ZooKeeper的安装使用
ZooKeeper完结篇(API操作,shell命令,ZooKeeper ACL 以及分布式应用 )
一、概述
ZooKeeper是一个分布式应用所涉及的分布式的、开源的协调服务。
是Google的Chubby的开源实现
Zookeeper最早起源于雅虎的研究院的一个研究小组。在当时,研究人员发现,在雅虎内部很多大型的系统需要依赖一个类似的系统进行分布式协调,但是这些系统往往存在分布式单点问题。所以雅虎的开发人员就试图开发一个通用的无单点问题的分布式协调框架。在立项初期,考虑到很多项目都是用动物的名字来命名的(例如著名的Pig项目),雅虎的工程师希望给这个项目也取一个动物的名字。时任研究院的首席科学家Raghu Ramakrishnan开玩笑说:再这样下去,我们这儿就变成动物园了。此话一出,大家纷纷表示就叫动物园管理员吧——因为各个以动物命名的分布式组件放在一起,雅虎的整个分布式系统看上去就像一个大型的动物园了,而Zookeeper正好用来进行分布式环境的协调——于是,Zookeeper的名字由此诞生了。
分布式的引用可以建立在同步配置管理、选举、分布式锁、分组和命名等服务的更高级的实现的基础之上。ZooKeeper意欲设计一个易于编程的环境,它的文件系统使用我们所熟悉的目录树结构。ZooKeeper使用Java所编写,但是支持Java和C两种编程语言。
二、ZooKeeper节点
ZooKeeper提供的命名空间与标准的文件系统非常相似。一个名称是由通过斜线分割开来的路径名序列所组成的。ZooKeeper中每一个节点都是通过路径来识别。
ZooKeeper的节点是通过像树一样的结构来进行维护,并且并且每一个节点通过路径标识以及访问。除此之外,每个节点还拥有自身的一些信息,包括:数据、数据长度、创建时间、修改时间等等。从这样一类既含有数据,又可以作为路径表示的节点特点中可以看出,ZooKeeper的节点既可以被看做是一个文件,又可以看做是一个目录,它同时具有二者的特点。
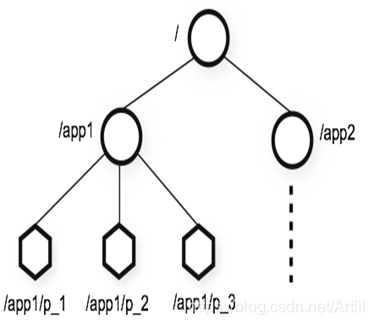
Znode还具有 原子性操作的特点:命名空间中。每一个Znode的数据将被原子地读写。读操作将读取与Znode相关的所有数据,写操作将替换掉所有的数据,除此之外,每一个节点都有一个访问控制列表,这个访问控制列表规定了用户操作的权限。
ZooKeeper节点是有生命周期的,这取决于节点的类型。在ZooKeeper中,节点类型可以分为持久节点(PERSISTENT)、临时节点(EPHEMERAL),以及时序节点(SEQUENTIAL),具体在节点创建过程中。一般是组合使用,可以生成以下4中节点类型。
持久节点(PERSISTENT)
持久节点,是指在节点创建后,就一直存在,直到有删除操作来主动清楚这个节点——不会因为创建该节点的客户端端会话失效而消失。
持久顺序节点(PERSISTENT_SEQUENTIAL)
类节点的基本特性和持久节点类型是一致的。额外的特性是,在ZK中,每个父节点会为他的第一级子节点维护一份时序,会记录每个子节点创建的先后顺序。
临时节点(EPHEMERAL)
与持久节点不同的是,临时节点的生命周期和客户端会话绑定。也就是说,如果客户端会话失效,那么这个节点就会自动被清除掉。
临时顺序节点(EPHEMERAL_SEQUENTIAL)
类节点的基本特性和临时子节点类型是一致的。额外的 特性是,在ZK中,每个父节点会为他的第一级。