文章目录
MySQL优化(SQL语句及索引优化)
最近在复习算法,为明年的春招做准备,欢迎互关呀,共同学习,进步!
一,慢查询日志
1.什么是慢查询日志?
MySQL的慢查询日志是MySQL提供的一种日志记录,它用来记录在MySQL中响应时间超过阀值的语句,具体指运行时间超过long_query_time值的SQL,则会被记录到慢查询日志中。long_query_time的默认值为10,意思是运行10S以上的语句。默认情况下,Mysql数据库并不启动慢查询日志,需要我们手动来设置这个参数,当然,如果不是调优需要的话,一般不建议启动该参数,因为开启慢查询日志会或多或少带来一定的性能影响。慢查询日志支持将日志记录写入文件,也支持将日志记录写入数据库表。
查看慢查询日志是否开启
show VARIABLES LIKE 'slow_query_log'

慢查询日志默认是没有开启的。
开启慢查询日志
set GLOBAL slow_query_log = ON;

我们再看看没有索引的查询会不会被记录到慢查询日志中
show VARIABLES LIKE 'log_queries_not_using_indexes'
默认是没有开启的

我们也要开启将没有使用索引的查询记录到慢查询日志中
set GLOBAL log_queries_not_using_indexes = ON
在查看一下

查看查询时间超过多少秒会被记录到慢查询日志中
show VARIABLES LIKE 'long_query_time'

为了能记录下所有的查询语句,方便学习,我决定将他设置为0
SET GLOBAL long_query_time = 0.000000

如果不能修改,可以关闭此次会话后新建一个会话重试
查看慢查询日志文件存放在哪
show VARIABLES LIKE 'slow_query_log_file'

设置下慢查询日志存放在自定义的路径
set GLOBAL slow_query_log_file = '自定义路径'
2.日志内容
这个就是慢查询日志记录的内容:

先看第一行,记录了日志记录时间
Time:140606 12:30:17
第二行,记录了执行SQL的主机信息
User@Host:root[root] @ localhost []
第三行,记录了SQL的执行信息,从左到右分别是:SQL执行耗时,锁定时间,发送行数,扫描行数及SQL执行时间
Query_time:0.000031 Lock_time:0.000000 Row_sent:0 Row_examined:0 SET timestamp = 1402029017
最一行是执行的语句
show Tables
3.分析SQL执行计划
使用expain查询SQL的执行计划
格式:
EXPLAIN SQL语句
比如:
EXPLAIN SELECT * FROM film_text
显示结果:

参数解释:
-
table:所查询的表
-
type:显示连接使用了何种类型,从最好到最差的连接类型分别是:
const(唯一索引查找) --> eq_reg(唯一索引或主键的范围查找) --> ref(连接查询) --> range(范围查找) --> index(索引扫描) --> ALL(表索引) -
possible_keys:显示可能应用在这张表中的索引,如果为空,没有可能的索引
-
key:实际使用的索引,为null则没有使用索引
-
key_len:使用的索引的长度,索引长度越短越好
-
ref:显示索引的哪一列被使用了,如果可能的话,是一个常数
-
rows:MYSQL认为必须检查的用来返回请求数据的行数
-
扩展列:
- Using fileSort使用了文件排序
- Using temporary使用了临时表
关于上文中的文件排序
当不能使用索引生成排序结果时,Mysql需要自己进行排序,此时会出现两种情况
- 当数据量小的时候,则在内存中进行,在内存中进行快速排序
- 当数据量大的时候,MySQL会将数据分块,对每个独立的块分别快速排序,将排序结果存在磁盘上,然后将每个排好序的块进行合并,最后返回排序结果
以上两种情况均属于文件排序
如何通过慢查询日志发现有问题的SQL
- 查询次数多其每次查询占用时间长的SQL
- IO大的SQL
- 未命中索引的SQL
二,SQL优化
1.优化count()和Max()
下边以tb_test表作为示例
CREATE TABLE `tb_test` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`test` varchar(255) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=latin1;

