编程路漫之远兮,集数据库之大体;
劝君专注案前事,亦是杯酒敬苍生;
约束
概念: 对表中的数据进行限定,保证数据的正确性、有效性和完整性。
分类:
1. 主键约束:primary key
2. 非空约束:not null
3. 唯一约束:unique
4. 外键约束:foreign key
非空约束
not null,值不能为null
- 创建表时添加约束(create table)
CREATE TABLE stu(
id INT,
NAME VARCHAR(20) NOT NULL -- name为非空
);
2.创建表完后,添加非空约束(alter table)
ALTER TABLE stu MODIFY NAME VARCHAR(20) NOT NULL;
- 删除name的非空约束 (alter table)
ALTER TABLE stu MODIFY NAME VARCHAR(20);
唯一约束:
unique,值不能重复
1. 创建表时,添加唯一约束
CREATE TABLE stu(
id INT,
phone_number VARCHAR(20) UNIQUE -- 添加了唯一约束
);
注意:mysql中,唯一约束限定的列的值可以有多个null
- 删除唯一约束(drop index)
ALTER TABLE stu DROP INDEX phone_number;
- 在创建表后,添加唯一约束
ALTER TABLE stu MODIFY phone_number VARCHAR(20) UNIQUE;
主键约束:
primary key。
1. 注意:
1. 含义:非空且唯一
2. 一张表只能有一个字段为主键
3. 主键就是表中记录的唯一标识
- 在创建表时,添加主键约束
create table stu(
id int primary key,-- 给id添加主键约束
name varchar(20)
);
