在大学时代接触Synchronized后,做的实验就一直用它处理线程安全问题。但是我们都知道它都是块状的粒度,粗大粗大的毛孔,喷着厚重的气息,方法执行到同步块,性能抖三抖,加在方法上,就锁住了整个实例对象,静态方法上,还锁住了整个类,所有这个类的实例对象都不能避免。monitorenter和monitorexit监视器实现的同步,虎视眈眈地看着每一个蹑手蹑脚进来的线程。步步紧跟,直到执行完同步块释放锁。
Lock()是一个接口,是Java中的更加轻量级,更加灵活的,甚至可以自定义的锁,通过实现这个接口,重写它里面的 lock() ,lockInterruptibly() , tryLock() , tryLock(long time, TimeUnit unit) , unlock() , newCondition() 这几个方法,可以实现自定义锁。
源码注释解析:
* {@code Lock} implementations provide more extensive locking
* operations than can be obtained using {@code synchronized} methods
* and statements. They allow more flexible structuring, may have
* quite different properties, and may support multiple associated
* {@link Condition} objects.
* A lock is a tool for controlling access to a shared resource by
* multiple threads. Commonly, a lock provides exclusive access to a
* shared resource: only one thread at a time can acquire the lock and
* all access to the shared resource requires that the lock be
* acquired first. However, some locks may allow concurrent access to
* a shared resource, such as the read lock of a {@link ReadWriteLock}.
* The use of {@code synchronized} methods or statements provides
* access to the implicit monitor lock associated with every object, but
* forces all lock acquisition and release to occur in a block-structured way:
* when multiple locks are acquired they must be released in the opposite
* order, and all locks must be released in the same lexical scope in which
* they were acquired.
* While the scoping mechanism for {@code synchronized} methods
* and statements makes it much easier to program with monitor locks,
* and helps avoid many common programming errors involving locks,
* there are occasions where you need to work with locks in a more
* flexible way. For example, some algorithms for traversing
* concurrently accessed data structures require the use of