先看看普通MAX执行计划
EXPLAIN SELECT MAX(test) from tb_test

EXPLAIN SELECT MAX(test) from tb_test

覆盖索引:
- 解释一: 就是select的数据列只用从索引中就能够取得,不必从数据表中读取,换句话说查询列要被所使用的索引覆盖。
- 解释二: 索引是高效找到行的一个方法,当能通过检索索引就可以读取想要的数据,那就不需要再到数据表中读取行了。如果一个索引包含了(或覆盖了)满足查询语句中字段与条件的数据就叫做覆盖索引。
- 解释三:是非聚集组合索引的一种形式,它包括在查询里的Select、Join和Where子句用到的所有列(即建立索引的字段正好是覆盖查询语句[select子句]与查询条件[Where子句]中所涉及的字段,也即,索引包含了查询正在查找的所有数据)。
不是所有类型的索引都可以成为覆盖索引。覆盖索引必须要存储索引的列,而哈希索引、空间索引和全文索引等都不存储索引列的值,所以MySQL只能使用B-Tree索引做覆盖索引
从上图中的查询计划可以看出,使用了索引后,没有做表扫描,结果是从索引直接获得的,这就是上面提到的覆盖索引,**也可以这么理解,对于max和min这样的查询,对于max,只需要读到索引B-Tree的最后一个索引记录就可以取到max,相反,min的话只需要取到B-Tree中第一条索引记录即可,**这样即使数据量增大,查询效率几乎不受影响。
所以,对于max()查询的优化,我们可以通过给查询列建立索引的方式优化的我们的查询效率。
接下来我们看看count()这种如何优化?
我们先看看count(*)和count(某列)有什么区别?
我们新建一个表
CREATE TABLE `tb_count` (
`val` varchar(255) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=latin1;
注意该表可以包含null数据
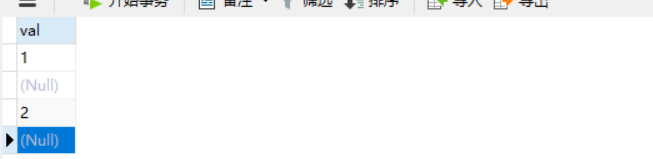
分别执行count(*)和count(val)
select count(*) as 'count(*)',COUNT(val) as 'count(val' from tb_count

可以看到
- count(*):表中所有行,不论是否是null
- count(指定列):只统计非null行
查看执行计划
EXPLAIN select COUNT(*) as 'count(val' from tb_count;
EXPLAIN select COUNT(val) as 'count(val' from tb_count
发现count(*)和count(指定列)的执行计划都是做了一个全表扫描,扫描行数还是全表的数据行数
我们尝试加一个索引
发现两者执行计划还是一样,只是这次用到了索引,效率比之前要高些,但是扫描行数大家都是4行

所以,在讨论如何优化count函数之前,我们得先明白count函数到底有什么作用?
count()函数有着两种非常不同的作用
- 他可以统计某个列值的数量(count(具体列))
- 也可以统计行数(count(*)),当这种情况下,他会忽略所有列进而统计所有行的行数
还有一个就是关于MyISAM这个存储引擎的count函数很快,其实是有条件的,就是当没有任何where条件的count(*)才非常快,如果带有where子句,那么跟其他存储引擎并没有什么区别,所以在MyISAM中执行count函数有时候比别的引擎快,有时候慢,看情况而定
count函数查询优化:
-
在MyISAM引擎中,我们可以这样简单优化下count函数查询,我们可以利用count(*)全表非常快这个特性,加速一些带有特定条件的count()查询,例如我们需要看一个5000行的数据里找到id大于5的行数,我们可以这样
select (select count(*) from table) - count(*) from table where id <= 5在这个sql中的子查询,可以用到MyISAM不带where子句时 count(*)特别快的特性,而且扫描的行数也仅仅只有5行
select count(*) from table如果这样的话,就不能发挥出MyISAM不带where子句时 count(*)特别快的特性,扫描的行数还特别大,足足有4995行
select count(*) from table where id > 5但是MyISAM不支持事务,所以还需要看具体业务而定,置于MyISAM中不带where条件的count(*)为何如此之快,是因为在MyISAM中维护了一个变量来存放所有数据行的行数。
2.子查询和关联查询优化
子查询优化:
还是上文那两张表,tb_test和tb_count
tb_test:

tb_count:

select * from tb_test where test in(select val from tb_count);
返回结果:

可以看到,原来在tb_count表中2是重复的(即存在一对多的关系),但是子查询的时候,查出来的结果却没有重复
我们现在改造成join的关联查询
select * from tb_test JOIN tb_count on tb_test.test = tb_count.val
结果:

这种一对多关系到了关联查询的时候,就会重复,所以还需要注意的是当子查询优化为关联查询时,需要注意去重
select DISTINCT * from tb_test JOIN tb_count on tb_test.test = tb_count.val
关于子查询优化,最关键的就是使用关联查询替代子查询,但在优化时要注意关联键是否存在一对多的关系,要注意重复数据的去重
关联查询优化:
在谈优化之前,我们先了解下在MySQL中关联查询如何执行?
mysql中,任何一次查询都是一次关联,每一个查询(包括子查询,表单的简单select)都可能是关联
基本执行思路是这样的:
MySQL现在一个表中循环取出单条数据,然后在嵌套循环到下一个表中寻找匹配的行,依次下去,知道找到所有表中匹配的行为止。然后根据各个表匹配的行,返回查询中需要的各个列。MySQL会尝试在最后一个关联表中找到所有匹配的行,如果最后一个关联表无法找到更多的行,mysql会返回上一层表,看能否找到更多记录
比如:
select tb1.col1 , tb2.col2 from tb1 inner join tb2 using(col3) where tb1.col1 in(5,6)
mysql执行该sql的伪代码如下:

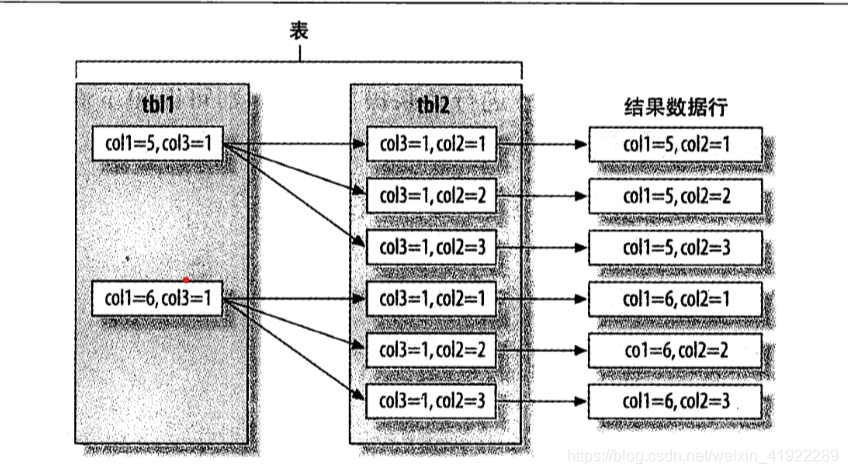
如何优化关联查询:
-
on或者using子句上的列上有索引,在创建索引的时候,要考虑关联顺序,一般来说,如果没有特别理由,只需要在关联顺序中的第二个表中的相关列建立索引即可,太多索引会占用空间
-
关联查询中的任何group by或者order by子句或者表达式中只涉及关联表中的一个表的列,这样mysql才可能使用索引来优化这个过程
3.group by优化
删除上文中的tb_count表中的index索引后查看sql执行计划
EXPLAIN SELECT * FROM tb_count GROUP BY val

可以看出在没有索引,group by做了一个全表扫描和使用到了文件排序和临时表
为了避免使用文件排序和临时表的情况,我们需要对sql进行一定的优化:
查找了网上一些博客分析GROUP BY 与临时表的关系 :
1. 如果GROUP BY 的列没有索引,产生临时表.
2. 如果GROUP BY时,SELECT的列不止GROUP BY列一个,并且GROUP BY的列不是主键 ,产生临时表.
3. 如果GROUP BY的列有索引,ORDER BY的列没索引.产生临时表.
4. 如果GROUP BY的列和ORDER BY的列不一样,即使都有索引也会产生临时表.
5. 如果GROUP BY或ORDER BY的列不是来自JOIN语句第一个表.会产生临时表.
6. 如果DISTINCT 和 ORDER BY的列没有索引,产生临时表.
所以:
- 如果要对关联查询做group by分组,那么要确保关联查询group by子句中使用到列应该只来自一张表,且该列应建立索引,另外, 应该注意分组和关联的顺序,先对该表分组、分组后再和其他表关联查询 。( 先利用索引将结果集快速最小化、然后再和其他表关联 )
- 普通单表查询的话索引就可以了
- order by也需要注意上面两点
4.limit优化
limit常用于分页处理,时长会伴随着order by从句使用,大多数时候都会使用文件排序造成大量的IO问题
EXPLAIN select * from tb_count ORDER BY val LIMIT 2

如果我们接下来使用有索引的列或者主键列进行order by操作

执行相同语句,看执行计划

可以看到,原来没有使用索引,扫描4行即全部数据行,使用了索引扫描2行,其实,limit在mysql中是这样做的,他是先进行全表扫描,然后在根据limit的参数进行结果集截取,但是当我们使用了索引,根据索引的排序性(BTree)我们可以轻松完成order by的工作,且扫描的行数大大降低,但是虽然这样,如果我们要扫描的行数过多,比如我从500行开始往后找5行,这样就会扫描505行,虽然说不用全表扫描,但是当越往后找,IO压力也会越大
EXPLAIN select * from tb_count ORDER BY val LIMIT 2 ,2