- 删除主键
-- 错误 alter table stu modify id int ;
ALTER TABLE stu DROP PRIMARY KEY
;
- 创建完表后,添加主键
ALTER TABLE stu MODIFY id INT PRIMARY KEY;
-
自动增长:
1. 概念:如果某一列是数值类型的,使用 auto_increment 可以来完成值得自动增长 -
在创建表时,添加主键约束,并且完成主键自增长
create table stu(
id int primary key auto_increment,-- 给id添加主键约束
name varchar(20)
);
- 删除自动增长
ALTER TABLE stu MODIFY id INT;
- 添加自动增长
ALTER TABLE stu MODIFY id INT AUTO_INCREMENT;
外键约束:
foreign key,让表于表产生关系,从而保证数据的正确性。(两个表中间的联系)
1. 在创建表时,可以添加外键
语法:
create table 表名(
....
外键列
constraint 外键名称 foreign key (外键列名称) references 主表名称(主表列名称)
);
- 删除外键
ALTER TABLE 表名 DROP FOREIGN KEY 外键名称;
- 创建表之后,添加外键
ALTER TABLE 表名 ADD CONSTRAINT 外键名称 FOREIGN KEY (外键字段名称) REFERENCES 主表名称(主表列名称);
级联操作(谨慎)
- 添加级联操作
语法:添加外键,设置级联更新,设置级联删除
ALTER TABLE 表名 ADD CONSTRAINT 外键名称
FOREIGN KEY (外键字段名称) REFERENCES 主表名称(主表列名称) ON UPDATE
