今天是端午节,祝大家端午节快乐!这几天有时间,再更新一篇。
考虑下行资源调度算法时,主要有两种码率需要考虑:第一种是有效信道码率(effective channel code rate),第二种是Turbo编码码率。标准协议规定有效信道码率不能超过0.93,但对Turbo编码的码率没有做强制要求。
在介绍如何计算有效信道码率和Turbo编码码率之前,简单了解一下下行共享信道的物理层处理过程是很有必要的。
1.下行共享信道的物理层处理过程
eNB MAC层完成数据的封装之后,以MAC PDU的形式将1个或2个TB传输块发送到下行物理层,下行物理层收到TB传输块即开始依次进行流水线般的处理:
(1)在该TB块的末尾处增加24bits的CRC比特位。
TB块即传输块处理的第一步,就是计算一个24bits的CRC,并将其插入到每个TB块的末尾,如图1所示。循环冗余校验CRC允许接收侧对TB块进行错误检测。如果CRC检测出错,可以通过下行HARQ进行重传,通过合并增益来提升下一次解码的成功率。
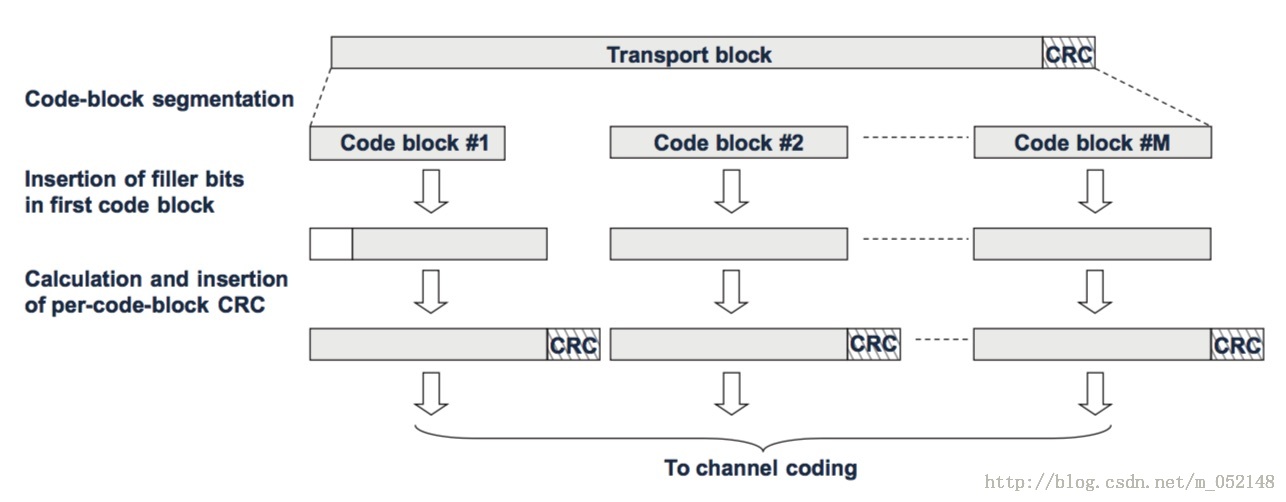
(图1)
(2)把(1)的结果分割成M个码块Code Block,然后在每个码块的末尾增加24bitsCRC比特位。
这个步骤是为后续的Turbo信道编码服务的。LTE Turbo编码器中包含的交织器只能使用有限大小的编码块(CodeBlock),支持的最大码块大小为6144bits。如果TB块加上CRC的比特大小超过了6144bits,就要在Turbo编码之前进行码块分割。
如上面的图1所示,一个完整的TB块和CRC被分割成了M个CB块。M的大小取决于TB块的大小TBsize值:
如果 (TBsize + 24bitsCRC) <= 6144 bits,那么M=1,表示只有1个CB块,不需要对TB块进行分割,CB块的末尾也不需要额外增加一个24bits的CRC信息,直接使用原有TB块的CRC信息即可。
