目录
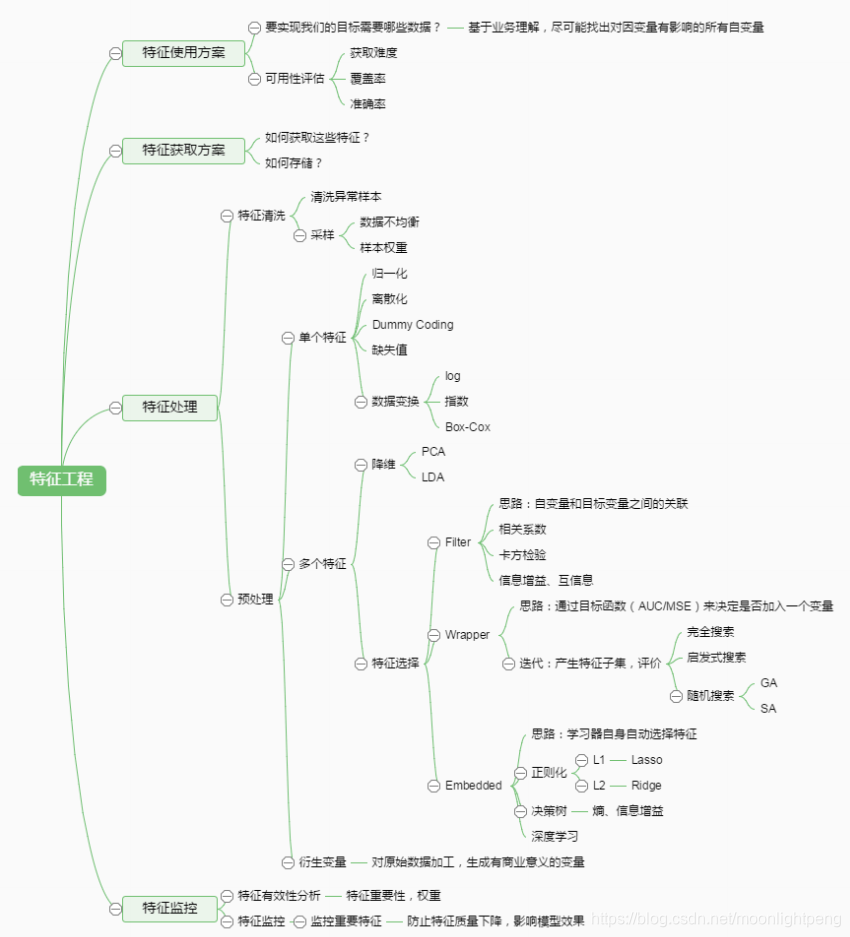
特征工程
模型选择
选择模型后,在一些超参数,需要选择不同的值
线性回归
特征的次数可以变化
