文章目录
1.环境准备
1.1 mysql准备
由于本篇需要使用zikpin对链路信息进行保存,需要使用到mysql环境,mysql安装链接:《linux下安装mysql-5.7.25详细步骤》
1.2 服务准备
我们本篇文章还将继续使用《SpringCloud之Gateway使用篇》文中环境,如果没有还可以根据服务清单准备
环境服务清单:
| 服务 | 解释 | 端口 |
|---|---|---|
| spring-cloud-parent | 父工程,管理依赖版本与公共依赖,下面服务皆是子模块,springcloud版本Greenwich.RELEASE | 无 |
| spring-cloud-eureka-server | Eureka Server 集群 ,2个实例 | 9090,9091 |
| spring-cloud-order-service-provider | 订单服务(服务提供者),2个实例 | 7070,7071 |
| spring-cloud-user-service-consumer | 用户服务(服务调用者),2个实例 | 8080,8081 |
| spring-cloud-gateway-server | 微服务网关,2个实例(本环境使用一个即可) | 8020,8021 |
| spring-cloud-zipkin-server | zipkin server 1个实例(属于新项目) | 9100 |
2. 使用
2.1 zipkin server
zipkin server 是接收所有微服务上报链路信息与展示的一个服务,需要我们在原有基础上新建Module: spring-cloud-zipkin-server,然后我们分配的端口是9100
2.1.1 pom文件
这里需要引入zipkin server 的依赖与zipkin server ui ,数据库,数据库连接池等依赖
<dependencies>
<!--zipkin-server的依赖坐标-->
<dependency>
<groupId>io.zipkin.java</groupId>
<artifactId>zipkin-server</artifactId>
<version>2.12.3</version>
<exclusions>
<!--排除掉log4j2的传递依赖,避免和springboot依赖的日志组件冲突-->
<exclusion>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-log4j2</artifactId>
</exclusion>
</exclusions>
</dependency>
<!--zipkin-server ui界面依赖坐标-->
<dependency>
<groupId>io.zipkin.java</groupId>
<artifactId>zipkin-autoconfigure-ui</artifactId>
