本来是在学习matplotlib画图的,发现自己没有数据去画图光看命令效果好像不是特别大,就想着去猫眼爬点电影来画图。然后就想着刚好练习下以前学过的scrapy,然后悲剧就开始了。
整个spider的代码如下。
# -*- coding: utf-8 -*-
import scrapy
import re
class MaoSpider(scrapy.Spider):
name = 'mao'
allowed_domains = ['maoyan.com']
start_urls = ['https://maoyan.com/board/4']
def parse(self, response):
res=response.xpath("//*[@id='app']/div/div/div/dl/dd")
urls=[]
for info in res:
#print(info)
item = {}
item['标号']=info.xpath('./i//text()').extract_first()
item['标题']=info.xpath("./div/div/div/p/a/text()").extract_first()
item['主演']=re.sub('主演:|\\n','',info.xpath("./div/div/div/p[2]/text()").extract_first()).strip()
item['上映时间']=re.sub('上映时间:','',info.xpath("./div/div/div/p[3]/text()").extract_first())
item['评分']=info.xpath("./div//i[@class='integer']/text()").extract_first()+info.xpath("./div//i[@class='fraction']/text()").extract_first()
yield scrapy.Request( #传入详情页
'https://maoyan.com'+url,
callback=self.parse_detail,
meta={'item': item}
)
next_url=response.xpath("//ul[@class='list-pager']/li/a/@href").extract()[-1]
if next_url!='javascript:void(0);':#判断是否为最后一页
next_url='https://maoyan.com/board/4'+next_url
print(next_url)
yield scrapy.Request( #传入下一页
next_url,
callback=self.parse
)
def parse_detail(self,response):#详情页的解析函数
items={}
item = response.meta['item']
detail=response.xpath('/html/body/div[3]/div/div[2]')
#print(detail)
item['name']=detail.xpath('./div/h3/text()').extract_first()
item['类别']=detail.xpath('./div/ul/li[1]/text()').extract_first()
#print(item['类别'])
info=detail.xpath('./div/ul/li[2]/text()').extract_first().split('/')
#print(info)
for i in range(len(info)):
item['来源']=info[0].replace('\n','').strip()
item['时长']=info[1].strip()
yield item
写完函数下来发现保存不下来,反正就各种错误,找不到库呀之类的,贼烦,明明就是库就是在它非要报个错,改了半天也没保存下来。没办法还是去使用requests吧。
import requests
import xlrd
import xlwt
from xlutils.copy import copy
from bs4 import BeautifulSoup
import re
from lxml import etree
from redis import StrictRedis
redis2 = StrictRedis(host='localhost', port=6379, db=0)##数据库
path='C:/Users/ASUS/Desktop/test_worm/mao.xls'
def one_page(page,path):
url = 'https://maoyan.com/board/4?offset='+str(page*10)
header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:47.0) Gecko/20100101 Firefox/47.0',
}
r=requests.get(url=url,headers=header)
html = etree.HTML(r.text)
#soup=BeautifulSoup(r.text,'lxml')
res=html.xpath("//*[@id='app']/div/div/div/dl/dd")
urls=[]
for info in res:
line=[] #存储写入excel的一行数据
item={}
item['标号']=info.xpath('./i//text()')[0]
item['标题']=info.xpath("./div/div/div/p/a/text()")[0]
item['主演']=re.sub('主演:|\\n','',info.xpath("./div/div/div/p[2]/text()")[0]).strip()
item['上映时间']=re.sub('上映时间:','',info.xpath("./div/div/div/p[3]/text()")[0])
item['评分']=info.xpath("./div//i[@class='integer']/text()")[0]+info.xpath("./div//i[@class='fraction']/text()")[0]
url=info.xpath('./a/@href')[0]
redis2.sadd('url_set','https://maoyan.com' + url)###详情页的url加入redis,‘url_set’集合中
get_detail(item)
for a in item:
line.append(item[a])
write_one_excel_xls_append(path, line)
def get_detail(item):#解析详情页
url = redis2.spop('url_set')#从数据库中拿出一个详情页的url,。。。。。突然发现这个拿出的好像是随机的,也就是它信息没有对应。。。。。。。。换列表吧。。。。。
header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:47.0) Gecko/20100101 Firefox/47.0',
}
r1 = requests.get(url=url, headers=header)
html1 = etree.HTML(r1.text)
detail =html1.xpath('/html/body/div[3]/div/div[2]')[0]
item['类别'] = detail.xpath('./div/ul/li[1]/text()')[0]
info = detail.xpath('./div/ul/li[2]/text()')[0].split('/')
for i in range(len(info)):
item['来源'] = info[0].replace('\n', '').strip()
item['时长'] = info[1].strip()
#写入excel表格
def write_excel_xls(path, sheet_name, value):
index = len(value) # 获取需要写入数据的行数
workbook = xlwt.Workbook() # 新建一个工作簿
sheet = workbook.add_sheet(sheet_name) # 在工作簿中新建一个表格
for i in range(0, index):
for j in range(0, len(value[i])):
sheet.write(i, j, value[i][j]) # 像表格中写入数据(对应的行和列)
workbook.save(path) # 保存工作簿
print("xls创建成功")
#行数据写入
def write_one_excel_xls_append(path, value):
# 获取需要写入数据的行数
workbook = xlrd.open_workbook(path) # 打开工作簿
sheets = workbook.sheet_names() # 获取工作簿中的所有表格
worksheet = workbook.sheet_by_name(sheets[0]) # 获取工作簿中所有表格中的的第一个表格
rows_old = worksheet.nrows # 获取表格中已存在的数据的行数
new_workbook = copy(workbook) # 将xlrd对象拷贝转化为xlwt对象
new_worksheet = new_workbook.get_sheet(0) # 获取转化后工作簿中的第一个表格
for j in range(0, len(value)):
new_worksheet.write(rows_old, j, value[j]) # 追加写入数据,注意是从i+rows_old行开始写入
new_workbook.save(path) # 保存工作簿
print("xls格式表格追加数据成功!")