如果 (TBsize + 24bitsCRC) > 6144 bits,那么CB块的个数M = ceil [ (TBsize + 24bitsCRC) / (6144 - 24) ],此时每个CB块的末尾需要额外增加一个24bits的CRC信息,这个CRC的内容与TB块末尾的CRC内容并不相同,仅用于CB块的误码检测。
比如TBsize=75376bits,那么M = ceil [ ( 75376 + 24 ) / ( 6144 - 24 ) ] = 13,即经过这个步骤,下行物理层得到了13个CB块。由于TBSize的值是由RB和MCS确定的,因此UE在解码出下行DCI中的RB和MCS信息之后,就可以计算得到码块数M。
图1中第一个CB块的开头有一小段空白的区域,这个区域叫做填充比特。由于目前LTE协议中的TBS大小是经过选择的,所以并不需要使用填充比特。
只有当所有的分段码块都被接收端正确的解码时,才认为该TB块被正确的解码;只要有任意一个CB块被错误解码,都需要请求HARQ重传。
(3)对(2)的结果进行信道编码(Turbo编码)。
LTE下行共享信道中的每个CB块,都会进行独立的Turbo编码过程,且输出3路比特流码块(即意味着总的编码速率是1/3)。这3路码流分别被称作系统比特、第一校验比特和第二校验比特。 r 个CB块比特码流经过信道编码之后,输出(3 * r)路比特流码块,如图2所示。
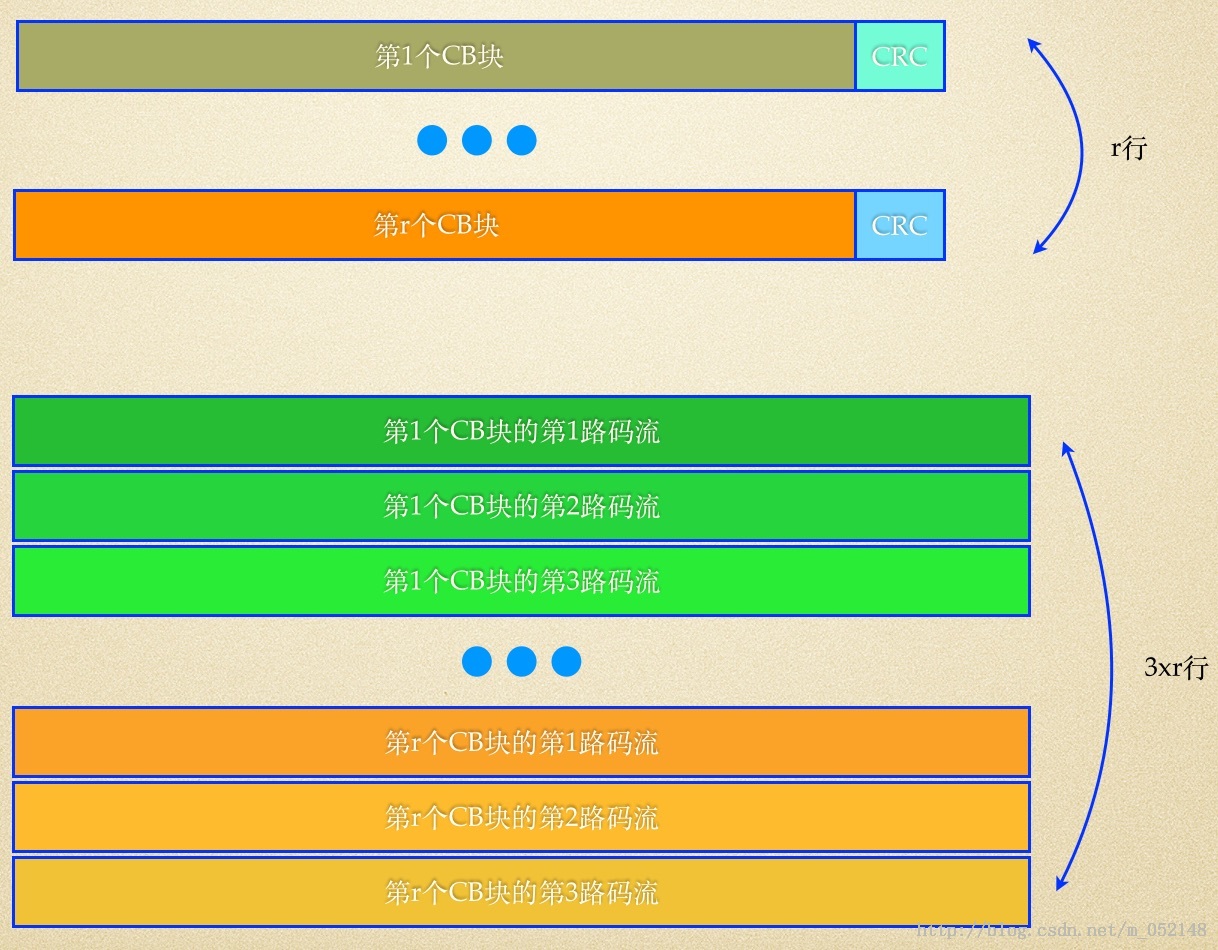
(图2)
每一个码块的编码处理过程是相同的,如果将第 r 个码块的比特数记为Kr(根据前文描述,Kr <= 6144bits),该码块的比特流则可以记为 Cr0,Cr1,...,Cr(Kr-1)。其中,符号Cr0表示第 r 个码块的第0个bit位,其余含义类推。