CASCADE / ON DELETE CASCADE ;
- 分类:
1. 级联更新:ON UPDATE CASCADE
2. 级联删除:ON DELETE CASCADE
数据库设计
多表之间的关系
分类:
1. 一对一(了解,因为可以将两表合并):人和身份证
分析:一个人只有一个身份证,一个身份证只能对应一个人
2. 一对多(多对一): 部门和员工
分析:一个部门有多个员工,一个员工只能对应一个部门
3. 多对多:学生和课程
分析:一个学生可以选择很多门课程,一个课程也可以被很多学生选择
实现关系:
关键是外键和主键的对应关系
-
一对一:
实现方式:一对一关系实现,可以在任意一方添加唯一外键指向另一方的主键。
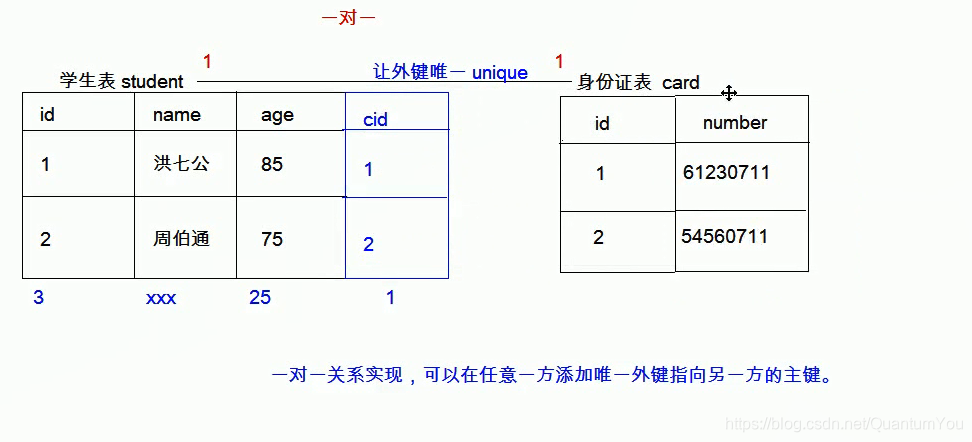
-
一对多(多对一):
实现方式:在多的一方建立外键,指向一的一方的主键。
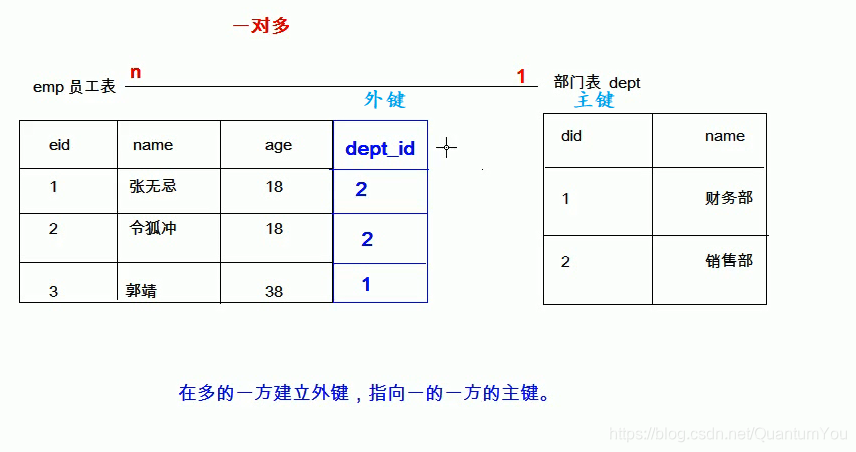
-
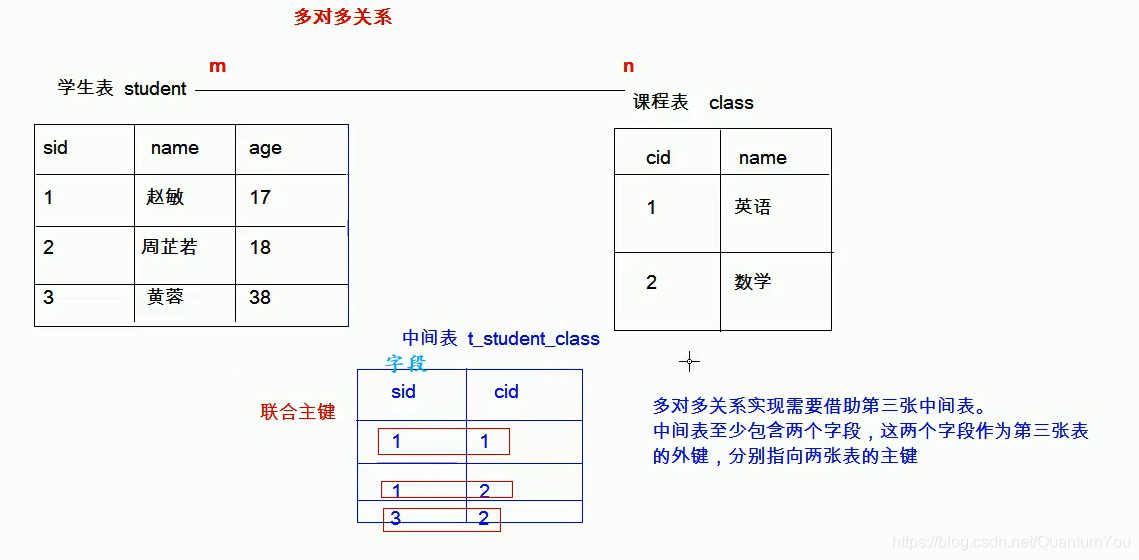
多对多:
实现方式:多对多关系实现需要借助第三张中间表。中间表至少包含两个字段,这两个字段作为第三张表的外键,分别指向两张表的主键
数据库设计的范式
设计数据库时,需要遵循的一些规范。要遵循后边的范式要求,必须先遵循前边的所有范式要求,设计关系数据库时,遵从不同的规范要求,设计出合理的关系型数据库,这些不同的规范要求被称为不同的范式,各种范式呈递次规范,越高的范式数据库冗余越小。目前关系数据库有六种范式:第一范式(1NF)、第二范式(2NF)、第三范式(3NF)、巴斯-科德范式(BCNF)、第四范式(4NF)和第五范式(5NF,又称完美范式)。
分类:
逐渐优化(严格)的过程
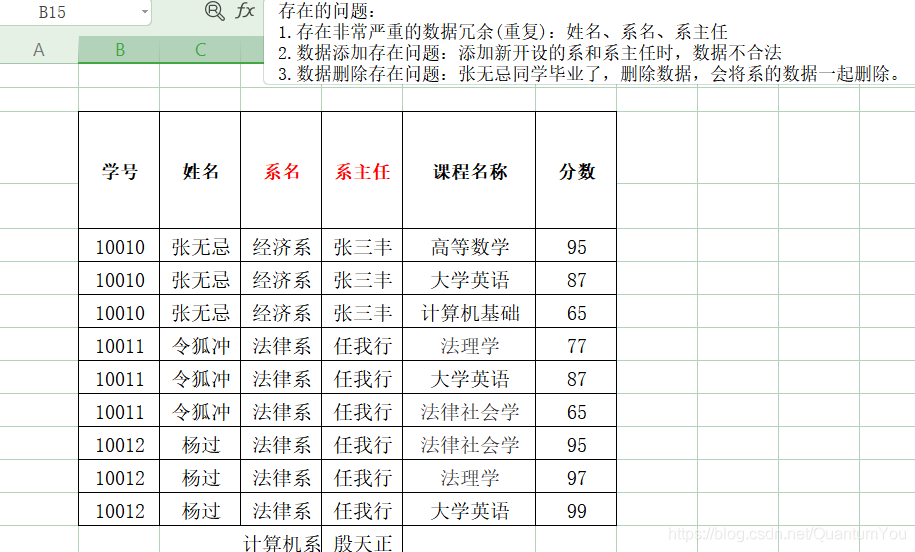
下图普通表(不符合1NF)