* "hand-over-hand" or "chain locking": you
* acquire the lock of node A, then node B, then release A and acquire
* C, then release B and acquire D and so on. Implementations of the
* {@code Lock} interface enable the use of such techniques by
* allowing a lock to be acquired and released in different scopes,
* and allowing multiple locks to be acquired and released in any
* order.
* With this increased flexibility comes additional
* responsibility. The absence of block-structured locking removes the
* automatic release of locks that occurs with {@code synchronized}
* methods and statements. In most cases, the following idiom
* should be used:
* When locking and unlocking occur in different scopes, care must be
* taken to ensure that all code that is executed while the lock is
* held is protected by try-finally or try-catch to ensure that the
* lock is released when necessary.
*
* <p>{@code Lock} implementations provide additional functionality
* over the use of {@code synchronized} methods and statements by
* providing a non-blocking attempt to acquire a lock ({@link
* #tryLock()}), an attempt to acquire the lock that can be
* interrupted ({@link #lockInterruptibly}, and an attempt to acquire
* the lock that can timeout ({@link #tryLock(long, TimeUnit)}).
Lock接口提供了更具扩展性的锁,允许更加灵活的结构,更多种类的属性,且不使用synchronized关键字声明和相关的方法。
Lock接口是一种对多线程共享资源访问的控制工具。一次只能有一个线程获取锁,其余线程访问共享资源都会要求先获得锁,但是也会有一些锁允许并发访问资源的操作,比如读锁。
Synchronized方法或者声明语句提供了针对每个对象的隐式监视器,但是获取锁和释放锁操作都是以块状粒度。当获取锁的时候都要求必须先执行与获取锁相反的释放指令。而且全部的锁都必须在执行完他们锁的语义范围之后释放。
Synchronized方法的作用域机制,并且通过声明语句使得实现监视器锁编程更加简单。
同时有利于避免许多关于锁的常见编程错误。
但是有些时候你会需要在一个更加灵活的方式下使用锁,例如一些遍历算法,并发访问的数据结构。比如:先获取节点A的锁,再获取节点B的锁,然后释放A获取C,释放B获取D,以此类推。
那么这种灵活的锁就可以通过Lock()来实现,在不同的逻辑范围内通过不同的指令条件来获取和释放锁,
随着出现越来越多的这种对灵活性要求的场景,无用的块状结构锁将被淘汰删除。自动释放和加锁都应该采用方法声明,在更多情况下,Lock()应该使用:
Lock() l = (你自定义的实现了Lock接口的锁) …;
l.lock() ; 加锁
try(){
} finally {
l.unlock(); 释放锁
