以及为什么鸟类的声音检测对我们环境的未来如此重要

介绍
你听说过自动语音识别,你听说过音乐标签和生成,但是你听说过鸟的声音检测吗?
大约在一年前,在我高二的时候,我第一次听到这种音频深度学习的用例。事实上,鸟音频检测是我做深度学习和计算机科学的第一个项目。我参与了一个研究项目,在北阿拉斯加的郊区用纯粹的声音来探测鸟类的存在。跳入其中,鸟的音频检测出现了这样一个利基(有利可图的形式),在本文中,我将向您展示如何在BirdVox-70k数据集上使用一个简单的卷积神经网络(CNN)来实现这一点。
为什么鸟类的声音检测很重要呢?
多年来,鸟类音频检测应用中深度学习模型的使用一直在不断发展进步,这也是一些人对此非常感兴趣的原因。首先,鸟类移动速度快,体型小,已经很难追踪。此外,不同种类的鸟都有自己独特的发声方式,这使得鸟类通过声音和听觉来检测比通过视觉来检测更加可取。最后,由于鸟类是生态系统的一部分,它们的存在和迁徙模式往往是任何特定地区环境健康的警示信号。
那么,为什么不录制一段音频,然后发送给人类稍后再听呢?
手动标记音频是昂贵的,乏味的,而且可能不接近实时。
所以,这就是深度学习和cnn发挥作用的地方。如果我们的模型足够精确,我们可以通过在野外设置麦克风来自动记录鸟类迁徙模式和追踪鸟类种类。有了这些数据,我们可以更深入地了解世界的生态系统,并充分了解气候变化对环境的影响。
那么,上面这张图是什么呢?
让我们先谈谈声音。声音基本上是由奇特的压力波组成的,这些压力波通过空气进入我们的耳膜,可以被数字设备作为信号记录下来。结果表明,我们可以将这个信号绘制如下图:
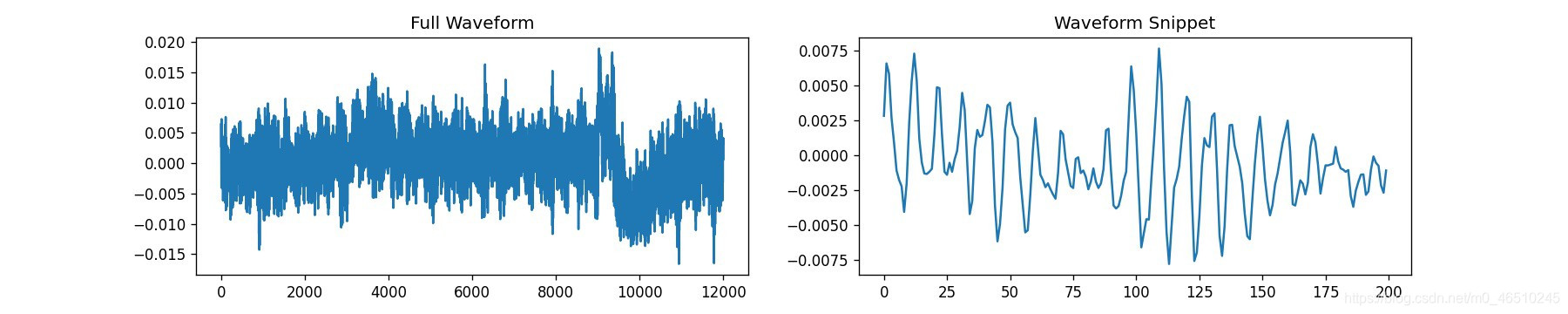
然而,这种长线图看起来并不是特别适合用于任何深度学习模型,更不用说CNN了。事实上,如果我现在告诉你,上面的音频信号代表了一只鸟的鸣叫,你会相信我吗?你反而会认为这是我随意创作的情节。如果你认为鸟鸣声是在第10000 波动点 左右,如果我说鸟鸣声是在正中间在第6000波动点?
那么,如果我们自己都不能做出任何强有力的假设,那么深度学习模型又如何能做到这一点呢?
我们并没有完全陷入困境。实际上还有另一种表示声音的方法:声谱图。频谱图是通过在一个小时间窗口中记录频率的存在和各自的强度,沿着x轴(用时间单位表示)堆叠,直到频谱图覆盖音频信号的总持续时间。在创建谱图的过程中,时间窗本身会发生重叠,通常频率强度(音量或响度)用颜色表示,或者用数字来表示高/低值。