优化建议:
-
使用有索引的列或者主键列进行order by操作
-
要注意避免数据量大时扫描行数过多
三,索引优化
1.尽量不要出现重复索引
第一步
尽量不要出现重复索引,何为重复索引?重复索引是指相同的列以相同的顺序建立的同类的索引,比如主键和唯一索引
create table test(
id int not null primay key,
name varchar(10) not null,
title varchar(50) not null,
unique(id)
)engine = innodb
就像这里边的id既是唯一索引也是主键,就是重复索引.
2.减少冗余索引
第二:
减少冗余索引,什么是冗余索引就是指多个索引的前缀列相同,或是在联合索引中包含了主键索引
create table test(
id int not null primay key,
name varchar(10) not null,
title varchar(50) not null,
key(name,id)
)engine = innodb
上边就是在联合索引中包含了主键索引,导致索引冗余,因为innodb的特性,innodb会在没个索引的后边加上主键索引,
还有前缀列相同就是下边说到的联合索引的情况,
建立了联合索引(a,b,c)就没必要建立一个独立索引a
3.where子句后边的列索引只能用上1个
第三:
注意where子句后边的列不能都加上索引
select * from table where age = 1 and price > 100
where子句后边的age和price如果两个都是独立的索引,那么同时只能用上1个
4.多列索引必须遵循最左匹配原则
第四:
多列索引必须遵循最左匹配原则,索引顺序应该遵循离散度大的列放的越前
先说最左匹配原则
所谓最左匹配原则,就是假如我创建了联合索引index(a,b,c)
如果,我在查询中:
where a = 1 and b = 1 and c = 1 #索引中abc三列都走
where a = 1 and b = 1 #索引中ab两列走
where a = 1 and c = 1 #索引中ac两列走
所以从上面可以看出,最左匹配中的一个要求:索引中排第一的列必须出现,索引才会生效,比如上边是索引生效的组合可以有:
abc
ab
ac
a
所以不生效的如:
bc
b
c
上面都是等值查询,下边涉及到范围查询
1. where a = 1 and b = 1 and c > 1
2. where a = 1 and b > 1 and c = 1
上边的where子句中只有第一句会走索引,走索引中的abc列,第二句不走列c,这涉及到多列索引中第二个要求:当在查询中出现范围查询时, 存储引擎不能使用索引中范围条件右边的列
还有,建立了联合索引(a,b,c)就没必要建立独立索引(a)
如果有order by或者group by的情景,也要注意索引的有序性
比如:
where a = ? and b = ? order by c
这样可以建立key(a,b,c)的联合索引,order by 最后的字段是组合索引的一部分且放在组合索引最后,避免出现文件排序fileSort
5.尽量使用覆盖索引
第五:
**尽量使用覆盖索引(只访问索引的查询(索引列包含的查询列)减少select ***
比如在登录验证中:
select user_time from user where user_name = ? and password = ?
可以建立key(user_name,password,user_time)的联合索引
6.前导模糊查询不能使用索引
第六:
前导模糊查询不能使用索引
select * from table where title like '%ax'
该语句属于前导模糊查询,即使title是索引,也不能使用到
非前导模糊查询可以使用索引
select * table from title like 'abc%'
7.union,in,or都能命中索引推荐使用in
第七:
union,in,or都能命中索引,但是cpu耗费上,union < in < or
所以一般推荐使用in
比如:
select * from table where a = 1
union
select * from table where a = 2
直接告诉mysql怎么做,cpu耗费最少,但是一般推荐使用in
select * from table where a in (1,2)
or的话,cpu耗费最大,不建议
select * from table where a = 1 or a = 2
8.负向条件查询不能使用索引,可以优化为in查询
第八:
负向条件查询不能使用索引,可以优化为in查询,负向条件有:!=,< >,not in , not exists , not like
9.建立索引的列,不能为null,联合索引不存全为null的值
第九:
建立索引的列,不能为null,联合索引不存全为null的值
10.使用索引查询时,避免强制类型转换
第十:
在使用索引查询时,避免强制类型转换,强制类型转换会导致全表扫描,例如,phone本来是varchar类型
select * from table where phone = 123456789
这样就不能命中索引.
应改为:
select * from table where phone = '123456789'
