来到csdn也快两个月了,前前后后写了20篇博客,但才1800+的访问量,其中恐怕还有300多是我自己点的
有点桑心(┬_┬)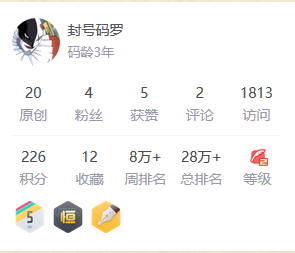
于是打算另辟蹊径,自己刷访问量
代码如下,需要自取
import urllib.request
import requests
import time
import ssl
import random
def openUrl(ip, agent):
headers = {'User-Agent': agent}
proxies = {'http' : ip}
######################################################################################################################
requests.get("https://blog.csdn.net/qq_38175040/article/details/105555979", headers=headers, proxies=proxies, verify=True)
requests.get("https://blog.csdn.net/qq_38175040/article/details/105723124", headers=headers, proxies=proxies, verify=True)
requests.get("https://blog.csdn.net/qq_38175040/article/details/105709758", headers=headers, proxies=proxies, verify=True)
requests.get("https://blog.csdn.net/qq_38175040/article/details/105533341", headers=headers, proxies=proxies, verify=True)
requests.get("https://blog.csdn.net/qq_38175040/article/details/105481195", headers=headers, proxies=proxies, verify=True)
requests.get("https://blog.csdn.net/qq_38175040/article/details/105411407", headers=headers, proxies=proxies, verify=True)
requests.get("https://blog.csdn.net/qq_38175040/article/details/105385858", headers=headers, proxies=proxies, verify=True)
requests.get("https://blog.csdn.net/qq_38175040/article/details/105269253", headers=headers, proxies=proxies, verify=True)
requests.get("https://blog.csdn.net/qq_38175040/article/details/105143224", headers=headers, proxies=proxies, verify=True)
requests.get("https://blog.csdn.net/qq_38175040/article/details/105118224", headers=headers, proxies=proxies, verify=True)
requests.get("https://blog.csdn.net/qq_38175040/article/details/104965393", headers=headers, proxies=proxies, verify=True)
requests.get("https://blog.csdn.net/qq_38175040/article/details/104922374", headers=headers, proxies=proxies, verify=True)
requests.get("https://blog.csdn.net/qq_38175040/article/details/104867747", headers=headers, proxies=proxies, verify=True)
requests.get("https://blog.csdn.net/qq_38175040/article/details/104684355", headers=headers, proxies=proxies, verify=True)
requests.get("https://blog.csdn.net/qq_38175040/article/details/104654254", headers=headers, proxies=proxies, verify=True)
requests.get("https://blog.csdn.net/qq_38175040/article/details/104581291", headers=headers, proxies=proxies, verify=True)
requests.get("https://blog.csdn.net/qq_38175040/article/details/104575123", headers=headers, proxies=proxies, verify=True)
requests.get("https://blog.csdn.net/qq_38175040/article/details/104555324", headers=headers, proxies=proxies, verify=True)
requests.get("https://blog.csdn.net/qq_38175040/article/details/104484876", headers=headers, proxies=proxies, verify=True)
requests.get("https://blog.csdn.net/qq_38175040/article/details/104473154", headers=headers, proxies=proxies, verify=True)
########################################################################################################################
ssl._create_default_https_context = ssl._create_unverified_context
print("Access to success.")
def randomIP():
ip = random.choice(['120.78.78.141', '122.72.18.35', '120.92.119.229'])
return ip
#User-Agent
#User-Agent来源:http://www.useragentstring.com/pages/useragentstring.php
def randomUserAgent():
UserAgent = random.choice(['Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2228.0 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2227.1 Safari/537.36',
'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2227.0 Safari/537.36'])
return UserAgent
if __name__ == '__main__':
for i in range(60):
ip = randomIP()
agent = randomUserAgent()
openUrl(ip, agent)
time.sleep(60)
在python3.x的idle下可以运行:
最后附上效果图: