接上一篇博客讲述了使用TextCNN+Word2Vec实现文本分类理论基础,这一篇博客写我的实际项目代码的思路和实现。
三、代码实现
项目代码全程由python实现,涉及网络爬虫,文本处理,GUI交互,Word2Vec模型训练,TextCNN训练。
这里附上此项目的github链接,里面包含全部代码。文本数据集和模型的尺寸较大,我这里提供一个百度网盘链接供下载,提取码:4kwi。
1. 数据集的制作
首先明确,Word2Vec是一个无监督学习模型,需要一个较大语料库即可。TextCNN是一个有监督学习模型,需要一个带标注的数据集。一般来说,Word2Vec需要的语料库的数据量级要尽量远大于TextCNN的数据集。
这一点跟计算机视觉中有些模型的处理相似:先在一个量级大但标注稀疏甚至无标注的数据集上进行预训练,使得模型具有一定特征提取能力,再在一些量级小但标注更丰富的数据集上训练更高级的任务。例如YOLO v1,先在ImageNet数据集上训练图像分类任务,再在PASCAL VOC数据集上训练目标检测任务。(ImageNet有1千多万张图片,而PASCAL VOC仅有1万多张图片)
为此,我爬取国内的一些高校上的教师简历作为Word2Vec的语料库,爬取福建省高校上的教师简历并手工标注作为TextCNN的数据集。
数据与模型的关系如下图所示:

数据爬取:
目的数据是高校网站上公开的教师简历文本,就是这种数据:
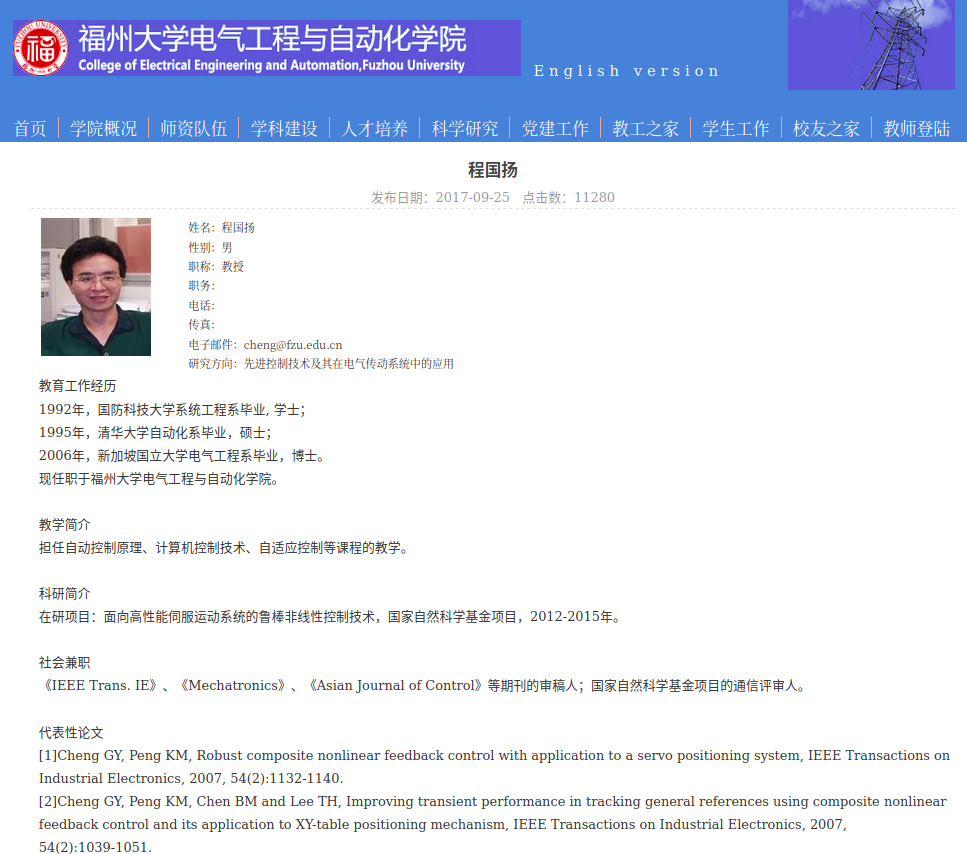
使用Beautiful Soup和urllib这两款软件包编写爬虫代码,爬取高校网站上的教师简历,提取文本数据以txt的格式保存到计算机磁盘中:

爬虫代码在 data/link2text.py 中。
数据预处理:
文本数据的预处理分为三个步骤:文本分词、停用词去除、特殊词替换。
文本分词使用的是jieba分词工具,可以把中文文本的词分割开来,对于文本中混杂的英文文本,jieba默认通过空格来分割开词。
停用词去除指的是将没有具体含义的词进行去除,比如“主要”,“与”,“等”,“的”这类词,这类词的存在对文本的含义没有太太影响,在文本处理中常常对其进行去除。一般是下载一个停用词表,然后程序判断文本中的词在这个停用词表中时,将改词进行去除。除了一些没有具体含义的词,也可以将文本中的标点符号和一些奇怪符号进行去除,比如这些符号: @ ° © ®・● ê ñ ó ¼
特殊词替换是指将文本中的数字等词替换成固定的词。我的操作是将数字替换成“_num_”标识,把数字+英文的组合替换成“_code_”,把百分数替换成“_percent_”。
为什么要把数字替换成固定的词?
