目录
1.简介
在离线数仓中,我们常常会把DB数据以及日志数据抽取到数仓的ODS层。关于DB数据抽取我们一般采用DataX直连mysql select * 的方式,这种方法在业务初期数据量较小的时候不会对业务DB造成什么影响,但是随着数据量的增加,问题就逐渐暴露出来。
缺点为:
1)容易产生慢查询,会影响线上业务
2)抽取时间过长,无法满足数仓生产的时效性
为了解决这些痛点,我们可以采用 history_data + binlog_data (‘binlog实时采集变化数据’ merge ‘历史数据’)的方案,通过阿里的开源项目Canal,从MySQL实时拉取Binlog并完成解析合并。
2.方案架构
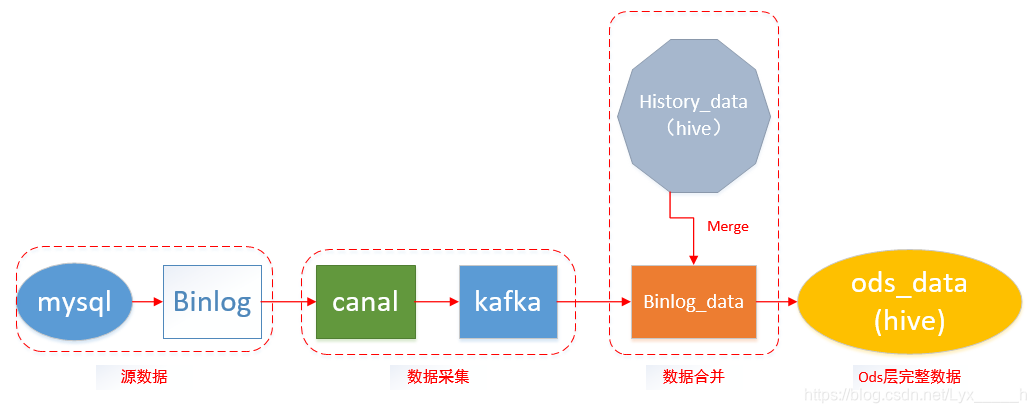
整体的架构如上图所示。在Binlog实时采集方面,采用了阿里巴巴的开源项目Canal,负责从MySQL实时拉取Binlog并完成适当解析。之后由数据平台组的同学负责将数据放到hdfs对应路径下,接着再由数仓同学做merge操作。详细canal操作网上教程已经很多了,本文就不做过多解释啦!
3.离线还原数据
3.1.数据落盘至hdfs
由于Canal采集的时候订阅的是整个mysql库的binlog,因此每个数据库的binlog日志会存储在同一个文件中 。我们以天为单位,每天产生一个文件。通过hadoop fs -ls 我们可以看到数据已经产生了。

3.2 Merge操作
mysql中支持增、删、改,我们的binlog会将这3种操作记录下来。但是需要知道的是hive不支持删、改操作,因此对于这种操作我们需要进行特殊的处理。
我们的思路是
1)将当天产生的binlog数据 (INSERT、UPDATE)与历史数据合并
2)通过对比历史数据,找出每个id最后一条更新的记录
3)将binlog中DELETE的数据过滤删除
3.3 Merge sql 代码
3.3.1 首先创建一个快照表来存放test库的binlog日志
CREATE EXTERNAL TABLE IF NOT EXISTS tmp_ods_zhidao_binlog_test_df
(
content string COMMENT '日志内容'
)
COMMENT 'binlog同步测试表'
PARTITIONED BY (dt STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS INPUTFORMAT 'com.hadoop.mapred.DeprecatedLzoTextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION '/user/hive/warehouse/zhidao.db/tmp_ods_zhidao_binlog_test_df';
3.3.2 创建一个待还原的ods层hive表
CREATE EXTERNAL TABLE IF NOT EXISTS temp_zhidao_test_car_poi
(
id STRING COMMENT 'id'
,name STRING COMMENT '姓名'
)
COMMENT '测试test_car_poi'
PARTITIONED BY (dt STRING )
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS orc
LOCATION '/user/hive/warehouse/zhidao.db/temp_zhidao_test_car_poi';
3.3.3 在hive中还原出与mysql相同的数据(binlog+历史数据)
3.3.3.1 binlog demo
# insert
{
"data":[
{
"id":"5",
"name":"张三"
}
],
"database":"bigdata_test",
"es":1574668868000,
"id":4,
"isDdl":false,
"mysqlType":{
"id":"bigint(20)",
"name":"char(20)"
},
"old":null,
"pkNames":[
"id"
],
"sql":"",
"sqlType":{
"id":-5,
"name":"张三"
},
"table":"test_car_poi",
"ts":1574668868389,
"type":"INSERT"
}
# update
{
"data":[
{
"name":"李四"
}
],
"database":"bigdata_test",
"es":1574668972000,
"id":5,
"isDdl":false,
"mysqlType":{
"name":"char(20)"
},
"old":null,
"pkNames":null,