}
当锁定和解锁在不同的范围发生时,必须确保用try catch捕抓锁定的代码块执行时候出现的异常,确保必要时释放锁不至于造成死锁。
Lock() 提供了新的方法 tryLock() 是尝试获取锁,以及tryLock(long,TimeUnit)来设置锁的固定超时时间。
Lock() 接口的实现类提供的行为和语义都与隐式监视器锁有很大的不同,例如可以保证排序,不可重入或者死锁检测。
注意Lock()实例只是普通对象,实例的锁监视器锁与Lock实例没有特别的关系,除了在它们自己的实现中,建议不要在它们自己的实例中使用Lock这样的实例来避免混淆。
除非另有说明,否则传递的任何参数都要抛出空指针异常(这也就是必须用try catch 捕获的原因之一)。
大概的介绍噼里啪啦就是这么一个意思,对比了一下Lock接口和Synchronized声明式锁的区别。
关于它的这六个方法,注解也介绍的非常详细了,这里只看最常用的加锁和释放锁方法。
void lock();
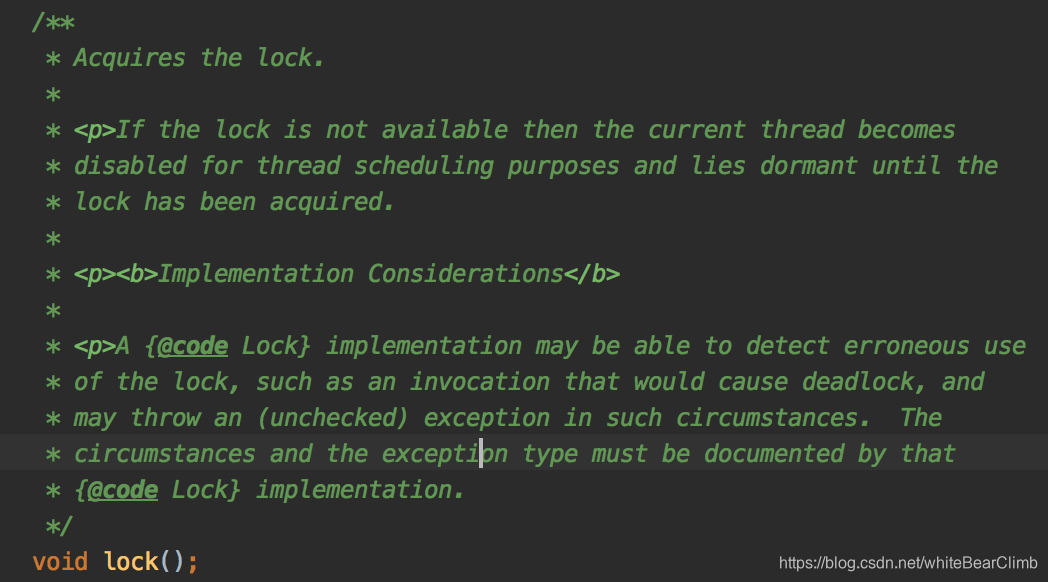
如果对于当前线程来说暂时未能获取到锁,则会进入休眠状态直到获取锁。使用lock的实现可能会检测到错误的使用导致死锁,所以这种情况下要声明异常类型进行捕获并且释放锁。
void unlock();
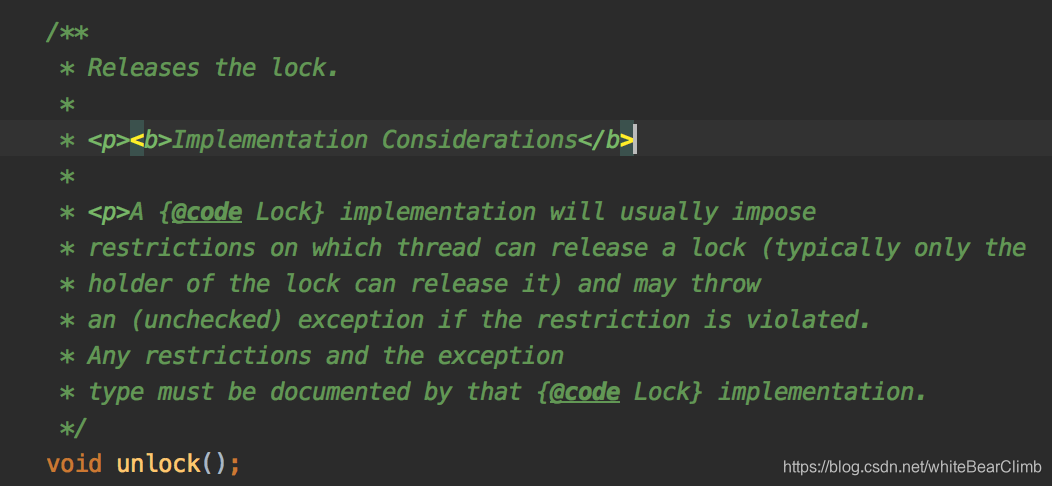
释放锁,通常只有获取锁的线程在顺利执行完之后释放,也可能抛出异常后释放,或者超出了时间限制时候释放等等,并且异常类型必须有Lock的实现类来记录处理。
反正它就是反复强调防止死锁记住一定一定要释放,要加异常捕获机制,要加超时释放等等。
Lock()中有公平锁和非公平锁概念,公平锁就是顺序加锁,根据线程的排队先后顺序获取,非公平锁就是大家疯抢,谁抢到就是谁的。
Lock lock1 = new ReentrantLock();默认是非公平锁
Lock lock2 = new ReentrantLock(true);公平锁。
具体用法:
由于它是一个接口,那就用它一个实现类ReentrantLock()写个例子来观摩一下。
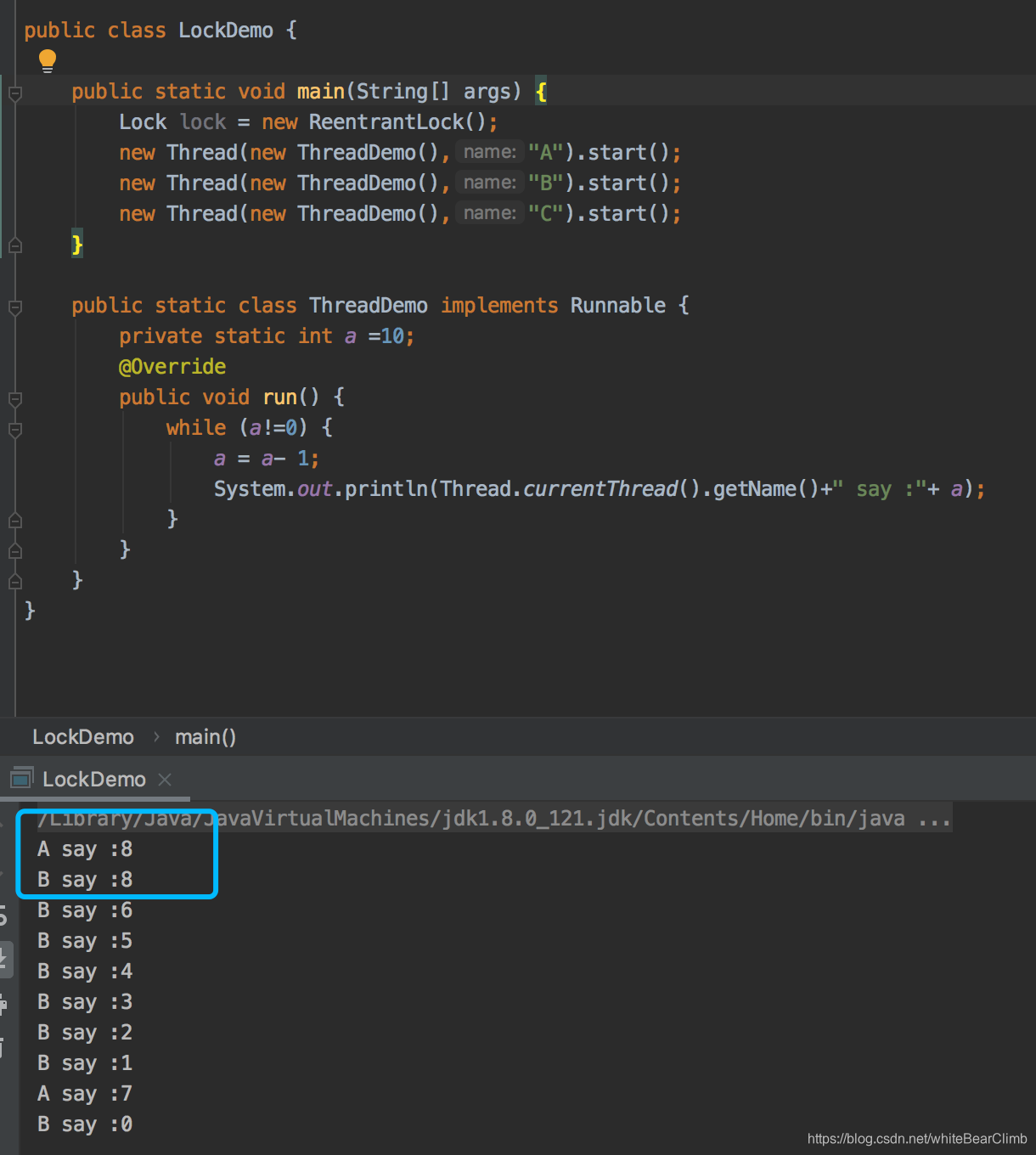
顺利出现线程不安全问题。
下面开始加Lock().
public class LockDemo {
private static Lock lock = new ReentrantLock();
public static void main(String[] args) {
new Thread(new ThreadDemo(),"A").start();
new Thread(new ThreadDemo(),"B").start();
new Thread(new ThreadDemo(),"C").start();
}
public static class ThreadDemo implements Runnable {
private static int a =500;
@Override
public void run() {
while(true){
lock.lock();
if(a>0){
System.out.println(Thread.currentThread().getName()+" say :"+ a--);
}
lock.unlock();
}
}
}
}
发现这样就正常了,操作前获取锁,操作后释放锁给别的线程。
并不是所有情况下都是Synchronized不好,也不是所有情况下Lock()都好,要根据场景。
Lock()只是Java代码实现的锁,比如需要灵活多变的,非块状锁的,条件判断可中断的,或者一些复杂多变的加锁过程,设置重试时间的锁,有序公平锁等等场景才用Lock()。由于它的轻量级和扩展性和高性能,适合大量同步的场景。
而Synchronized作为Java的老牌关键字,不需要我们加锁解锁和捕抓异常解锁防止死锁,使用上更加简单明了,不容易出现差错,而且自从JDK1.6之后,开发团队不断进行锁优化,大大提升了性能,所以各有各的优点。大量同步的场景还是尽量避免Synchronized,代码执行到这里强制变为单线程毕竟还是影响性能。
这么牛逼的Lock();既然能实现线程安全,又避免使用Synchronized,是怎么实现的?
