Python随机森林调参红酒品质预测
本节的数据来源是2009年UCI库中的Wine Quality Data Set的数据,大家可以在(http://archive.ics.uci.edu/ml/datasets/Wine+Quality)网址进行下载。
1.引入所需模块
import pandas as pd;
import sklearn.model_selection as model_selection
from sklearn.ensemble import RandomForestClassifier
import seaborn as sns
import numpy as np
import matplotlib.pyplot as plt;
2.加载数据
dataSet = pd.read_csv("data\\winequality-red.csv");
#print(dataSet.head());
pd.set_option('display.max_columns',None);# DataFrame 显示所有列
#print("describe",dataSet.describe());
print("shape",np.shape(dataSet));
输出

3.数据分析
dataSet.hist();#直方图
plt.show();
#变量的相关性 展示
sns.heatmap(dataSet.astype(float).corr(),linewidths=0.1,vmax=1.0, square=True,linecolor='white', annot=True)
plt.show();
输出

可以看出quality 数值主要在5,6附近 我们可以以5为分界点

4.划分x,y 训练集和测试集
以y1作为target值
y = dataSet["quality"]; #将 quality 作为target
x = dataSet.drop("quality",axis=1); # 其他作为属性
# 将葡萄酒分成两组 >5为 好酒 为1 小于5为1
y1 = (y>5).astype(int); #改变np.array中所有数据元素的数据类型。
#print(y1);
# 分 训练集合测试集合 7:3
xtrain,xtest,ytrain,ytext = model_selection.train_test_split(x,y1,test_size=0.3,random_state=1);
5.交叉验证 用训练集 进行交叉训练 看看不进行调参的 score为多少
RF_clf = RandomForestClassifier();
cv_score = model_selection.cross_val_score(RF_clf,xtrain,ytrain,scoring='accuracy',cv=10); #scoring='accuracy' 正确率
print("cv_score",cv_score);
print("cv_score_mean",cv_score.mean()); #mean()平均值
输出

此时 什么参数都没有调 平均的score已经达到0.7998
6.调参
我们首先调n_estimators
默认的n_estimators值是100,
我们让n_estimators从50开始 每次加10 最高到300 运行看平均score有什么变化
n_estimators_score = [];
for n in np.arange(50,300,10):
RF_clf = RandomForestClassifier(n_estimators=n);
cv_score = model_selection.cross_val_score(RF_clf, xtrain, ytrain, scoring='accuracy',cv=10); # scoring='accuracy' 正确率
n_estimators_score.append(cv_score.mean());
plt.figure();
plt.plot(np.arange(50,300,10),n_estimators_score);
plt.show();
输出

我们可以看到此时score在0.7825-0.801波动
在70左右取得较高的值
所有我们进一步 让n_estimators从60取到80 看看具体那一个值最好
这次我们直接用GridSearchCV
param_grid = {'n_estimators':range(60,80,1)};
rfc1 = model_selection.GridSearchCV(RandomForestClassifier(),param_grid=param_grid,cv=5);
rfc1.fit(xtrain,ytrain);
print("best_params_",rfc1.best_params_);
print("best_score_",rfc1.best_score_);
输出

现在就以n_estimators=79为值 调一下max_depth
param_grid = {'n_estimators':[79],'max_depth':range(5,30,1)};
rfc1 = model_selection.GridSearchCV(RandomForestClassifier(),param_grid=param_grid,cv=5);
rfc1.fit(xtrain,ytrain);
print("best_params_",rfc1.best_params_);
print("best_score_",rfc1.best_score_);
输出

增长了0.003左右
我们继续在以上两个值的基础上 调一下min_samples_leaf
param_grid = {'n_estimators':[79],'max_depth':[24],'min_samples_leaf':range(1,10,1)};
rfc1 = model_selection.GridSearchCV(RandomForestClassifier(),param_grid=param_grid,cv=5);
rfc1.fit(xtrain,ytrain);
print("best_params_",rfc1.best_params_);
print("best_score_",rfc1.best_score_);
输出

可以看到调优之后 反而没有原来的好,那基本就说明 调优之后复杂度减少反而不好 所以我们就增大特征来看看 让复杂度增大试试看
param_grid = {'n_estimators':[79],'max_depth':[24],'max_features':range(3,10,1)};
rfc1 = model_selection.GridSearchCV(RandomForestClassifier(),param_grid=param_grid,cv=5);
rfc1.fit(xtrain,ytrain);
print("best_params_",rfc1.best_params_);
print("best_score_",rfc1.best_score_);
输出
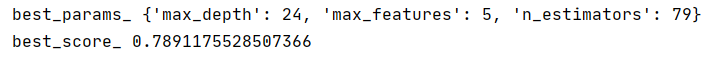
还是比上一个少了
那n_estimators’=79,‘max_depth’=24 基本就可以了
我们用这两个参数 训练预测一下看看结果如何
oob_score=true 因为随机森林是随机取样的 所以总有一些样本没有取到,那么我们不能浪费啊 可以使用那些没有取到的样本对训练出来的模型进行评估
rfc = RandomForestClassifier(n_estimators=79,max_depth=24,oob_score=True,random_state=1);
rfc.fit(xtrain,ytrain);
print("oob_score",rfc.oob_score_);
print("score",rfc.score(xtest,ytext));
array = rfc.feature_importances_;
输出

最终模型预测在百分之80 左右