经过Turbo编码后,输出的3路比特流 Ri(i=0,1,2)可以统一记为:d_r0(i),d_r1(i),...,d_r(Dr-1)(i)。其中,符号d_r0(i)表示第 r 个码块对应的第 i 路码流的第0个bit位。Dr表示第 i 路码块的比特位数,值是固定的,Dr = Kr + 4。是不是看到这些符号头就晕了呢?看着看着就不晕了。
对一个具体的CB码块(占K比特)进行信道编码的过程,可以用下面的图3来示意。此时K个比特的比特流 c0,c1,...,c(K-1) 表示输入参数,D个比特的比特流 d0(i),d1(i),...,d(D-1)(i) 表示其中第 i 路码流的输出,D = K + 4。关于Turbo编码器更具体的内容,跟本文的主题无关,不再详细展开。
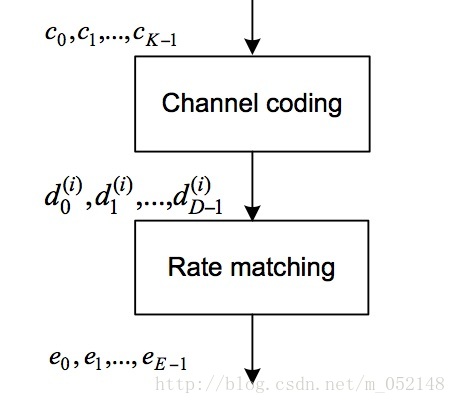
(图3)
(4)对(3)的结果进行速率匹配和HARQ操作。
经过Turbo编码后,每个CB块被转换成的3路比特码流,即系统比特、第一校验比特、第二校验比特,将首先进行独立的子块交织(Sub-block interleaver)。然后,交织的比特将被插入到一个环形缓冲器中(virtual circular buffer),系统比特最先插入,然后是第一校验比特和第二校验比特交替插入,也就是图4中的比特收集(Bit collection)过程。
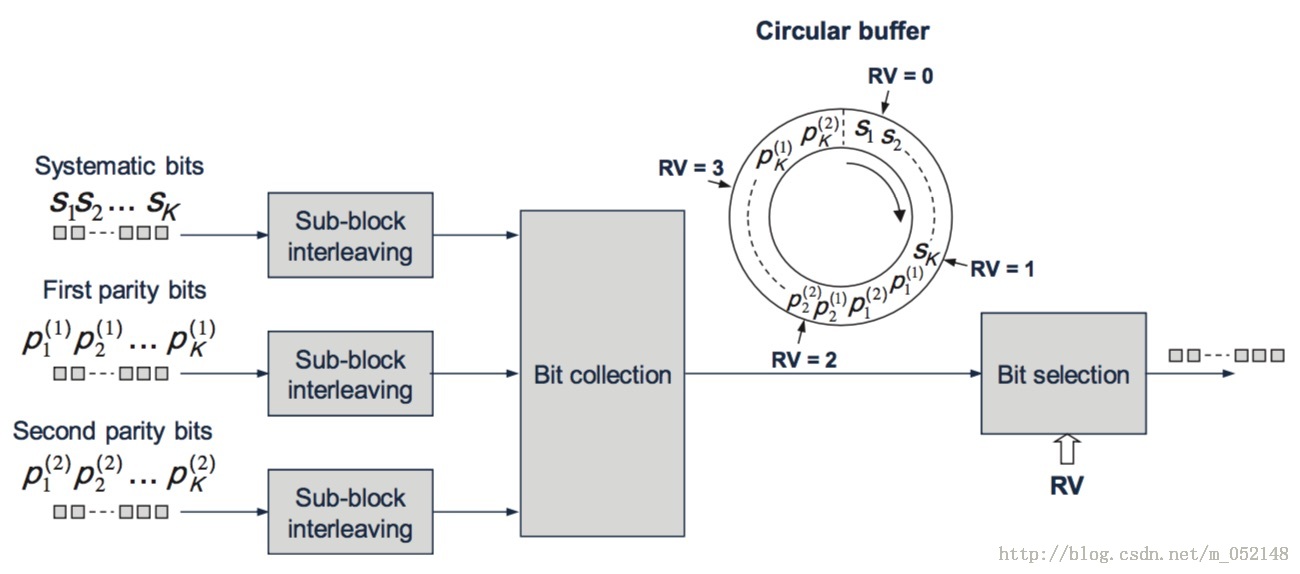
(图4)
我们知道,HARQ操作对应4种不同的冗余版本,分别是RV=0,1,2,3。经过比特收集过程,所有的比特流都被存入环形器中。接下来的比特选择(Bit selection)过程,就是从环形器中提取出连续的比特流。HARQ冗余版本RV值不同,从环形器中提取比特流的起始位置也将不同。
经过比特选择过程之后,输出的比特流就是上文图3中的e0,e1,...,e(E-1)。
