简介
在数仓建设中,数据同步是最基础的一步,也是 ods 层数据的来源。数据同步 简而言之,就是把 业务库中的需要分析的数据表(或文件) 同步到 数仓中(hdfs)。
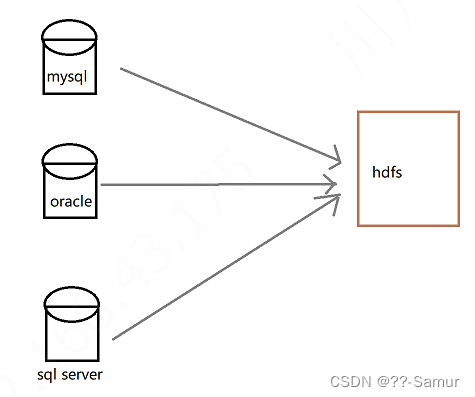
同步的方式可以分为3种:直连同步、数据文件同步、数据库日志解析同步。
下面将进行详细介绍。
详解
1、直连同步
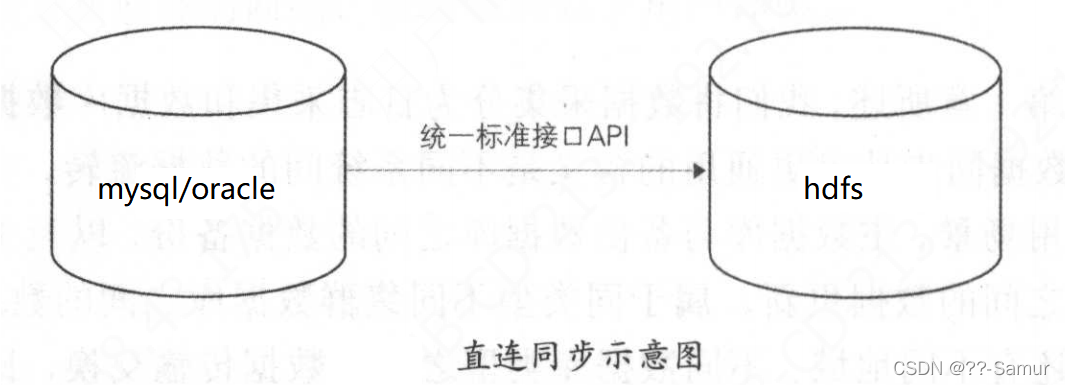
直连同步是指通过定义好的规范接口api 和动态链接库的方式直连业务库。
优点:配置简单,实现容易,比较适合操作型业务系统的数据同步。
缺点:
1、直连的方式对源系统的性能影响较大,甚至可能拖垮业务系统;
2、数据量很大时,性能很差。
2、文件传输
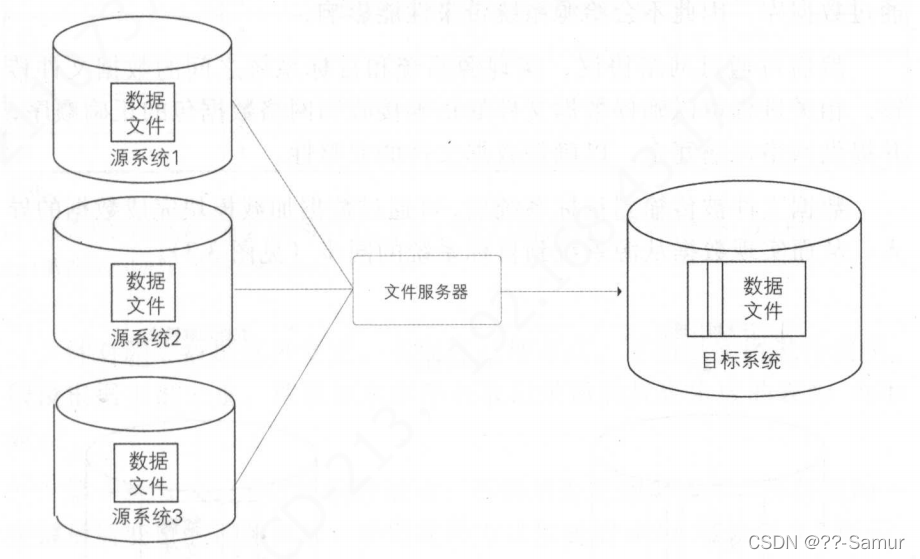
原理:从源系统生成数据的文本文件(比如 csv、json 等),然后由文件服务器(如FTP服务器)传输到目标系统(hdfs),最后加载到数据库系统中。
日志类数据通常以文件的形式存在的,比较适合这种方式。
缺点:通过文件服务器上传、下载容易造成丢包,需要设置校验机制。
3、数据库日志解析同步
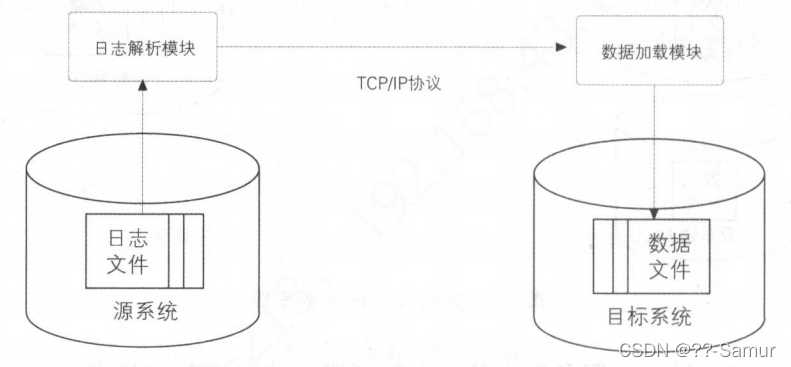
实现方式如下:
1、在源系统端,需要收集数据变更日志,将其写到文件中;
2、然后通过网络将文件传输到 目标系统;