<version>2.12.3</version>
</dependency>
<!--关于mysql配置-->
<dependency>
<groupId>io.zipkin.java</groupId>
<artifactId>zipkin-autoconfigure-storage-mysql</artifactId>
<version>2.12.3</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.1.10</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-tx</artifactId>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-jdbc</artifactId>
</dependency>
</dependencies>
2.1.2 application.yml
配置主要分为三部分,1是服务信息配置,端口,服务健康 ;2是数据源的配置;3是指定zipkin的数据存储介质
server:
port: 9100
management:
metrics:
web:
server:
auto-time-requests: false # 关闭自动检测请求
# 配置datasource信息
spring:
datasource:
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://XXX.XXX.XXX.XXX:3306/zipkin?useUnicode=true&characterEncoding=utf-8&useSSL=false&allowMultiQueries=true
username: root
password: 123456
druid:
initialSize: 10
minIdle: 10
maxActive: 30
maxWait: 50000
# 指定zipkin持久化介质为mysql
zipkin:
storage:
type: mysql
2.1.3 主启动类
在主启动类上面添加@EnableZipkinServer 注解,表示开启zipkin server ,另外实例化了事务管理器。
@SpringBootApplication
@EnableZipkinServer // 开启 ZipkinServer
public class SpringCloudZipkinServerApplication {
public static void main(String[] args) {
SpringApplication.run(SpringCloudZipkinServerApplication.class,args);
}
// 事务管理器
@Bean
public PlatformTransactionManager txManager(DataSource dataSource) {