(5)对(4)的结果进行多码块合并,生成一个长度为G的比特流。这个长度为G的比特流就是传说中的“码字(codeword)”,物理层需要传输的就是这个内容。
为了在空口中进行有效的数据传输,“码字”信息后续还要进行比特级的加扰、数据调制、层映射、预编码、RE映射等诸多过程。
2.计算有效信道码率
下面以FDD制式,20M带宽,MCS=28,RB=100,TM3单个传输块,CAT3能力终端,CFI=1,两天线端口,普通CP为例,说明有效信道码率的计算过程。
有效信道码率的计算公式 = 包含CRC的资源调度tbs / 所有RE可传的tbs。具体到本例,RB=100、MCS=28的资源,查表可以得到tbs = 75376 bits,经过码块分割后,形成M = ceil [ ( 75376 + 24 ) / ( 6144 - 24 ) ] = 13个CB块。所以总的资源调度tbs = 75376 + 24 + 13 * 24 = 75712 bits。由于CFI=1,配置两天线端口,所以可用的RE = (12 * ( 14 - 1 ) - 12) * 100RB * 6bits = 86400 bits,所以有效信道码率 = 75712 / 86400 = 0.876 < 0.93。需要说明的是,如果某个子帧包含了系统信息等,考虑有效信道码率的时候还需要扣除相应的RE。
3.计算Turbo编码码率
3GPP提供了一种有限缓存速率匹配(limited buffer rate matching,LBRM)的机制。在这种机制里,不同的UE终端,其能够使用的最大软缓存比特大小是不同的。
继续以FDD制式,20M带宽,MCS=28,RB=100,TM3单个传输块,CAT3能力终端为例,说明Turbo编码码率的计算过程。