这就需要提到上一篇博客中讲到的词典概念,因为在模型训练的时候,都需要先对文本数据统计出一个词典,这时无论是中文词、英文词还是数字,都会被当做一个个词加入到词典中。因为数字的变化是无穷的,如果把不同数字当做不同词,会使词典中很大一部分的空间被数字所占,而这些数字往往不包含具体的语义信息的,无形中使模型训练的难度增加了。所以需要将不同数值的词替换为一个同一的标识,只关心它是个数字,而不关心它的数值内容。
在我的实际数据处理中,直接对分词结果进行统计,得到字典的长度为107004,进行停用词去除后,字典长度减小为106987,进行特殊词替换后,字典长度减小为61362。说明停用词只占原始文本字典的 0.00016%,数字和编码等特殊词占原始文本字典的 42.6% 。从这个统计上看,特殊词的处理要比停用词的处理重要得多。
经过数据预处理后,文本内容的改变:
-> 
数据预处理的代码在 data/textProcess.py 中。
数据标注:
对数据进行标注就是判断简历所属的专业类别,为此我利用python的tkinter模块设计一个GUI程序,用来进行可视化标注,以提高手工标注的效率。
我设计的简历标注GUI程序如下图,根据文本框显示的简历内容,人工判断它所属的专业,在左边的下拉框阵列中选取对应标签,然后点击“标注并跳转至下一条”按钮即可进行标注,标注的结构将保存在xlsx文件中。
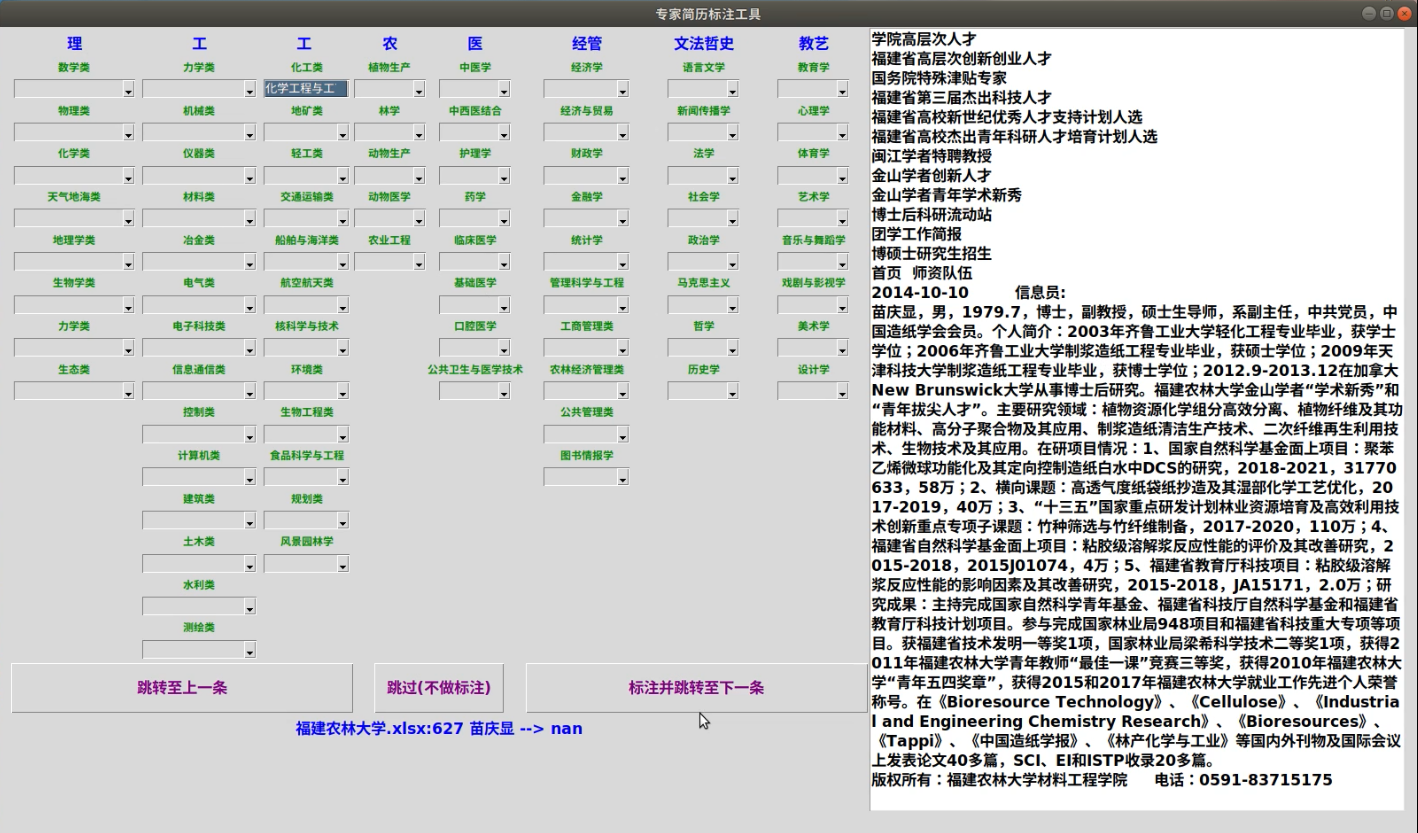
简历标注GUI程序代码在 data/tagging.py 中。
2. Word2Vec模型的训练
我使用python下的gensim模块进行Word2Vec模型的训练。训练数据使用的是国内一些高校的教师简历,一共38430条简历,总大小263.7MB。
gensim的word2vec代码十分简洁,训练代码如下:
from gensim.models import word2vec
word2vec_path='./model/word2Vec.model'
segment_path='../data/train_text/'
# 训练
model = word2vec.Word2Vec(sentences, hs=1, min_count=3, window=5, size=128)