if __name__ == '__main__':
info = [['标号', '标题', '主演', '上映时间','评分','类别','来源','时长'], ]
write_excel_xls(path, 'work1', info)
for i in range(10):
one_page(i,path)
看看效果,事实证明scrapy学的还不够好,到现在还没有解决如何存储的问题,当初学的时候都没考虑存储,就想着跑出来就好了,还是要继续努力呀。
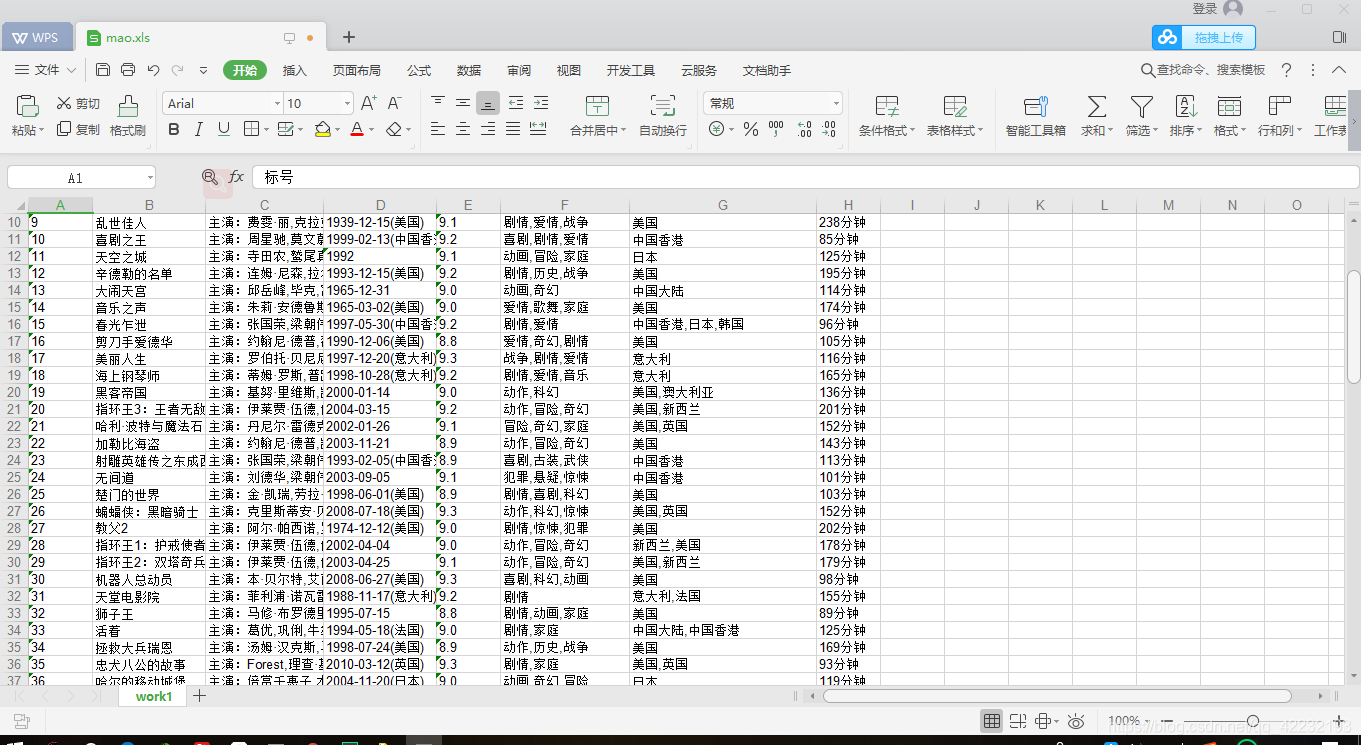
恩,这个就是用requests爬出来的效果了,其实这个不难一般初学都拿猫眼练手,哎个人的scrapy还是有待加强的,只能打印不能保存。不过暂时还没得什么时间,有了这个数据我可以愉快的去画图啦。