3、目标系统解析该文件,然后加载到数据库(hdfs);
优点:
1、现在主流数据库都支持通过日志文件进行系统恢复,因此可以使用这种方式;
2、读取日志文件属于系统层操作,不会影响到业务库性能;
3、速度快,该方式可以达到 实时/准实时 的同步能力,延迟到毫秒级。
缺点:
1、可能出现数据延迟。业务系统批量写入 导致数据更新量超出系统处理峰值,导致数据延迟;
2、投入大,需要部署一个实时抽取数据的系统;
3、可能会导致数据漂移和遗漏。
主流工具及原理
下面介绍目前用得比较多的工具
1、sqoop
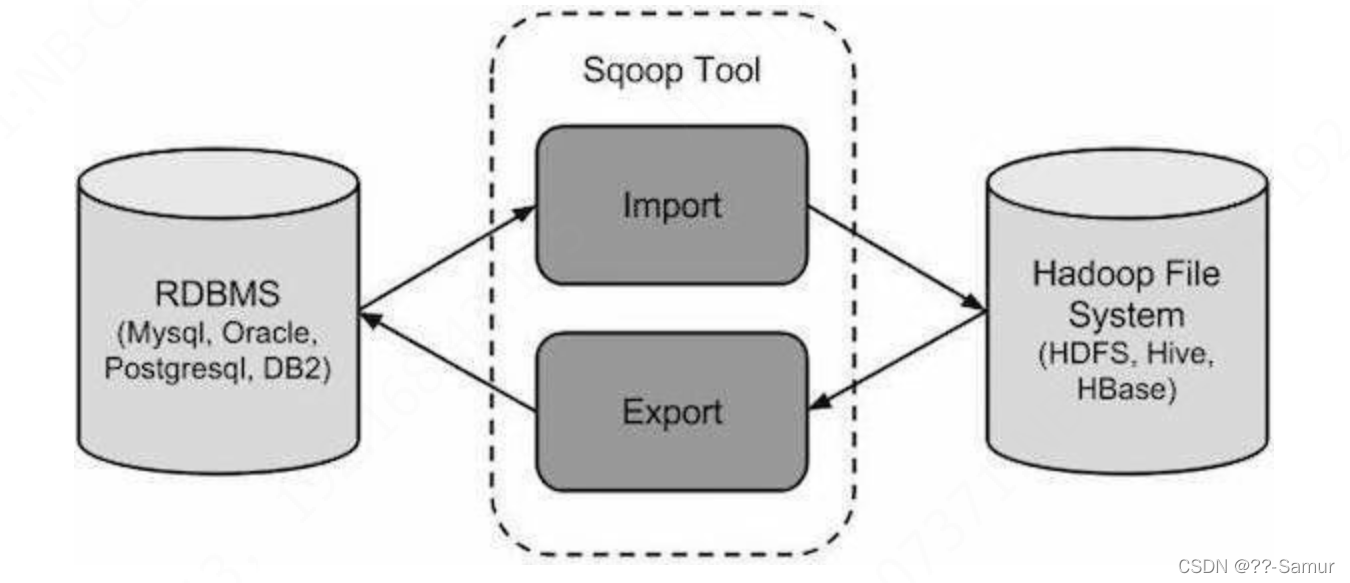
sqoop 是Apache旗下的一款数据同步工具, 它的工作原理属于第一种方式,具体过程如下
1、通过jdbc来获取需要的数据库的元数据信息,例如:导入的表的列名,数据类型;
2、根据 元数据 生成一个与表名相同的 java 类;
3、执行查询数据操作,并根据每一行数据生成一个java对象;
4、开启MapReduce作业,将每个对象反序列化写到 hdfs上。
2、flume
Flume是一个分布式、可靠、和高可用的海量日志采集、聚合和传输的系统。Flume可以采集文件、socket数据包等各种形式源数据,
并输出到:HDFS、hbase、hive、kafka等众多外部存储系统中。也是 apache 旗下的一个项目。