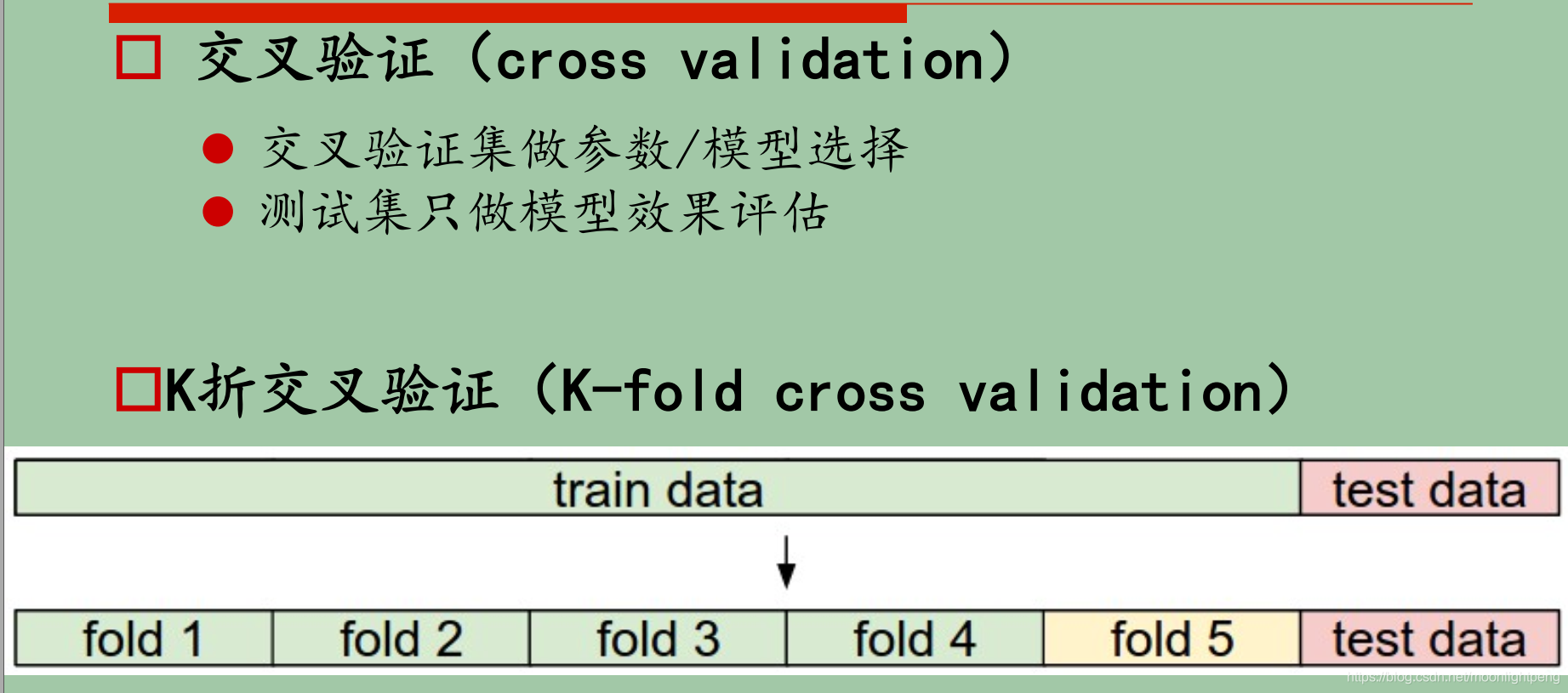
交叉验证
模型参数含义
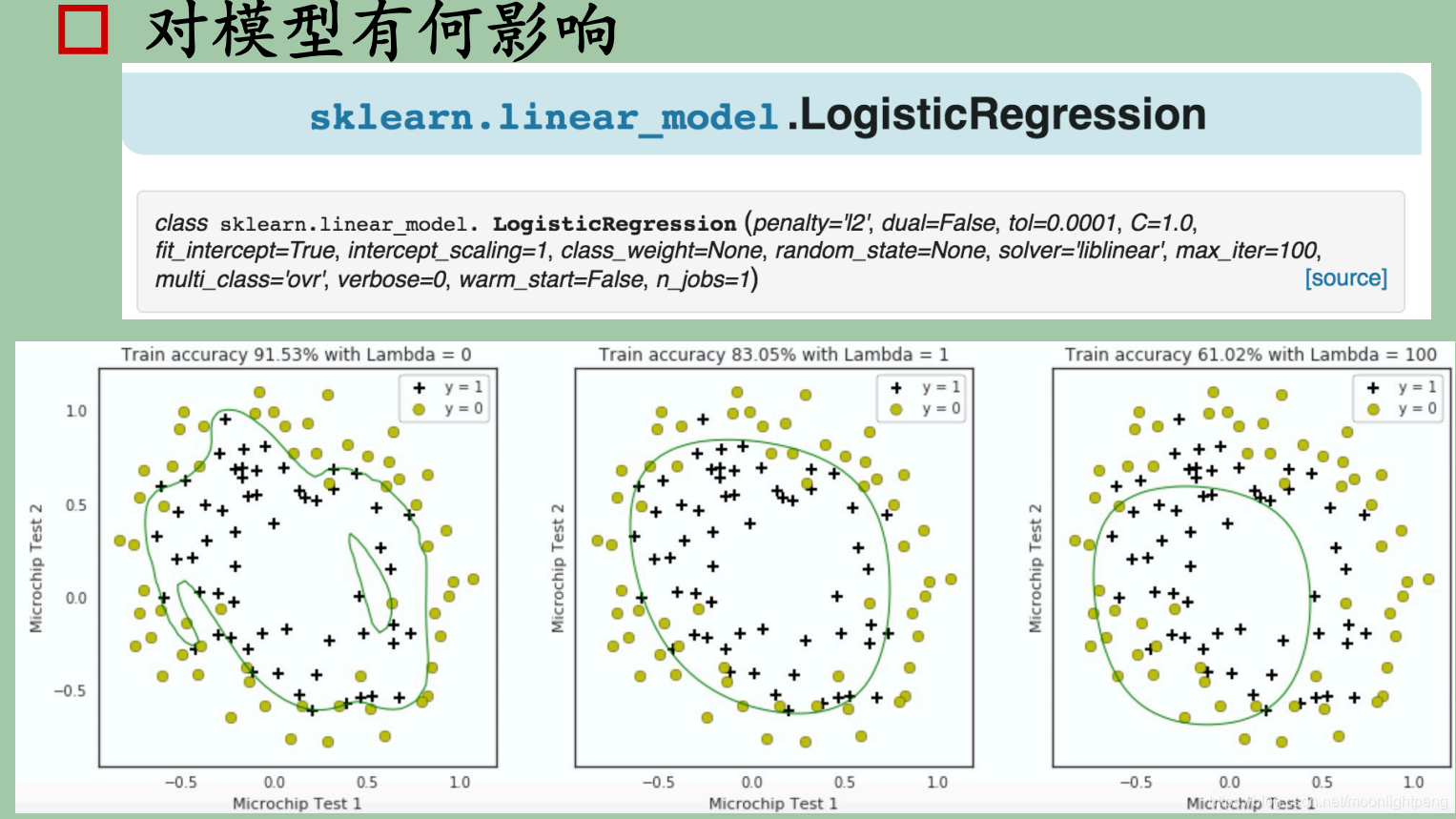

模型效果优化
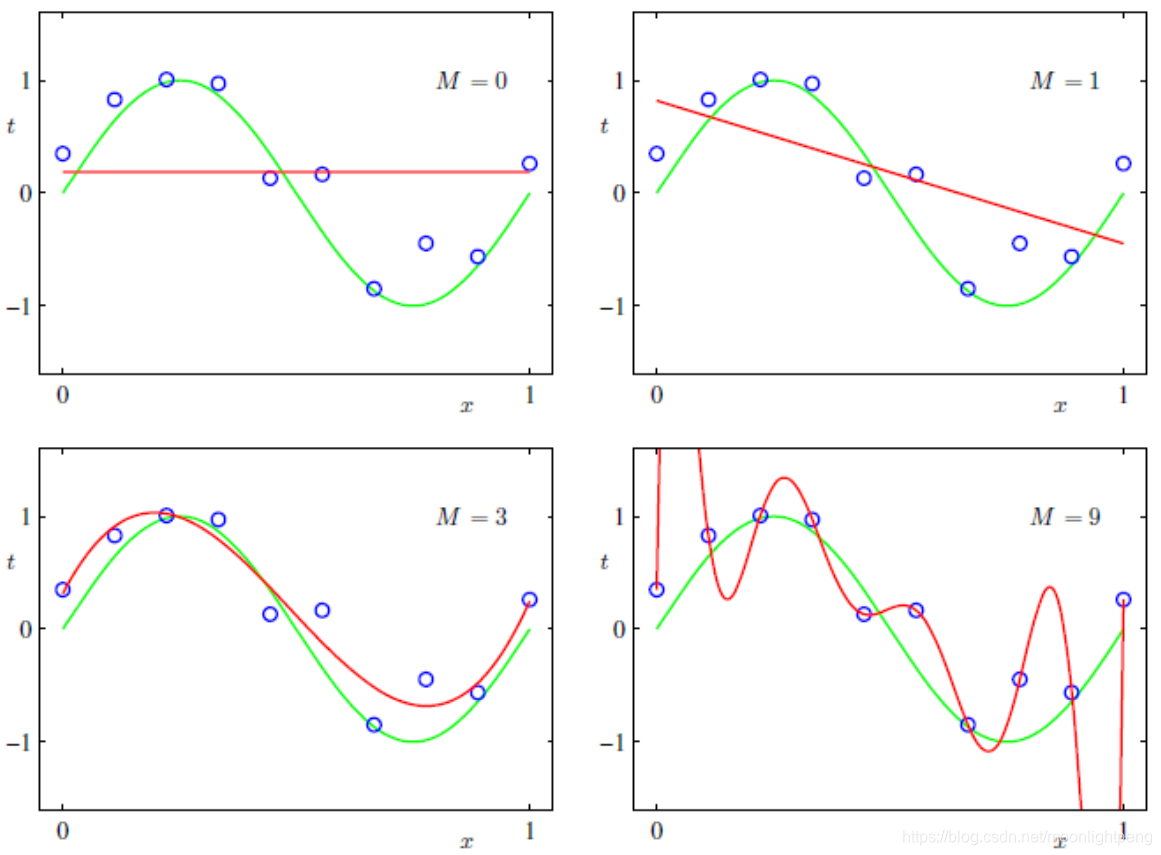