通过查36213-7.1.7.2.1表可以知道,传输块TBS=75376 bits。经过码块分割后,形成M = ceil [ ( 75376 + 24 ) / ( 6144 - 24 ) ] = 13个CB块。此时传输块的比特数增加到:75376 + 24 + 13 * 24 = 75712 bits。
在协议标准里,用符号Nir来表示某个传输块的软缓存大小比特数(soft buffer size)。可以通过下面的公式1计算得到N_IR:
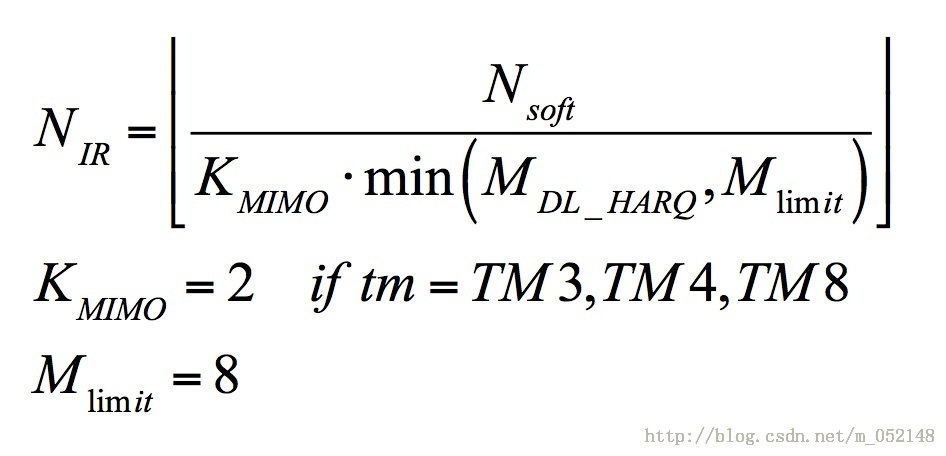
(公式1)
公式中的Nsoft由UE的能力决定,本例中UE能力为CAT3,所以Nsoft=1237248 bits。注意,这里很多人容易将“每个TTI内最多能调度的TBS”以及“每个TTI内每个TB块最多能传输的TBS”这两个概念与Nsoft相混淆。
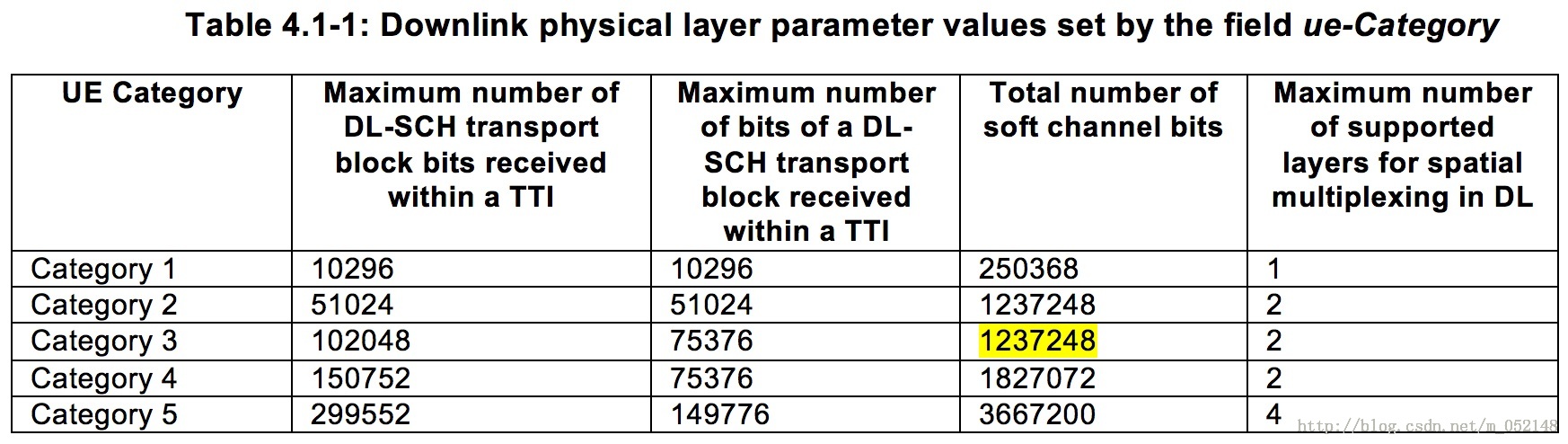
(图5)
M_DL_HARQ表示下行最大HARQ个数,对于FDD制式,M_DL_HARQ = 8。
将各个参数值代入公式1,可以得到 Nir = floor ( 1237248 / ( 2 * 8 ) ) = 77328 bits,所以Turbo编码码率 = 75712 / 77328 = 0.979 > 0.93,这也意味着此种情况下的冗余比特已经非常有限。协议并没有规定说Turbo编码码率必须要小于0.93,在实际设定调度算法时,各厂家可以根据自己的需求制定不同的目标值。
参考:
(1)3GPP TS 36.212 V9.4.0 (2011-09) Multiplexing and channel coding
(2)3GPP TS 36.213 V9.3.0 (2010-09) Physical layer procedures
(3)《4G LTE/LTE-Advanced for Mobile Broadband》