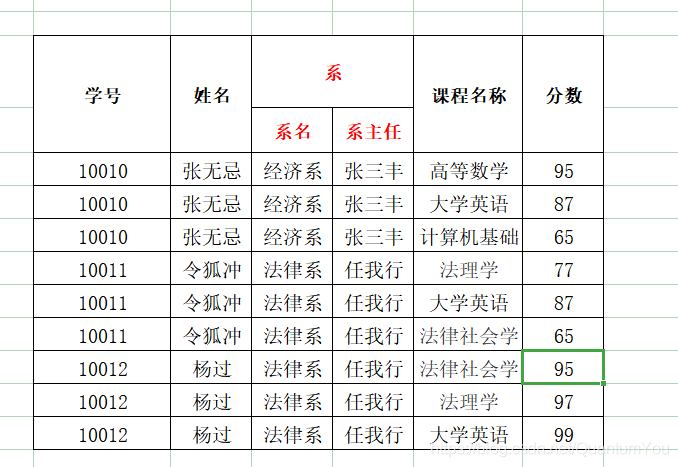
-
第一范式(1NF):每一列都是不可分割的原子数据项
-
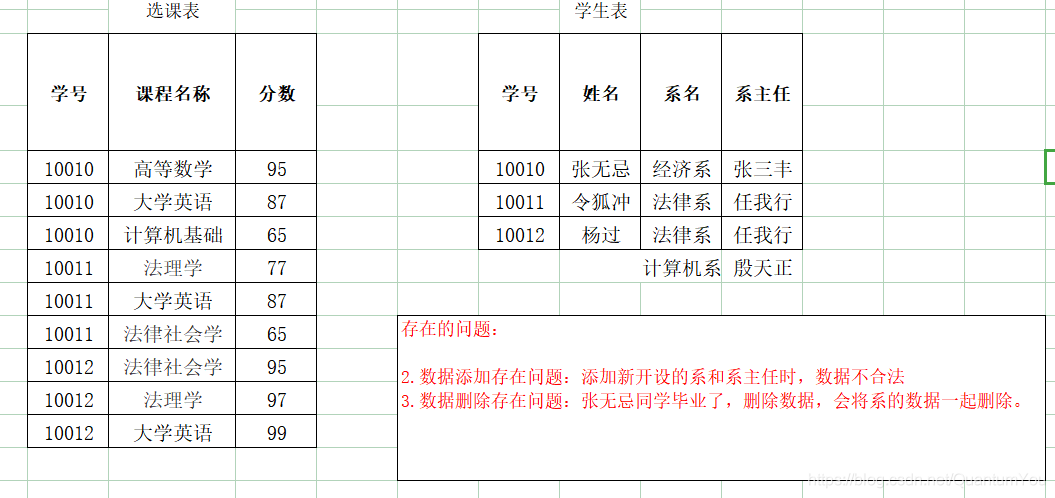
第二范式(2NF):在1NF的基础上,非码属性必须完全依赖于码(在1NF基础上消除非主属性对主码的部分函数依赖)
-
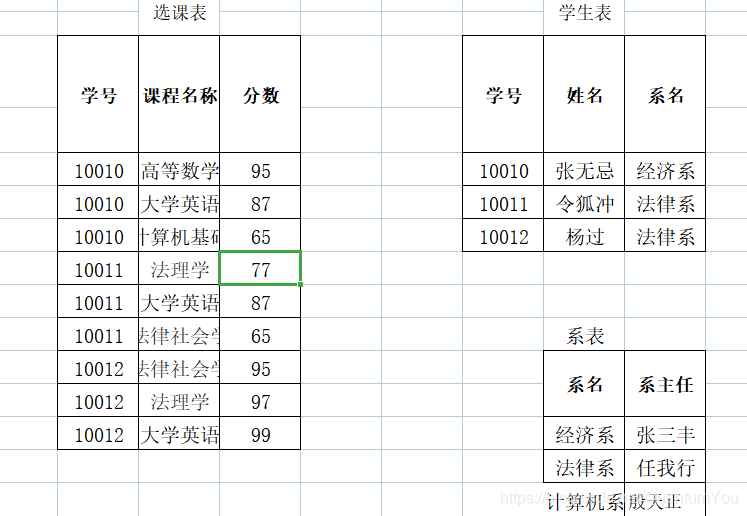
第三范式(3NF):在2NF基础上,任何非主属性不依赖于其它非主属性(在2NF基础上消除传递依赖)
范式中相关概念
函数依赖:A-->B,如果通过A属性(属性组)的值,可以确定唯一B属性的值。则称B依赖于A 例如:学号-->姓名。 (学号,课程名称) --> 分数
完全函数依赖:A-->B, 如果A是一个属性组,则B属性值得确定需要依赖于A属性组中所有的属性值。例如:(学号,课程名称) --> 分数
部分函数依赖:A-->B, 如果A是一个属性组,则B属性值得确定只需要依赖于A属性组中某一些值即可。例如:(学号,课程名称) -- > 姓名
传递函数依赖:A-->B, B -- >C . 如果通过A属性(属性组)的值,可以确定唯一B属性的值,在通过B属性(属性组)的值可以确定唯一C属性的值,则称 C 传递函数依赖于A 例如:学号-->系名,系名-->系主任
码:如果在一张表中,一个属性或属性组,被其他所有属性所完全依赖,则称这个属性(属性组)为该表的码
例如:该表中码为:(学号,课程名称)
* 主属性:码属性组中的所有属性
* 非主属性:除过码属性组的属性
数据库的备份与还原(了解)
通过命令行:
备份: mysqldump -u用户名 -p密码 数据库名称 > 保存的路径
还原:
1. 登录数据库
2. 创建数据库
3. 使用数据库
4. 执行文件。source 文件路径
多表查询
普通查询语法:
select
列名列表
from
表名列表
where....
