关于
在一个安静的夜晚,我缓慢的打开了电脑,望着已经睡着的父母,我轻轻的把门关上,看着斗鱼颜值主播的魅力,我不尽感叹,要是每天都可以不需要那么麻烦的去看那该有多好!
于是我想起了最近刚学的爬虫,嘴角露出了迷之微笑。
开始
我原本以为我这样的菜鸟,如果想爬的话应该只能用xpath来爬取斗鱼图片,可是当我在爬取途中想获取地址,发现了很奇怪的现象


之后我去百度了,看到他们说斗鱼是哪js写的所以我xpath找不到…
所以我就去看了一下jsonpath这个库…
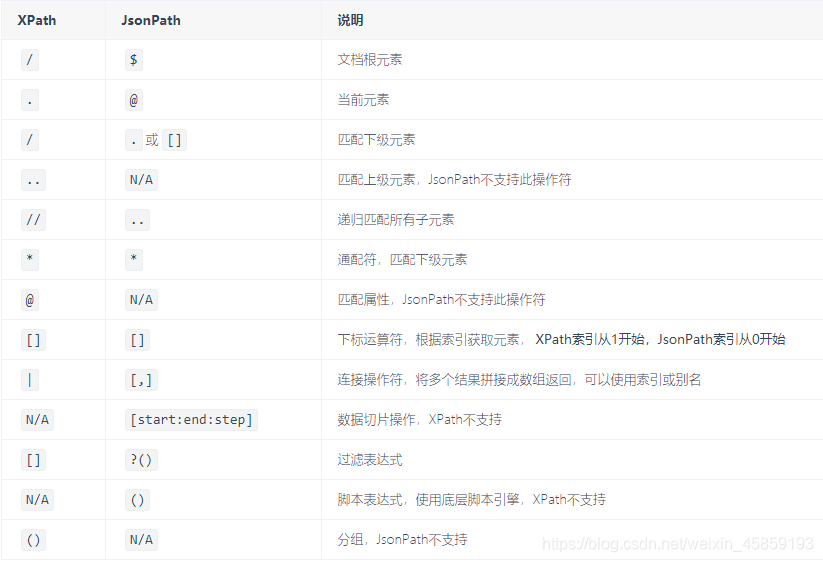
jsonpath语法和xpath语法
json在线解析传送门
链接:https://www.json.cn/
jsonpath流程图
1.先打开斗鱼链接
2.按下f12
3.找到这个
4.复制到json解析,找到图片链接
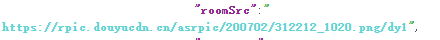
5.找到链接url的规律

代码块
import jsonpath
import requests
import time
name=input('请输入图片关键字:')
#发送请求
url='https://www.douyu.com/japi/search/api/searchShow?kw='+name+'&page=1&pageSize=20'
#模拟浏览器
headers={'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36'}
#解析数据
response=requests.get(url,headers=headers).json()
n=0
#jsonpath需要位置,和目标
img_url_list=jsonpath.jsonpath(response,'$..roomSrc')
for img in img_url_list:
#延迟一下
time.sleep(1)
#获取名字,因为有些分割有dy1所以用if
if (img.split('/')[-1])=='dy1':
file_name=img.split('/')[-2]
else:
file_name=img.split('/')[-1]
#再次发送请求,转换为二进制数
data=requests.get(img,headers=headers).content
#保存数据
with open(file_name,'wb')as f:
f.write(data)
n=n+1
print('第%d张保存成功'%n)
结果

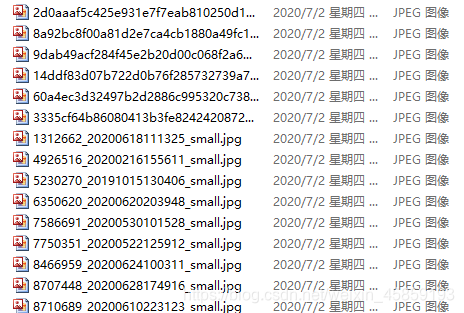
总结
坚持就是胜利,不忘初心,方得始终,每天进步一点点。