继续看ReentrantLock的底层源码:
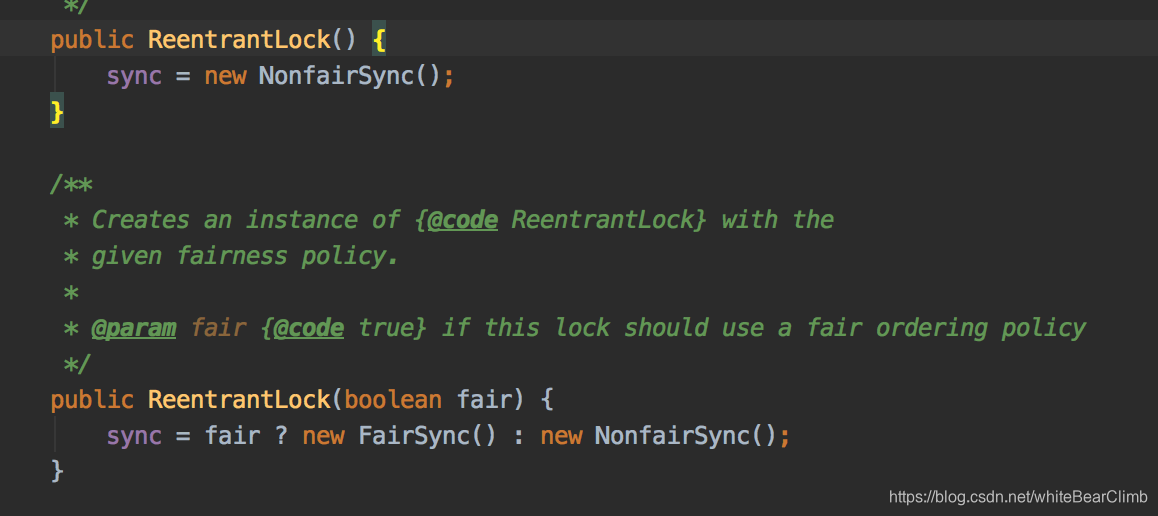
他有两个方法,假如传进来一个Boolean, true就是代表公平锁,默认是false不公平锁。我们继续进入FairSync 和 NonfairSync看看。
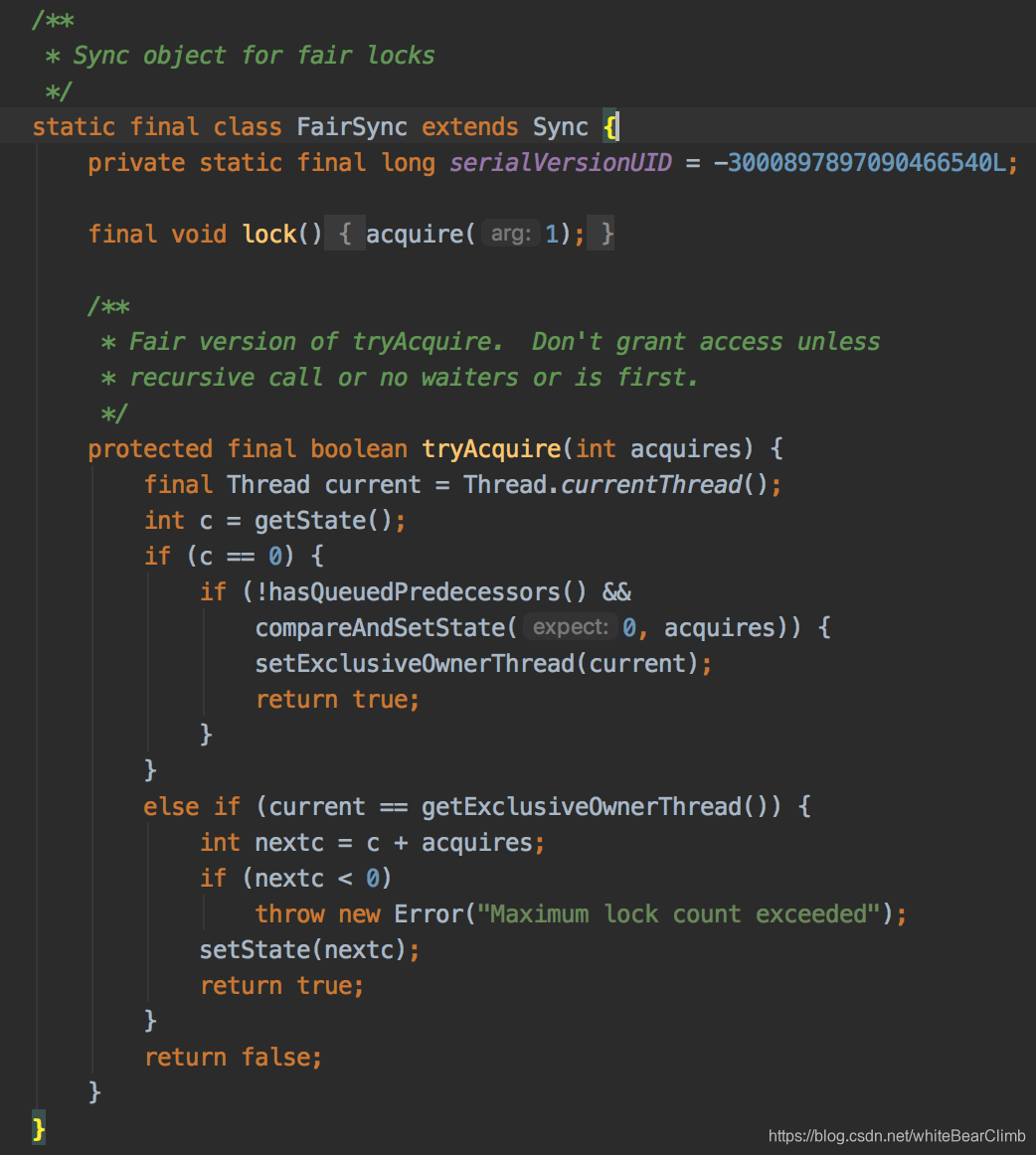