# 保存
model.wv.save_word2vec_format(word2vec_path)训练过程大约十几分钟,产生的词向量模型保存在word2Vec.model.pt中,以供之后TextCNN使用。
完整的代码文件在 word2Vec/train.py 中。
3. TextCNN模型的训练
我参考的是github上的一个基于pytorch实现的TextCNN代码,我添加了Word2Vec词向量模型初始化TextCNN的输入层的功能。
使用标注好的福建省高校教师简历作为TextCNN的数据集,一共有7124条已标注专业类别的简历。
如果不使用Word2Vec模型初始化TextCNN的输入层,运行以下代码:
python main.py如果使用Word2Vec模型初始化TextCNN的输入层,运行:
python main.py -use-word2vec如果显存不够,可以添加参数 -batch-size 1 来将batch size改成1:
python main.py -batch-size 1
python main.py -use-word2vec -batch-size 1训练结束后,模型参数和训练日志保存在 snapshot/ 下。
训练时采样交叉验证的方法,将数据集的9/10作为训练集,1/10作为验证集,使用验证集的准确率来评估模型的性能。
下图为训练过程中训练集和测试集的损失值和准确率,左边的曲线图为未使用Word2Vec的模型,右边的曲线图为使用Word2Vec的模型:


不使用Word2Vec的TextCNN可以达到77%的准确率,使用Word2Vec作为预训练的的TextCNN可以达到80%的准确率,说明Word2Vec对TextCNN有一定的提升效果。
4. 最终效果
最后,我设计了个GUI界面,可以直接输入一个人的简历网址,代码自动爬取该网址的文本作为输入数据,经过模型推算,预测该简历所属的专业类别。
这里我输入何凯明的简历链接,点击“开始预测”按钮,预测何凯明的专业属与“模式识别与智能系统”,与现实相符。
 -->
--> 
该GUI的实现代码在 demp.py 中。