return new DataSourceTransactionManager(dataSource);
}
}
2.1.4 mysql准备工作
我们需要在mysql中创建zipkin 数据库,然后执行zipkin的一些建表语句
CREATE TABLE IF NOT EXISTS zipkin_spans (
`trace_id_high` BIGINT NOT NULL DEFAULT 0 COMMENT 'If non zero, this
means the trace uses 128 bit traceIds instead of 64 bit',
`trace_id` BIGINT NOT NULL,
`id` BIGINT NOT NULL,
`name` VARCHAR(255) NOT NULL,
`remote_service_name` VARCHAR(255),
`parent_id` BIGINT,
`debug` BIT(1),
`start_ts` BIGINT COMMENT 'Span.timestamp(): epoch micros used for
endTs query and to implement TTL',
`duration` BIGINT COMMENT 'Span.duration(): micros used for
minDuration and maxDuration query',
PRIMARY KEY (`trace_id_high`, `trace_id`, `id`)
) ENGINE=InnoDB ROW_FORMAT=COMPRESSED CHARACTER SET=utf8 COLLATE
utf8_general_ci;
ALTER TABLE zipkin_spans ADD INDEX(`trace_id_high`, `trace_id`)
COMMENT 'for getTracesByIds';
ALTER TABLE zipkin_spans ADD INDEX(`name`) COMMENT 'for getTraces and
getSpanNames';
ALTER TABLE zipkin_spans ADD INDEX(`remote_service_name`) COMMENT 'for
getTraces and getRemoteServiceNames';
ALTER TABLE zipkin_spans ADD INDEX(`start_ts`) COMMENT 'for getTraces
ordering and range';
CREATE TABLE IF NOT EXISTS zipkin_annotations (
`trace_id_high` BIGINT NOT NULL DEFAULT 0 COMMENT 'If non zero, this
means the trace uses 128 bit traceIds instead of 64 bit',