"sql":"",
"sqlType":{
"name":"李四"
},
"table":"test_car_poi",
"ts":1574668972601,
"type":"UPDATE"
}
# delete
{
"data":[
{
"id":"4"
}
],
"database":"bigdata_test",
"es":1574669054000,
"id":7,
"isDdl":false,
"mysqlType":{
"id":"bigint(20)"
},
"old":null,
"pkNames":[
"id"
],
"sql":"",
"sqlType":{
"id":-5
},
"table":"test_car_poi",
"ts":1574669054657,
"type":"DELETE"
}
通过demo我们可以看出每种binlog操作都是以json格式存储的。知道了格式我们就有办法处理了。
3.3.3.2 全量数据合并
注意:
1) 这里我们用es字段来判断更新时间
2) 同一个id在每天可能update多次
DROP TABLE IF exists zhidao.temp_zhidao_test_car_poi_20200520_001;
CREATE TABLE IF NOT EXISTS zhidao.temp_zhidao_test_car_poi_20200520_001 AS
-- INSERT UPDATE
select
get_json_object(regexp_replace( regexp_replace((get_json_object(content,'$.data')),'\\[',''),'\\]',''),'$.id') as id,
get_json_object(regexp_replace( regexp_replace((get_json_object(content,'$.data')),'\\[',''),'\\]',''),'$.name') as name
from_unixtime(floor((get_json_object(content,'$.es'))/1000),'yyyy-MM-dd HH:mm:ss' ) as es
from
zhidao.tmp_ods_zhidao_binlog_test_df a -- 此表存放的是binlog日志
where dt='2020-05-20'
and get_json_object(content,'$.table')='test_car_poi'
and get_json_object(content,'$.type') in ('INSERT' ,'UPDATE')
union all
-- 前一日旧数据
select
id,name,
concat(date_sub('2020-05-20',1),' 00:00:01') as es -- 给前一天数据标记一个es
from
zhidao.temp_zhidao_test_car_poi a
where dt=date_sub('2020-05-20',1) ;
3.3.3.3 写入数据(同时过滤掉mysql中已删除的记录)
INSERT OVERWRITE TABLE zhidao.temp_zhidao_test_car_poi PARTITION(dt='2020-05-20')
SELECT a.id,a.name
FROM
(SELECT * -- 找出最新的一条记录
FROM (SELECT id,name,
ROW_NUMBER() OVER (PARTITION BY id ORDER BY es DESC ) as rn
FROM zhidao.temp_zhidao_test_car_poi_20200520_001
) t
WHERE rn=1) a
LEFT JOIN -- 删除delete的数据
(select
get_json_object(regexp_replace( regexp_replace((get_json_object(content,'$.data')),'\\[',''),'\\]',''),'$.id') as id
from
zhidao.tmp_ods_zhidao_binlog_test_df a
where dt='2020-05-20'
and get_json_object(content,'$.table')='test_car_poi'
and get_json_object(content,'$.type')='DELETE'
) b on a.id=b.id
WHERE b.id is null -- 删除delete的数据
;
因为此方法存在ROW_NUMBER()排序,运行时间成本会比较大。如果大家有什么更好的看法,欢迎各位大神一起交流探讨。