模型状态
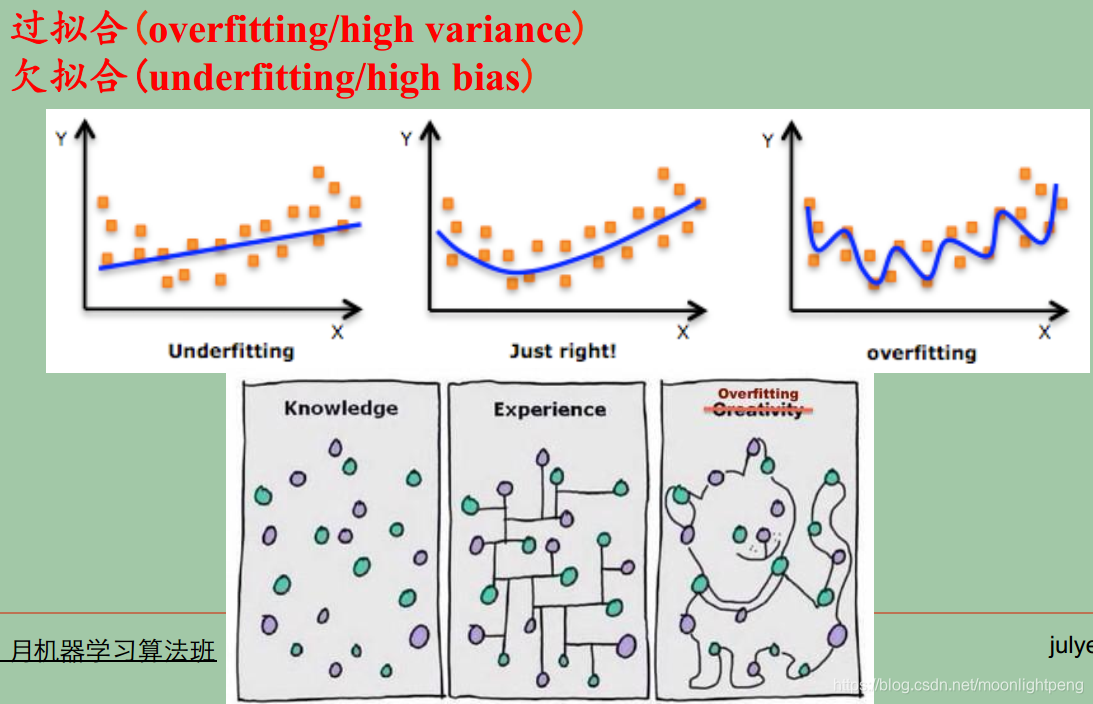
左边欠拟合,中间刚合适,右边边拟合
o 小笑话两则
一個非洲酋長到倫敦訪問, 一群記者在機場截住了他。
早上好, 酋長先生“ , 其中一人問道: 你的路途舒適嗎?
酋長發出了一連串刺耳的聲音哄、 哼、 啊、 吱、 嘶嘶,
然后用純正的英語說 道 : 是的, 非常地舒適。
那麼! 您准備在這里待多久?
