,轨迹和特征点形成了一个多元高斯分布p(x1,x2,x3,pt1…),然后图优化或者BA就从一个概率问题变成一个最小二乘问题。因此,从这个多元高斯分布中去掉一个变量的正确做法是把他从这个多元高斯分布中边缘化出去。边缘化就是使用Schur complement(舒尔补)
我们知道SLAM中的图优化和BA都是最小二乘问题,通过高斯牛顿迭代求得,即其中
,
,J是误差对位姿等的雅克比,W是权重。我们关注的marginalize. 就是说只去求解我们希望保留的变量,那些我们要marg的变量就不关心了,从而达到减少计算的目的。假设变量x中可以分为保留部分和marg部分,那么上面的线性方程可以写成如下形式:
这里我们要marg掉,而计算
, 对上面这个方程进行消元得到:
其中就称为
在
中的舒尔补。有了这个上三角形式,我们就可以直接计算出
了:

这样我们就能够迭代的更新部分变量,从而维持计算量不增加。在上面这个过程中,我们要注意,构建出来的Hx=b是利用了marg变量的信息,也就是说我们没有人为的丢弃约束,所以不会丢失信息,但是计算结果的时候,我们只去更新了我们希望保留的那些变量的值。在slam的过程中,BA不断地加入新的待优化的变量,并marg旧的变量,从而使得计算量维持在一定水平。
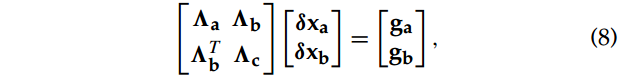
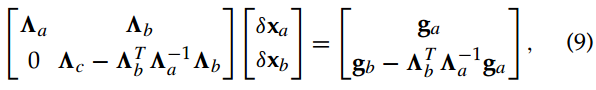
ref:
http://blog.csdn.net/heyijia0327/article/details/52822104
《视觉SLAM十四讲》