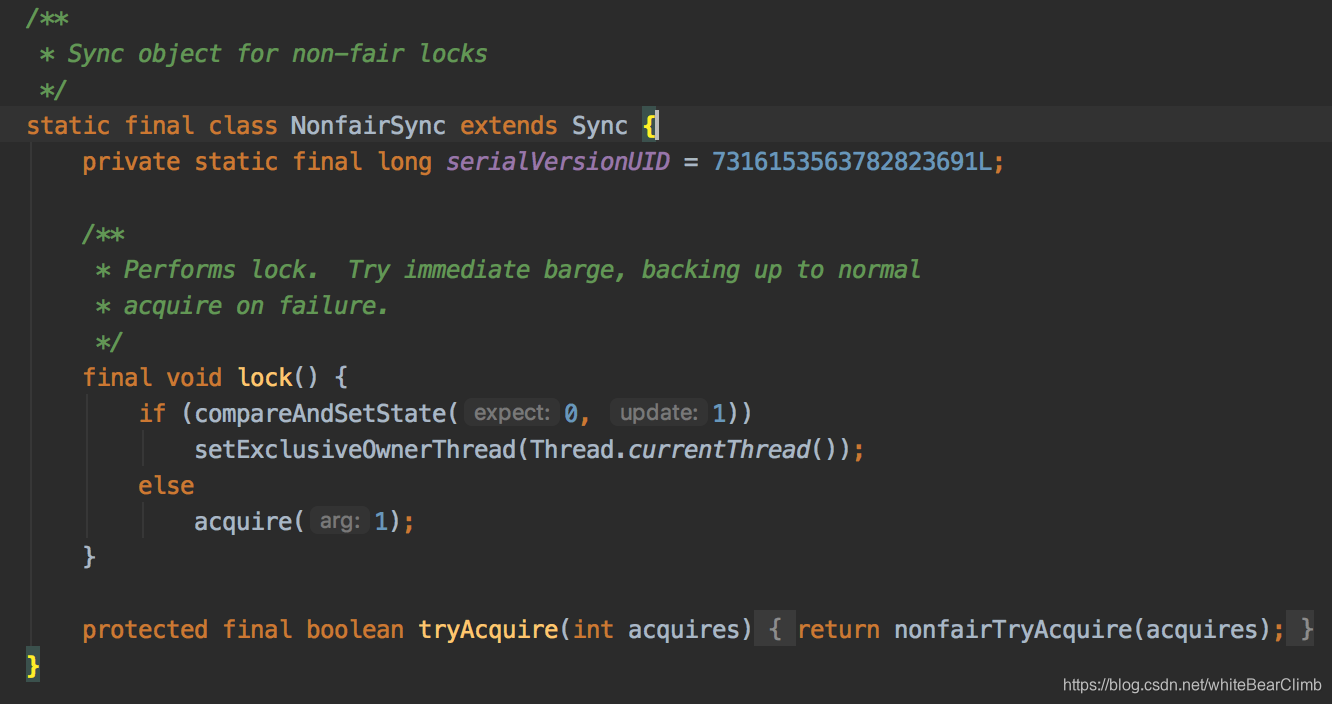
发现它们两个都是Sync的儿子。

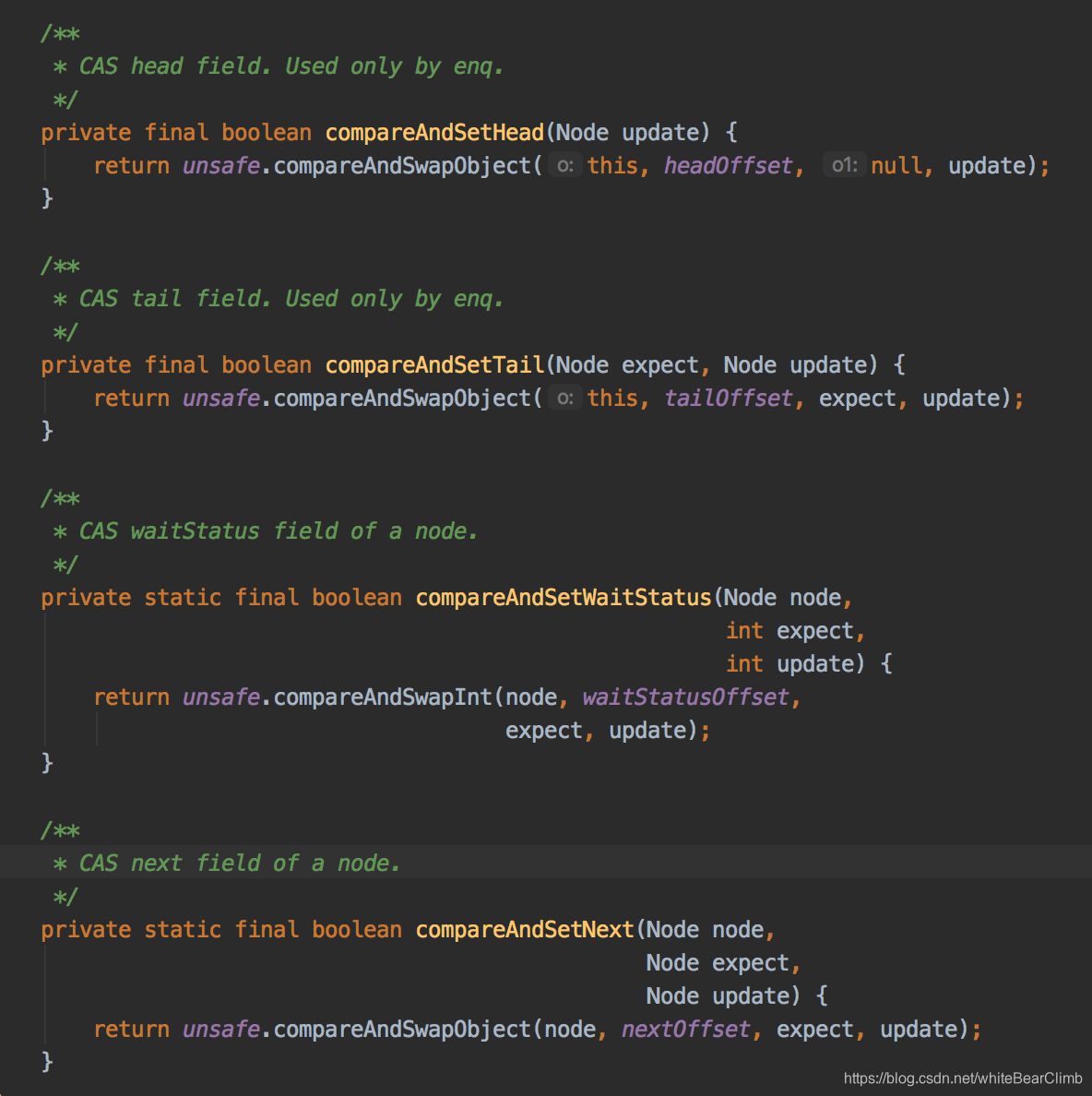
Sync又是一个叫做AbstractQueuedSynchronizer(简称AQS)的儿子。那玩意点进去一看:
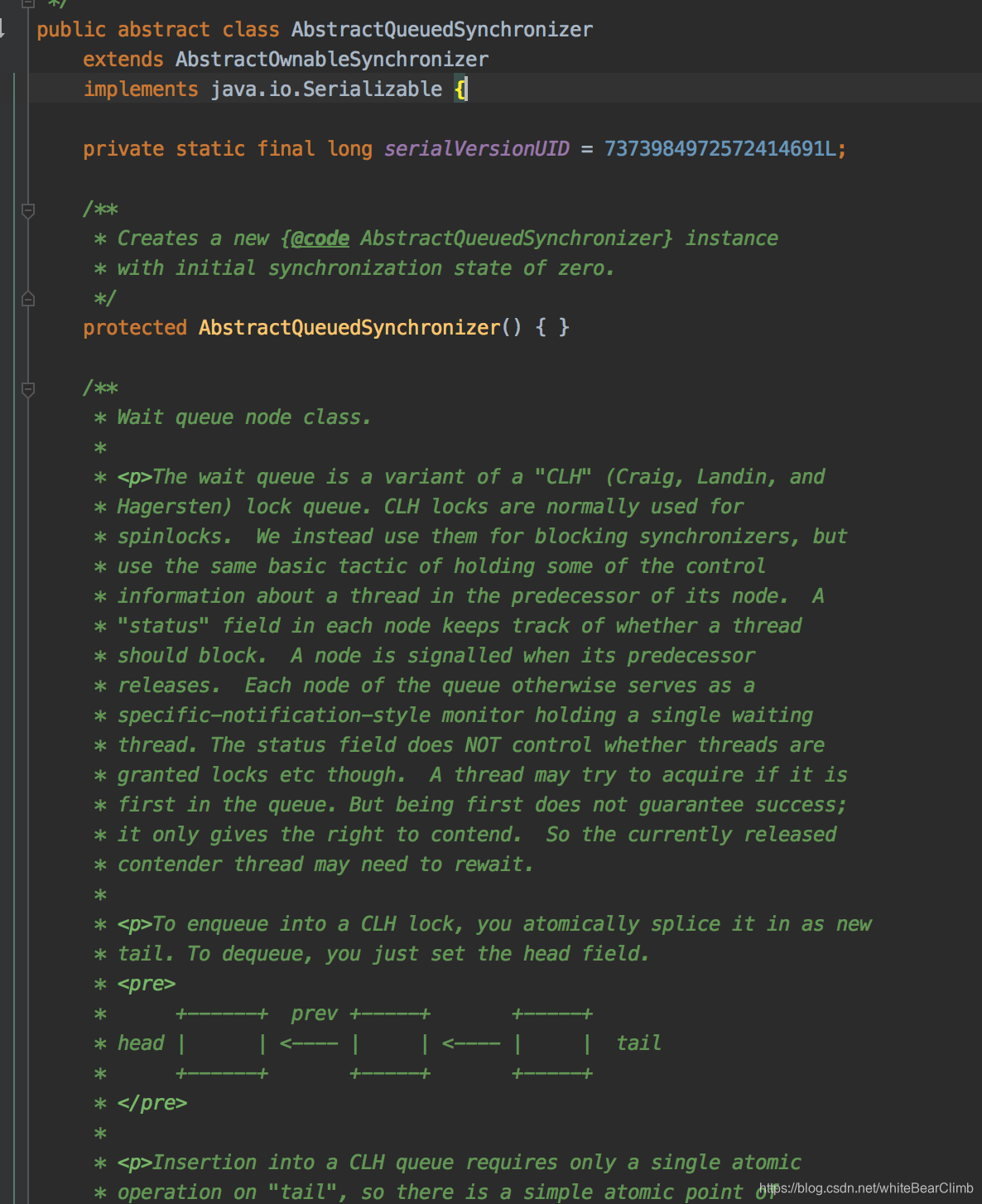
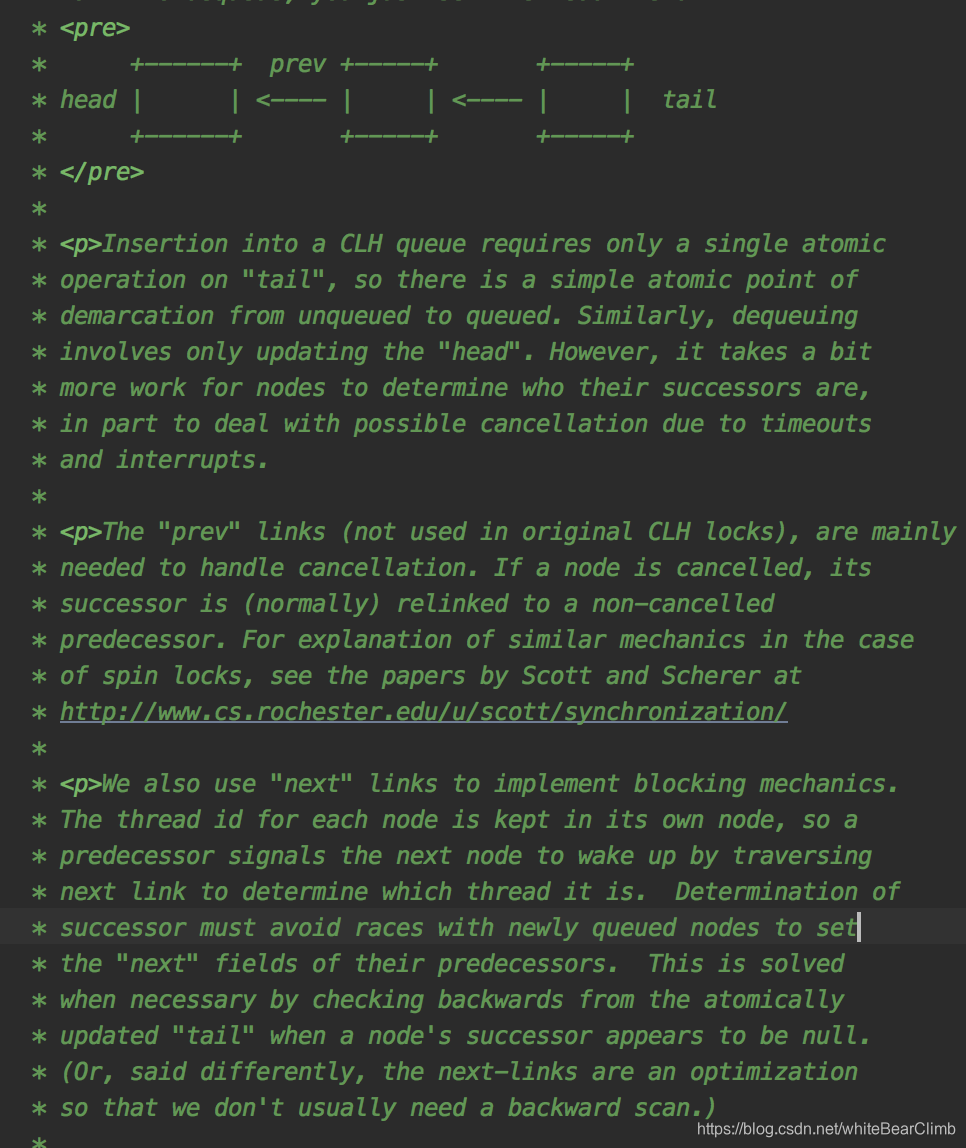
像不像链表结构??它底层还真的是Node节点结构!!AbstractQueuedSynchronizer顾名思义,其实就是抽象队列同步。