他發出了同樣的一連串噪音, 然後答: 大約三星期, 我想。
酋長, 告訴我, 你是在哪學的這樣流利的英語? 迷惑不解的記者問。
又是一陣哄、 吭、 啊、 吱、 嘶嘶聲, 酋長說: 從短波收音機裡。
欠拟合: 觉得自己将来的白马王子又会赚钱又有颜
过拟合: 遇到几个渣男就得出结论“男人没一个好东西”
欠拟合: “ 你太天真了”
过拟合: “你想太多了”
模型状态验证工具: 学习曲线

欠拟合,过拟合,正适合
都很低可以欠拟合
训练集准确度很高但在交叉验证集上不好-----过拟合
不同模型状态处理
过拟合
Ø 找更多的数据来学习--可以缓解过拟合不能避免
Ø 增大正则化系数---不要太骄傲
Ø 减少特征个数(不是太推荐)
注意: 不要以为降维可以解决过拟合问题
欠拟合
Ø 找更多的特征----将一次变为二次
Ø 减小正则化系数
线性模型的权重分析
线性或者线性kernel的model
Ø Linear Regression
Ø Logistic Regression
Ø LinearSVM
Ø …
对权重绝对值高/低的特征
Ø 做更细化的工作
Ø 特征组合
特征前的系数有具体的物理意义,则对应其特征影响比较,可以对其做一些处理,如更加细化这个维度,或通过组合或统计上的处理
Bad-case分析
分类问题
Ø 哪些训练样本分错了?
Ø 我们哪部分特征使得它做了这个判定?