`trace_id` BIGINT NOT NULL COMMENT 'coincides with
zipkin_spans.trace_id',
`span_id` BIGINT NOT NULL COMMENT 'coincides with zipkin_spans.id',
`a_key` VARCHAR(255) NOT NULL COMMENT 'BinaryAnnotation.key or
Annotation.value if type == -1',
`a_value` BLOB COMMENT 'BinaryAnnotation.value(), which must be
smaller than 64KB',
`a_type` INT NOT NULL COMMENT 'BinaryAnnotation.type() or -1 if
Annotation',
`a_timestamp` BIGINT COMMENT 'Used to implement TTL;
Annotation.timestamp or zipkin_spans.timestamp',
`endpoint_ipv4` INT COMMENT 'Null when Binary/Annotation.endpoint is
null',
`endpoint_ipv6` BINARY(16) COMMENT 'Null when
Binary/Annotation.endpoint is null, or no IPv6 address',
`endpoint_port` SMALLINT COMMENT 'Null when
Binary/Annotation.endpoint is null',
`endpoint_service_name` VARCHAR(255) COMMENT 'Null when
Binary/Annotation.endpoint is null'
) ENGINE=InnoDB ROW_FORMAT=COMPRESSED CHARACTER SET=utf8 COLLATE
utf8_general_ci;
ALTER TABLE zipkin_annotations ADD UNIQUE KEY(`trace_id_high`,
`trace_id`, `span_id`, `a_key`, `a_timestamp`) COMMENT 'Ignore insert
on duplicate';
ALTER TABLE zipkin_annotations ADD INDEX(`trace_id_high`, `trace_id`,
`span_id`) COMMENT 'for joining with zipkin_spans';
ALTER TABLE zipkin_annotations ADD INDEX(`trace_id_high`, `trace_id`)