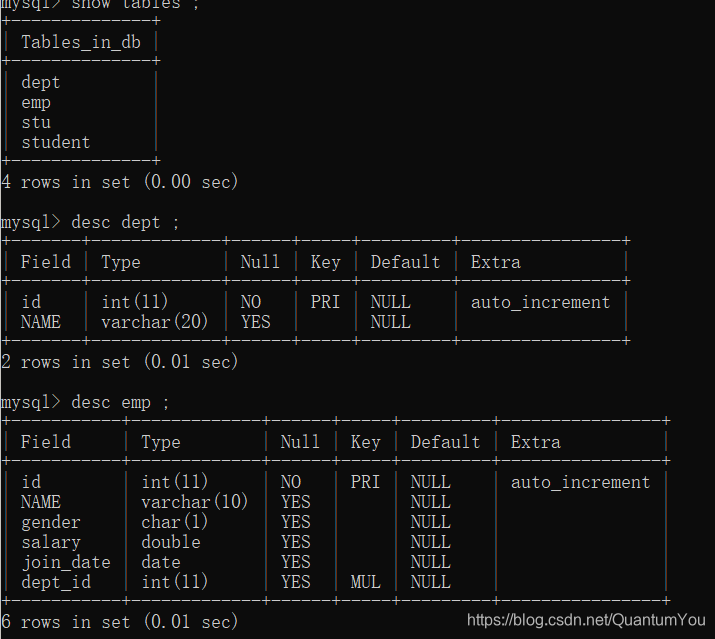
图形化界面展示如下
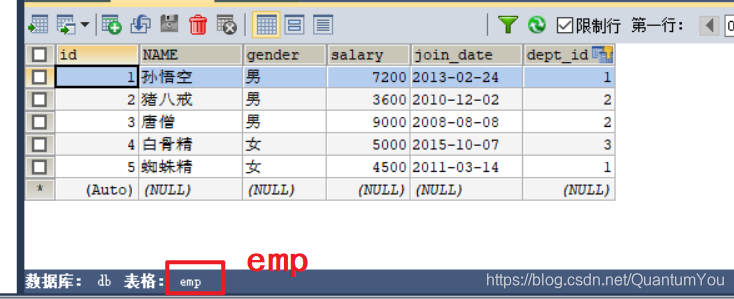
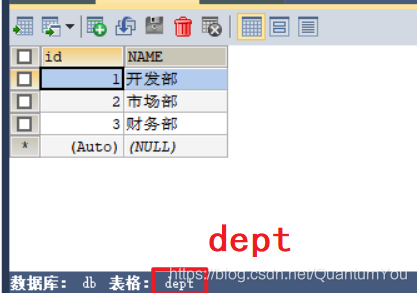
笛卡尔积:有两个集合A,B .取这两个集合的所有组成情况。
https://baike.baidu.com/item/笛卡尔乘积/6323173?fromtitle=笛卡尔积&fromid=1434391&fr=aladdin
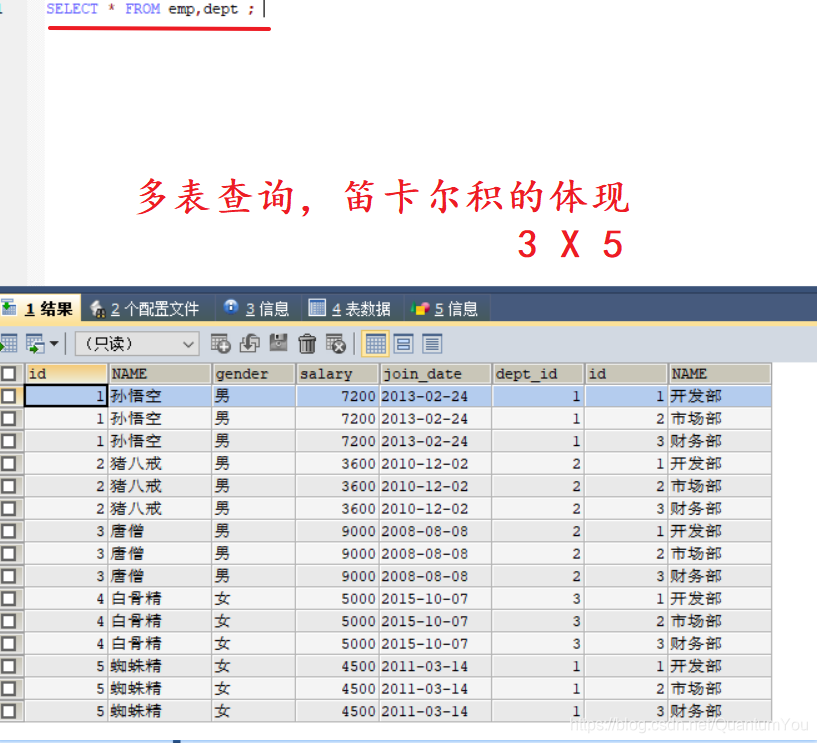
要完成多表查询,需要消除无用的数据
多表查询的分类:
内连接查询:
- 隐式内连接:使用where条件消除无用数据
-- 查询所有员工信息和对应的部门信息
SELECT * FROM emp,dept WHERE emp.`dept_id` = dept.`id`;
-- 查询员工表的名称,性别。部门表的名称
SELECT emp.name,emp.gender,dept.name FROM emp,dept WHERE emp.`dept_id` = dept.`id`;
-- 优化 选择别名
SELECT -- 一般最后选
t1.name, -- 员工表的姓名
t1.gender,-- 员工表的性别
t2.name -- 部门表的名称
FROM
emp t1,
dept t2
WHERE
t1.`dept_id` = t2.`id`;
2.显式内连接:
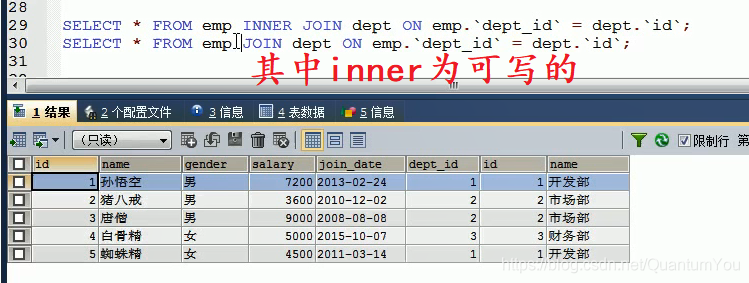
语法: select 字段列表 from 表名1 [inner] join 表名2 on 条件
eg:
SELECT * FROM emp INNER JOIN dept ON emp.`dept_id` = dept.`id`;
SELECT * FROM emp JOIN dept ON emp.`dept_id` = dept.`id`;
- 内连接查询的思维逻辑:
1. 从哪些表中查询数据
2. 条件是什么
3. 查询哪些字段
外链接查询:
左外连接:
语法:
select 字段列表 from 表1 left [outer] join 表2 on 条件;
查询的是左表所有数据以及其交集部分,即使右表数据为null也可。交集即为内链接
eg:
-- 查询所有员工信息,如果员工有部门,则查询部门名称,没有部门,则不显示部门名称
SELECT t1.*,t2.`name` FROM emp t1 LEFT JOIN dept t2 ON t1.`dept_id` = t2.`id`;
右外连接:
语法:
select 字段列表 from 表1 right [outer] join 表2 on 条件;
查询的是右表所有数据以及其交集部分。
eg:
SELECT * FROM dept t2 RIGHT JOIN emp t1 ON t1.`dept_id` = t2.`id`;
注意:左右外连接只需要掌握其一即可,因为是相对概念,前后名互换即可,一般用左外连接查询
子查询:
概念:查询中嵌套查询,称嵌套查询为子查询。
eg:查询下表中工资最高的
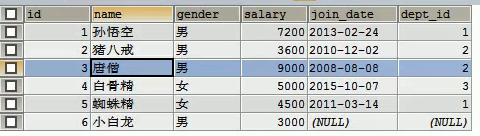
-- 查询工资最高的员工信息
-- 1 查询最高的工资是多少 9000
SELECT MAX(salary) FROM emp;
-- 2 查询员工信息,并且工资等于9000的
SELECT * FROM emp WHERE emp.`salary` = 9000;
-- 一条sql就完成这个操作。子查询
SELECT * FROM emp WHERE emp.`salary` = (SELECT MAX(salary) FROM emp);
子查询不同情况
子查询的结果是单行单列的:
子查询可以作为条件,使用运算符去判断。 运算符: > >= < <= =
-- 查询员工工资小于平均工资的人
SELECT * FROM emp WHERE emp.salary < (SELECT AVG(salary) FROM emp);
子查询的结果是多行单列的:
子查询可以作为条件,使用运算符in来判断
-- 查询'财务部'和'市场部'所有的员工信息
SELECT id FROM dept WHERE NAME = '财务部' OR NAME = '市场部';
SELECT * FROM emp WHERE dept_id = 3 OR dept_id = 2;
-- 优化 子查询
SELECT * FROM emp WHERE dept_id IN (SELECT id FROM dept WHERE NAME = '财务部' OR NAME = '市场部');
子查询的结果是多行多列的:
子查询可以作为一张虚拟表参与查询
-- 查询员工入职日期是2011-11-11日之后的员工信息和部门信息
-- 子查询
SELECT * FROM dept t1 ,(SELECT * FROM emp WHERE emp.`join_date` > '2011-11-11') t2
WHERE t1.id = t2.dept_id;
-- 普通内连接
SELECT * FROM emp t1,dept t2
WHERE t1.`dept_id` = t2.`id` AND t1.`join_date` > '2011-11-11'