通过类似的链表结构让多线程操作在这里排队,依次拿线程任务出去执行,当前面一个线程执行完毕之后,lock.unlock()之后,就激活后续节点任务执行。这个抽象队列,名字叫做CLH queue 。
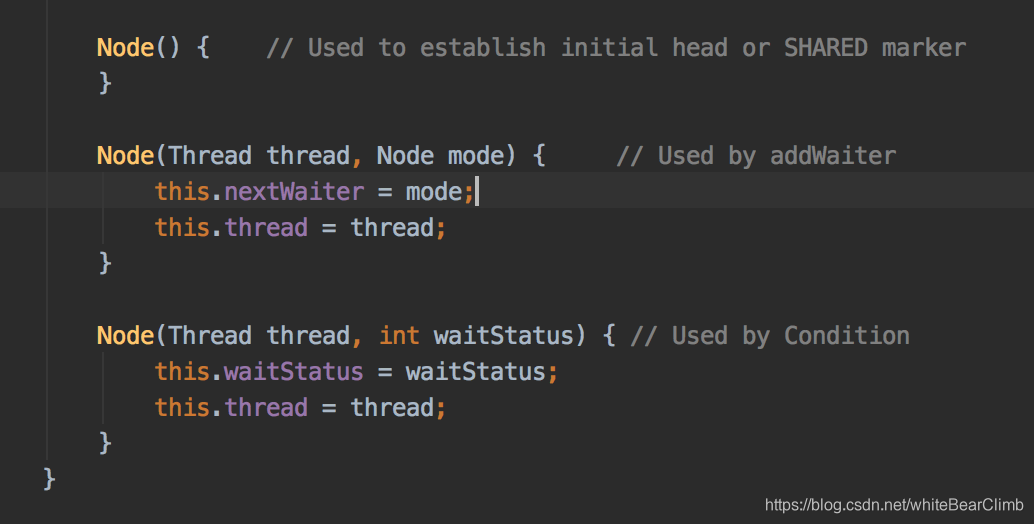
大略看一下,这个queue存的居然是Thread,还有nextWaiter下一个等待者线程。