COMMENT 'for getTraces/ByIds';
ALTER TABLE zipkin_annotations ADD INDEX(`endpoint_service_name`)
COMMENT 'for getTraces and getServiceNames';
ALTER TABLE zipkin_annotations ADD INDEX(`a_type`) COMMENT 'for
getTraces and autocomplete values';
ALTER TABLE zipkin_annotations ADD INDEX(`a_key`) COMMENT 'for
getTraces and autocomplete values';
ALTER TABLE zipkin_annotations ADD INDEX(`trace_id`, `span_id`,
`a_key`) COMMENT 'for dependencies job';
CREATE TABLE IF NOT EXISTS zipkin_dependencies (
`day` DATE NOT NULL,
`parent` VARCHAR(255) NOT NULL,
`child` VARCHAR(255) NOT NULL,
`call_count` BIGINT,
`error_count` BIGINT,
PRIMARY KEY (`day`, `parent`, `child`)
) ENGINE=InnoDB ROW_FORMAT=COMPRESSED CHARACTER SET=utf8 COLLATE
utf8_general_ci;

2.1.5 启动服务测试
启动spring-cloud-zipkin-server 服务,然后在浏览器:http://127.0.0.1:9100
就可以看到zipkin的查询界面了。
2.2 其他服务改造
这里我们将对网关(spring-cloud-gateway-server:8020),订单服务(服务提供者:spring-cloud-order-service-provider端口7070与7071),用户服务(服务调用者:spring-cloud-user-service-consumer端口 8080与8081)进行改造
以下操作对这三个服务均生效
2.2.1 增加依赖
需要添加 对链路追踪 sleuth 与zipkin的依赖
<!--链路追踪-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>
<!--zipkin依赖-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
2.2.1 增加配置
在appliction.yml添加zipkin 与sleuth的配置
spring:
# zip配置
zipkin:
#zipkin server的请求地址