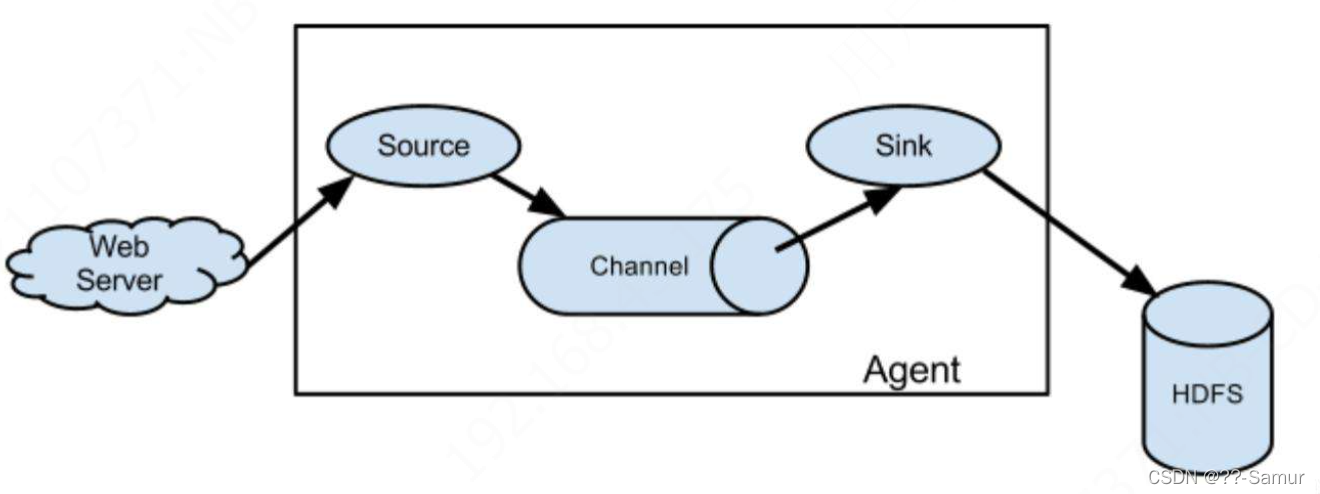
flume数据同步方式属于 第二种,它包含 3个组件:source、channel、sink。
source:主要负责 监控并采集 目标数据文件(比如日志)
channel:可以将它看做一个数据的缓冲区(数据队列),它可以将数据暂存到内存中也可以持久化到本地磁盘上
sink:对接到外部的数据目的地,将数据写到目标系统中。
3、dataX
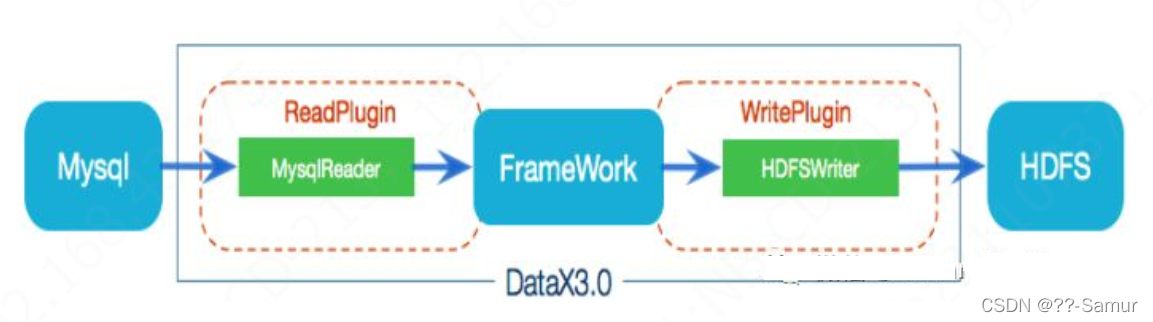
dataX 是阿里旗下一款开源的 数据同步工具,它的工作原理属于 第三种。它采用Framework + plugin架构构建。将数据源读取和写入抽象成为Reader/Writer插件,纳入到整个同步框架中。
Reader:数据采集模块,负责采集数据源的数据库写日志,将数据发送给Framework。
Writer: 数据写入模块,负责不断向Framework取数据,并根据日志写入到目的端。
Framework:作为reader和writer的数据传输通道,并处理缓冲,流程控制,并发,上下文下载等核心技术问题。
针对不同的数据库,只需要更换相应的 reader/writer 插件即可。全程在内存中运行,支持 单/多线程。
总结
本文主要列举了几种常见的离线开发 数据同步原理 及 目前主流工具,仅作一个简介。
看到这的同学记得点个赞哟,你的支持就是别人的动力~~~