近年来机器学习有了大幅增长,自动化机器学习也有很大需求。本文将从传统机器学习和深度学习两个角度介绍。
传统机器学习AutoML
CASH
AutoML的范围很广,可以包括从自动数据分析,自动特征工程,自动缩放,自动正则化,自动特征选择,自动模型选择,自动超参数优化等等。目前的研究方向,主要集中在CASH[1],既Combined Algorithm Selection and Hyperparameter Optimization。
CASH问题最早由Auto-Weka[1]的作者Thornton提出,他同时提出了用贝叶斯优化 [2] 解决。
贝叶斯优化
在介绍贝叶斯优化之前,先回顾一下有哪些找极值的方法。最简单的当然是网格搜索和随机搜索。任何学过机器学习的人,都应该知道梯度下降。那么为什么这里不用梯度下降,而用贝叶斯优化呢?因为梯度下降要求目标函数是凸函数,可微分。我们并不知道机器学习算法的超参数是不是这样的函数,所以,我们用了更加通用的贝叶斯优化。他的好处是,不需要凸函数,不需要可微分。
贝叶斯优化我们把我们要研究的这个黑盒函数叫做目标函数Objective Function。因为目标函数的开销大,我们要给他找一个近似函数,这个函数叫代理函数Surrogate Function。代理函数会计算出一条平均值曲线和对应的标准差(Standard Deviation)。有个代理函数,我们就可以找到一下个探索点。这个过程,用一个获取函数Acquisition Function里实现。
贝叶斯优化,是在一个特定的搜索空间search space展开的。
整个过程如下:
- 在搜索空间中,选几个初始点X
- 用目标函数计算初始点X对应的解y
- 更新代理函数
- 通过acquisition function获得下一个样本点。
- Goto 2
中英文流程图如下:

下面是一个具体的例子:
假如我们有如下的目标函数:

我们计算了x=0和1时的两个值,代理用他们拟合了平均值和方差如下:

上图中的蓝色线段为我们的目标函数,绿色的是通过代理函数拟合的平均值,绿色虚线是平均值减去或者加上标准差。或者说,代理函数认为真实函数的值的范围在绿色虚线范围内。
这时,我们可以根据代理函数提供的信息,去寻找下一个点。这里,我们的代理函数用的算法是UCB (Upper Confidence Bound),他找下一个点的方法是找平均值和标准差的和。这里我们忽略beta,或者说我们让beta等于1。
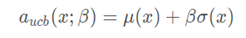
这时,我们看到,最大值出现在5.5附近。我们用这个x,带入目标函数,求得对应的y。这样,我们就有了三个样本点了。这时,我们继续。



我们看到,经过4次迭代,贝叶斯优化已经很接近最大值了。
比起其他的优化方法,贝叶斯优化掉用目标函数次数比较少。而我们知道,机器学习拟合函数(fit)是一个开销比较大的函数,如果是深度学习,那就更大了。
比起梯度下降,贝叶斯优化不容易陷入局部最优解。
Auto-Sklearn
Auto-Sklearn[3]继承了Auto-Weka的贝叶斯优化,并在贝叶斯优化的基础上,提出了两个新的改进。

一个改进是meta-learning,Auto-Sklearn通过机器学习的方法,根据数据集的大小,数据集的目标等特征可以大致估计出应该选择的超参数。这样可以减小超参数的搜索空间,从而提高了效率。
另一个改进是ensemble learning,通过ensemble,可以提高准确率。
笔者安装了Auto-Sklearn,并用我们最常见的,Kaggle中的泰坦尼克和波斯顿房价做了实验,实验用的CPU是一块i7。两个数据库,都跑了一个小时。成绩score分布是0.76和0.85。这个表现,一般对准确率要求没那么高的场景,应该可以应付了。
Auto-Skleran并不会处理任何的字符行的特征。所以,只能自行删除泰坦尼克里面的名字,船票等字符型特征。登船地点,性别也只能自行OneHot,或者转成布尔型。
示例代码:
import autosklearn.classification
cls = autosklearn.classification.AutoSklearnClassifier()
cls.fit(X_train, y_train)
predictions = cls.predict(X_test)
官网:
https://automl.github.io/auto-sklearn/master/
深度学习AutoML
原生NAS
Neural Architecture Search[4]是现在深度学习自动化的主要研究方向。原生的NAS用字符串表示深度模型,这样,就把深度学习模型里层(Layer)的预测,转化成了一个RNN的问题。NAS把这个RNN叫做控制器Controller。通过强化学习,控制器不断的调整自己的参数。

这样,就可以训练出串联模型了。
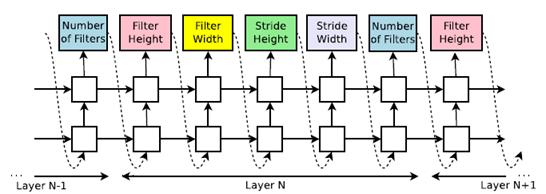
那么,如果模型有分叉怎么办呢?
NAS的办法是,训练N-1个二分类,用来预测当前层(第N层),分别和前面的(N-1)成的哪个层相连接。
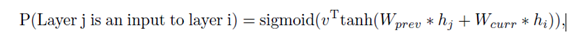
NAS发现了很多新的结构,比如:

上图中的第一个为原始的LSTM,后面两个为NAS发现的。
NAS家族
NAS出现以后,不同的学者提出了很多不同的NAS。香港浸会大学的he xin[5]等人对其进行了总结。这些新的NAS用了不同的控制器算法,有网格搜索、随机搜索、强化学习、遗传算法(EA)、贝叶斯优化、梯度下降等。在提高效率方面,也想出了Low Fidelity, Transfer Learning, Surrogate, Early Stopping等方法。
Low Fidelity是指减少深度学习的数据量,使其更快收敛。Transfer Learning迁移学习保留了之前的层的参数,只训练新加入的层。Surrogate是指用代理函数。Early Stopping提前结束训练,也可以节省计算资源。
下图是各种NAS的比较:

Network Morphism
在NAS的时候,我们会不断的尝试新的网络结构。如果,我们可以让新的网络从已经训练过的网络学习参数,就可以大大的节省时间了。
Network Morphism[6]很好的解决了这个问题。NM有人翻译成网络变形,也有翻译成网络态射的。网络变形把父网络的知识迁移到子网络,这样,子网络可以达到高于或者等于父网络的表现。
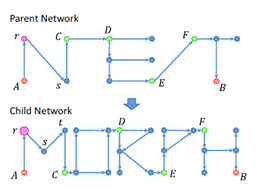
他主要包括线性变化,非线性变化,宽带变化,Kernal变化,子网变化等。
线性变化
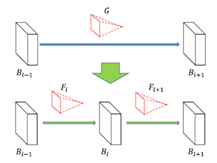
网络从第l-1层到第l+1层,线性变化的时候,其实就是乘了矩阵G。那么,我们把G分解成Fl和Fl+1就完成了变形。
非线性变化
非线性变化,无法像线性变化一样处理。在两个激活函数(φ)中间直接插入一个激活函数肯定不行。所以,有了一个Parametric Activation Function,或者叫P激活函数。
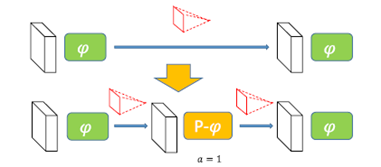
他的思路是,a的初始值是1,这样一开始P激活就退化成了Identity矩阵了。以后a的值会被训练出来。
宽度独立变化

带浪线的是子网的函数,经过一系列变化,可以得到
这时,我们只要让乘式两边其一为0,另一个为随机值即可。
Kernal独立变化
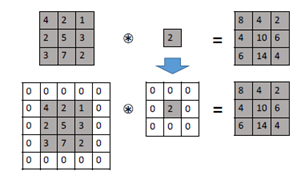
Kernal变化比较简单,只需要做Padding。
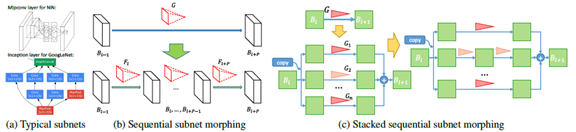
子网变化
子网变化分为两步,第一步是不断的执行线性或者非线性变化,插入新的层。第二步产生分支,既把G等分。
AutoKeras
AutoKeras是一款基于Keras的开源的AutoML框架。他采用了贝叶斯优化和网络变形等技术。目前,他支持CNN,RNN和简单的深度学习模型的搜索。
只需要四行代码,就可以自动搜索出一个神经网络。
import autokeras as ak
clf = ak.ImageClassifier()
clf.fit(x_train, y_train)
results = clf.predict(x_test)
具体可以参考其官网:
https://autokeras.com/
运用场景
AutoML针对的是比较成熟的人工智能解决方案。这时,调参和神经网络的结构已经有了成熟的解决方案。这些场景包括传统的机器学习,图像识别,目标检测,文本识别等。
对于语音等不成熟的人工智能解决方案,还无法使用AutoML。
参考
[1] C. Thornton, F. Hutter, H. Hoos, and K. Leyton-Brown. Auto-WEKA: combined selection and hyperparameter optimization of classification algorithms. In Proc. of KDD’13, pages 847–855, 2013.
[2] E. Brochu, V. Cora, and N. de Freitas. A tutorial on Bayesian optimization of expensive cost functions, with application to active user modeling and hierarchical reinforcement learning. CoRR, abs/1012.2599, 2010.
[3] Efficient and Robust Automated Machine Learning, Feurer et al., Advances in Neural Information Processing Systems 28 (NIPS 2015).
[4] Zoph, Barret, and Quoc V. Le. “Neural Architecture Search with Reinforcement Learning.” arXiv: Learning (2016).
[5] He, Xin, Kaiyong Zhao, and Xiaowen Chu. “AutoML: A Survey of the State-of-the-Art…” arXiv: Learning (2019).
[6] Wei, Tao, et al. “Network morphism.” international conference on machine learning (2016): 564-572.