base-url: http://127.0.0.1:9100
sender:
# web 客户端将踪迹日志数据通过网络请求的方式传送到服务端,另外还有配置 # kafka/rabbit 客户端将踪迹日志数据传递到mq进行中转
type: web
sleuth:
sampler:
# 采样率 1 代表100%全部采集 ,默认0.1 代表10% 的请求踪迹数据会被采集
probability: 1
另外还需要对日志进行配置
logging:
level:
#添加分布式链路追踪日志级别
org.springframework.web.servlet.DispatcherServlet: debug
org.springframework.cloud.sleuth: debug
2.2.3 网关服务特殊修改
如果环境是《SpringCloud之Gateway使用篇》中的环境需要我们将网关项目中的黑名单过滤器 BlackListFilter 注释掉。
2.3 启动测试
2.3.1 启动服务
我们需要按顺序启动Eureka server 9090与9091 两个实例, 订单服务 spring-cloud-order-service-provider 7070与7071两个实例,用户服务 spring-cloud-user-service-consumer 8080与8081两个实例,网关spring-cloud-gateway-server 8020 一个实例, spring-cloud-zipkin-server 实例
2.3.2 测试
postman 或者浏览器请求:http://127.0.0.1:8020/user/data/getTodayStatistic/100
这个请求首先 到网关,然后根据路由规则到 用户服务,用户服务又调用订单服务,但是订单服务里面7070实例是超时的,会被熔断,我们多请求几次。
接着我们看下这个zipkin server ui界面,就可以看到我们的服务了,我们可以选择服务,span,等一些信息来查看请求链路信息,我们选择网关来看下。
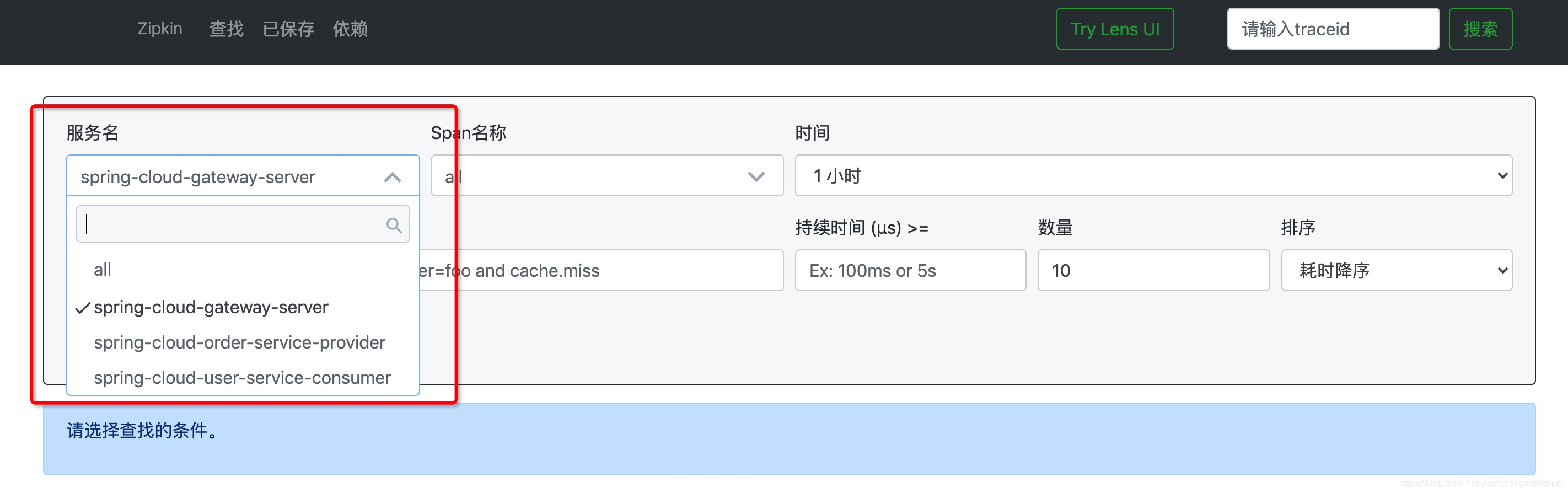
我们可以看到有很多链路信息,红的是链路中有失败的,然后绿的是没问题的。

我们可以选择一个链路点进去看下,可以看到整个链路实现,涉及的服务,深度,span,可以看到在那个span是失败的。
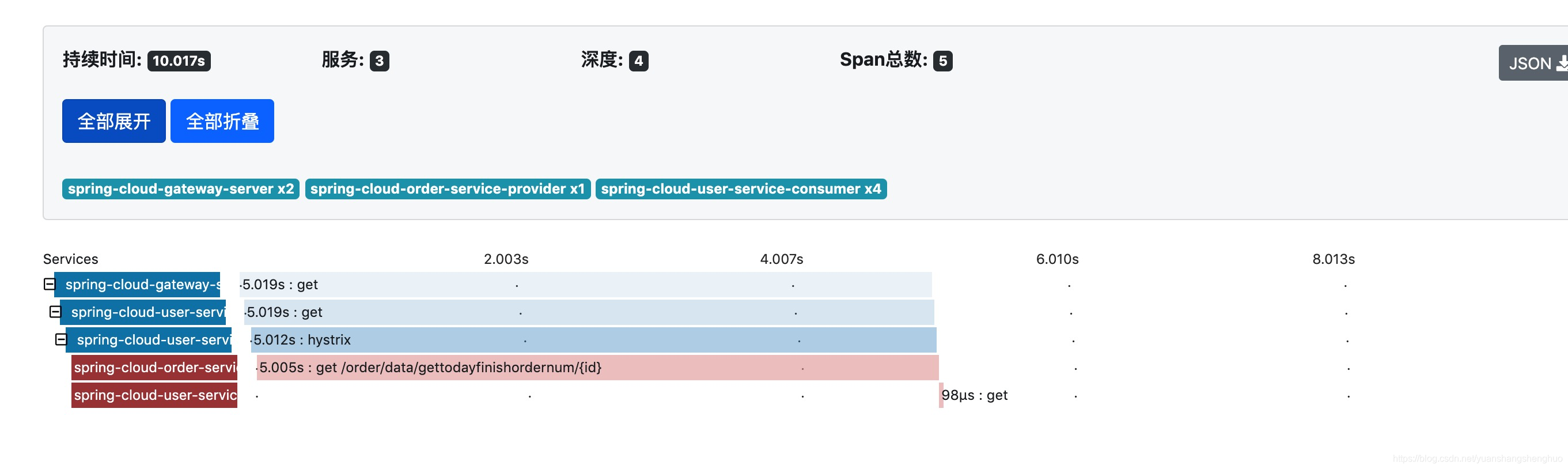
点下这个失败的span,我们可以看到更为详细的信息,而且能看到失败的原因。
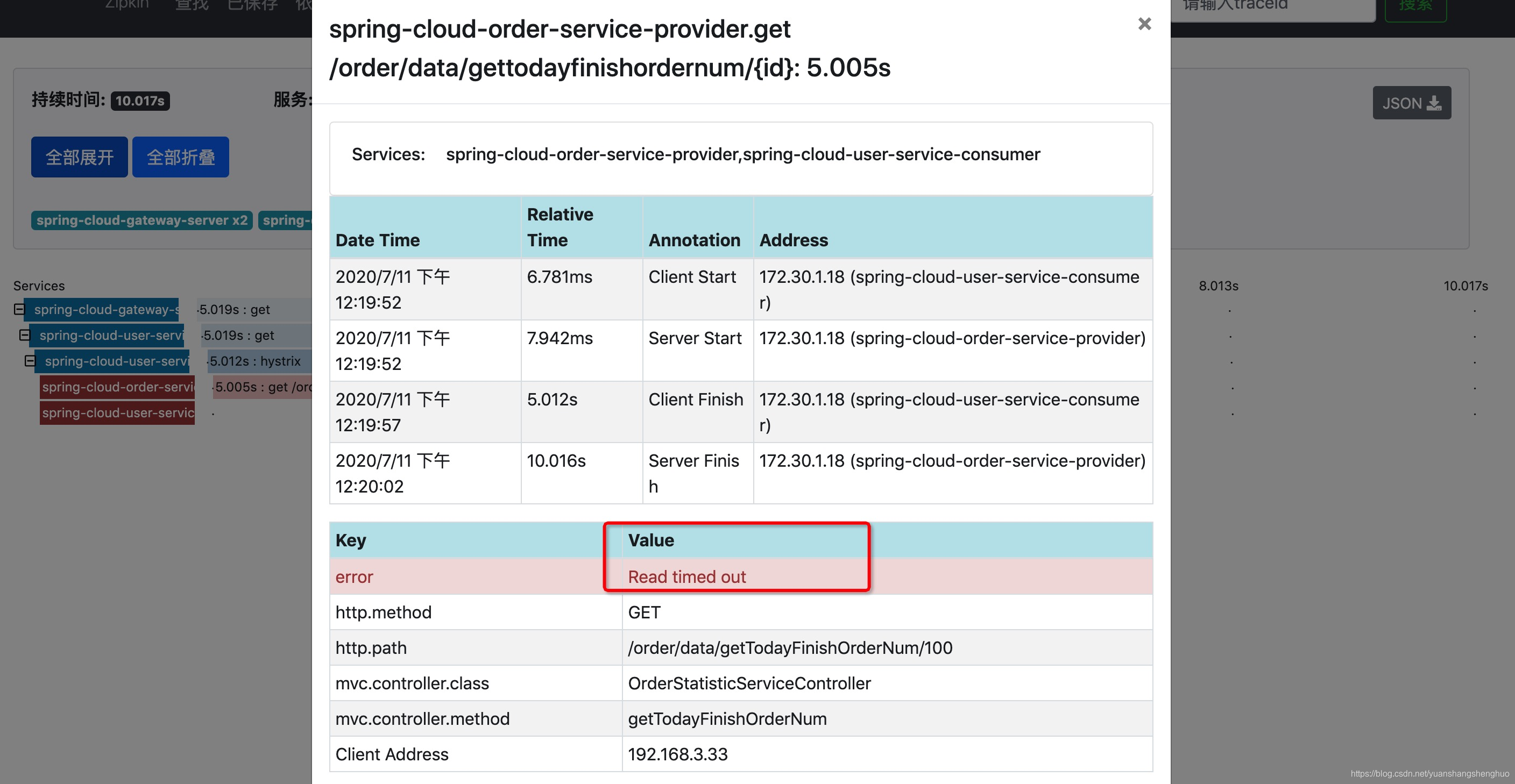
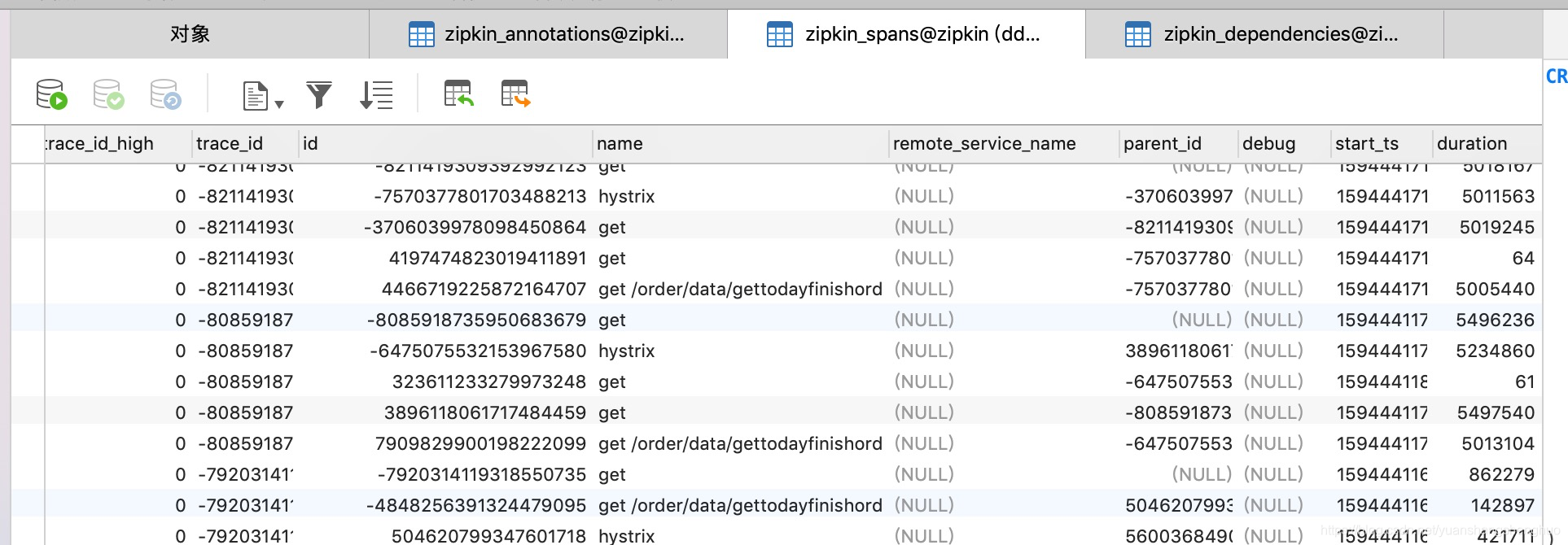
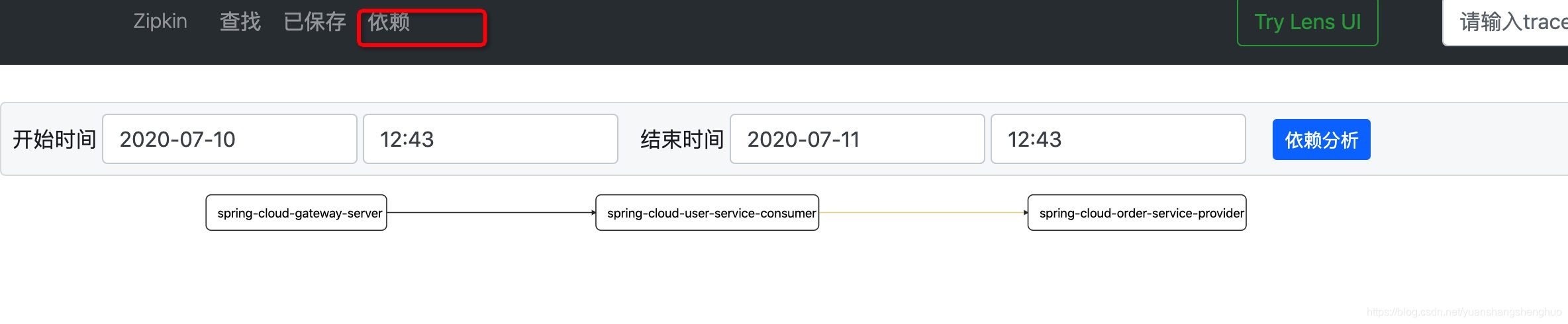
我们不止能看到每次的链路情况,而且还可以查看各个服务之间的依赖关系。
另外我们可以看下数据,在zipkin_spans 这个表中保存了链路信息。