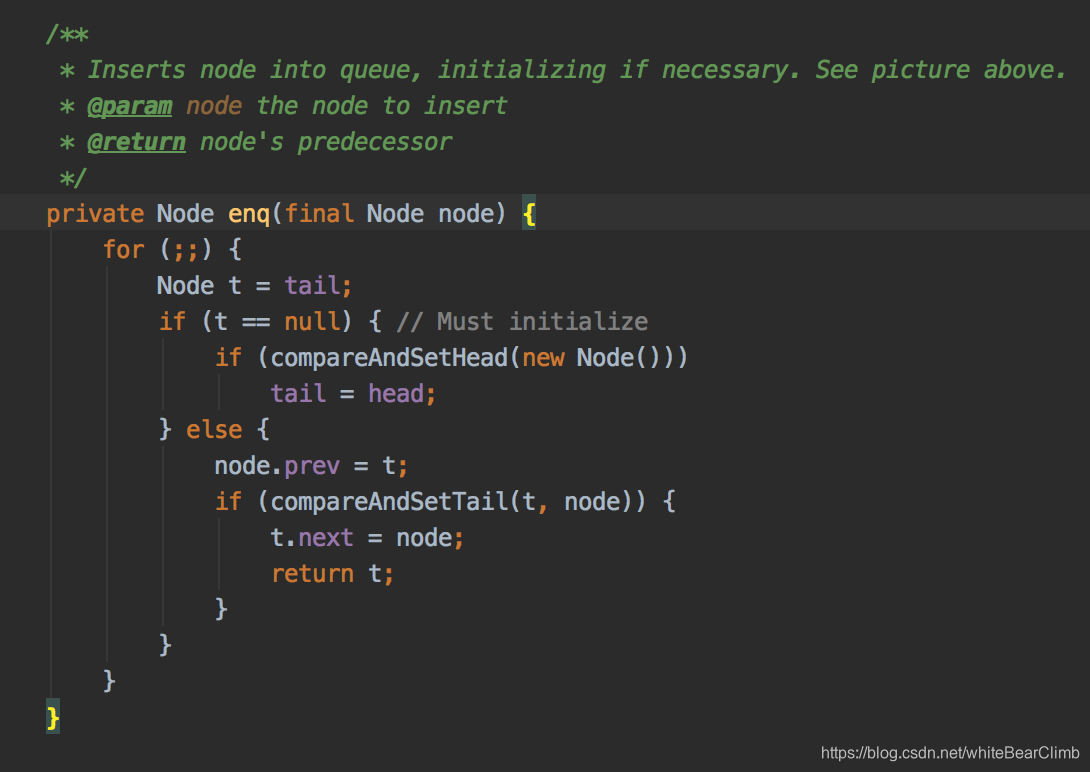
循环地将新增的线程追加到队尾,并返回Node。
还有一大堆的方法,有时间再仔细研究。
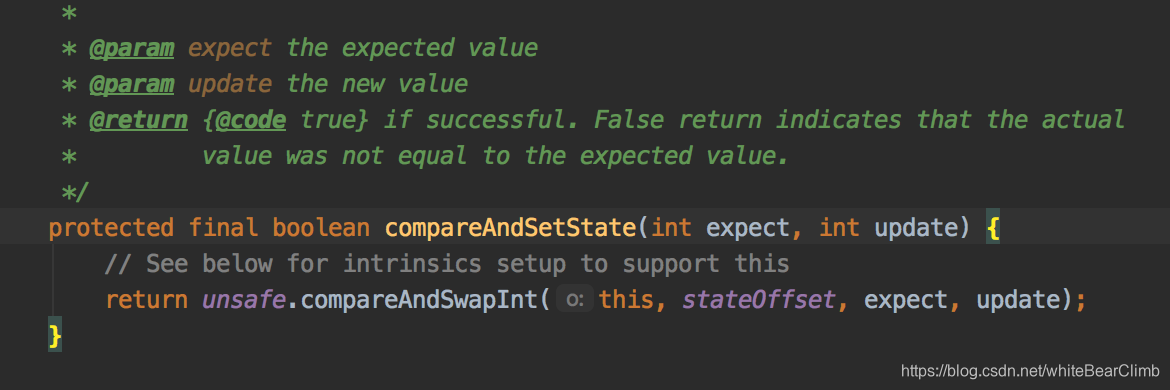
CAS:(Compare and Swap)
基于算法实现的一种乐观锁。是CPU指令级别的原子操作。