Ø 这些bad cases有没有共性
Ø 是否有还没挖掘的特性
Ø …
回归问题
Ø 哪些样本预测结果差距大, 为什么?
Ø 参考分类问题的思路
模型融合
ü 简单说来, 我们信奉2条信条
群众的力量是伟大的, 集体智慧是惊人的
Ø Bagging
Ø 随机森林/Random forest
一万小时定律
Ø Adaboost
Ø 逐步增强树/Gradient Boosting Tree
Bagging


bagging可以减少波动

最上面过拟合了
Adaboost
考得不好的原因是什么?
Ø 还不够努力, 练习题要多次学习
l 重复迭代和训练
Ø 时间分配要合理, 要多练习之前做错的题
l 每次分配给分错的样本更高的权重
Ø 我不聪明, 但是脚踏实地, 用最简单的知识不断积累,成为专家
l 最简单的分类器的叠加

符号变大了,注重于分错的样本,将其权重变大
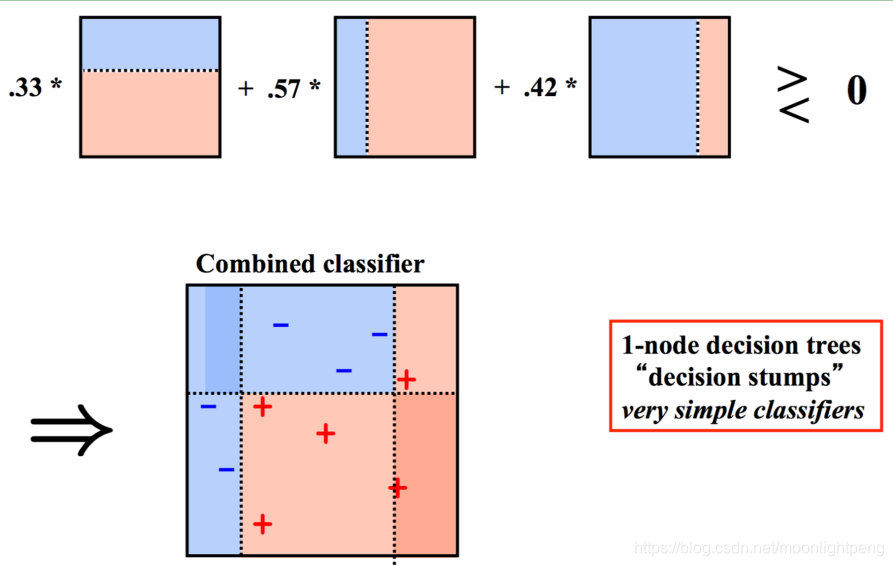
颜色深则每次能分对
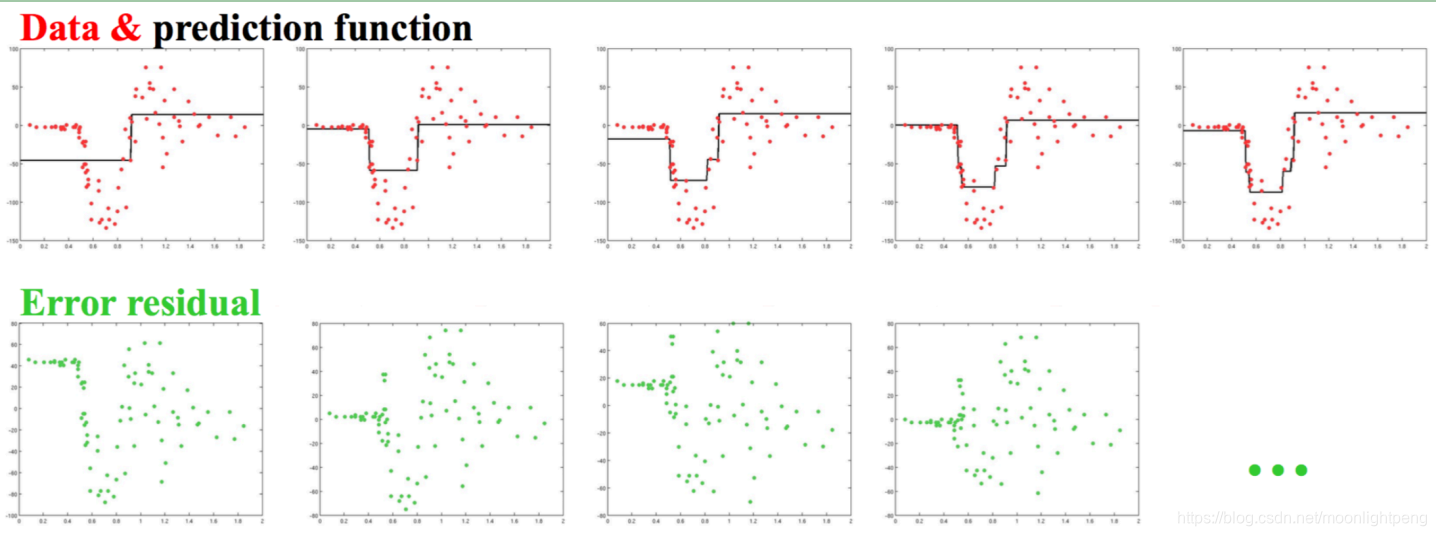
Gradient Boosting Tree
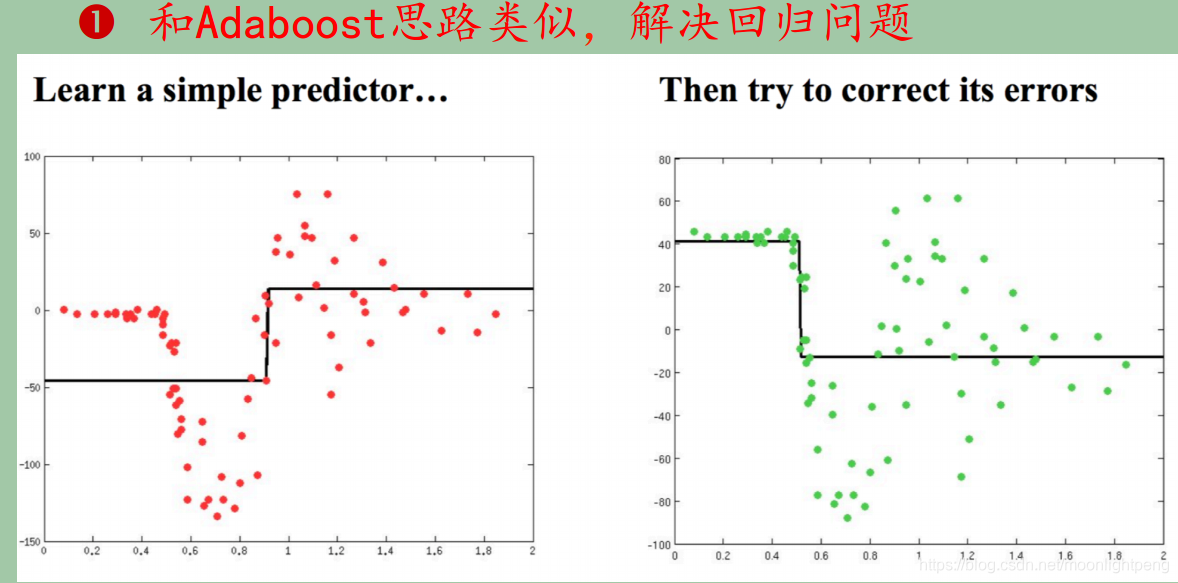
右边是没有拟合上的点集,残差
原始的值与样本点的差值
差值上学习出一条线,然后将两者相加,以依类推