从上面所示的完全相同的波形中锻造出的光谱图。x轴、y轴和标绘颜色分别表示时间单位、频率(赫兹)和频率强度。现在,你能清楚地分辨出鸟儿是否鸣叫以及何时鸣叫吗?
如果有一个来自上面的信号的光谱图,那么鸟儿是否鸣叫以及何时鸣叫就会清楚得多。具体来说,“只是因为”,你可以看到独特的活动大约6000赫兹在250毫秒的马克;那是鸟的叫声。因此,CNN音频分类器经常以光谱图作为输入,鸟叫声的音频检测模型也不例外。
准备
为此,我使用了BirdVox的BirdVox-70k数据集,该数据集包含半秒(500ms)的录音/波形,其中包含或不包含鸟叫声。数据集来自于它的大哥BirdVox-full-night,这两种鸟都是在2015年秋天在美国纽约州的Ithaca被记录的。每个波形的标签包含在它的每个文件名作为最后一个数字(0或1)。尽管70 k数据集拥有大约70000的视频数据(因此得名),我只会用三分之二的(更具体地说,50000左右)。
数据被捆绑在独立的HDF5文件中,这意味着我计划使用的已经减少的50,000个样本实际上被分割成4个不同的。HDF5文件。每个波形都被存储成一组,有它自己的“文件名”标签,所有这些都被存储到称为“波形”的另一组。
即使在阅读了h5py文档之后,我也没有看到像上面描述的那样的开发。这些发现已经让我做了两个最糟糕的数据准备的噩梦。因为存储空间的原因,我无法改变已经给我的数据的格式。这给我留下了最后一个选项:创建一个非常自定义的PyTorch数据集类DataSet,这样我就可以继续工作。
但在我继续之前,让我们听一些简短的音频样本,以及一些简单的数据分析数据集(警告-降低你的音量,因为样本可能比预期的更大):
在把所有的文件组合在一起之后,bird-positive音频样本的比例正好是50%,就像他们网站上承诺的那样。每个鸟正波形的文件名还包括鸟叫声的频率。把所有这些整理在一起,我发现如下:

很多电话的音调会很高。大部分的样本是这样的,但是绝大多数实际上更接近较低的频率(2000-3500赫兹)。很奇怪!
Dataset & Dataloader类
我们知道有一些独立的。hdf5文件要处理成一个“数据集”,而且每个文件都有一些奇怪的数据结构。这些条件肯定需要一个自定义PyTorch Dataset类来正确加载音频数据,以便以后进行训练。Dataset类主要需要剩下的__init__和__getitem__函数(还有剩下的__len__,但这很简单)。以下是我计划要做的事情:
__init__
遍历所有四个文件中的每个波形的每个组名,并将其所属的文件和HDF5组追加到属于该类的列表中。
获取波形的标签(文件/组名的最后一位)并将其附加到属于该类的另一个列表中。例如,文件名unit03_012712228_00000_0表示没有鸟叫声。
准备一个变换函数,应用到波形,将其转换为光谱图(具体地说,mel-scaled的光谱图),并考虑到其他增强技术。
__getitem__
为在初始化之时创建的列表提供索引
一旦通过列表接收到波形的位置,打开该波形的HDF5文件。所有的HDF5 I/O都将使用python库h5py来处理
把它变成PyTorch张量并应用任何变换,包括谱图变换。
将项目返回给调用者
下面,Dataset类的代码:
class BirdVox70kDS(Dataset):
def __init__(self, root_dir, fnames, transforms=None):
# store transforms func
self.transforms = transforms
# initialize storage arrays
self.wave_loc = []
self.labels = []
# for each hdf5 file...
for fname in fnames:
# open the file
fhdf5 = os.path.join(root_dir, fname)
with h5py.File(fhdf5, 'r') as f:
# navigate to `waveforms` group
waveforms = f['waveforms']
# for each piece of data...
for waveform in waveforms.keys():
# append waveform filename for later access
self.wave_loc.append([fhdf5, waveform])
# (label == last digit of filename)
self.labels.append(waveform[-1])
# turn them into np.arrays
self.wave_loc = np.array(self.wave_loc)
self.labels = np.array(self.labels)
# melspec transform (similar to `librosa.feature.melspectrogram()`)
self.melspec = T.MelSpectrogram(sample_rate=24000,
n_fft=2048,
hop_length=512)
def __len__(self):
# size of dataset
return len(self.labels)
def __getitem__(self, idx):
# fetch waveform from hdf5 file & label
fhdf5, waveform = self.wave_loc[idx]
with h5py.File(fhdf5, 'r') as f:
wave = f['waveforms'][waveform]
# convert to np array for faster i/o performance
# ^^ https://github.com/pytorch/pytorch/issues/28761
wave = np.array(wave)
# apply other specified transforms
if self.transforms:
wave = self.transforms()(wave)
# convert into tensor & apply melspec
wave = self.melspec(torch.Tensor(wave))
# unsqueeze adds dimension needed for pytorch's `Conv2d`
wave = wave.unsqueeze(0)
# parse label (still a string)
label = self.labels[idx]
return wave, int(label)
我们定义数据集文件的目录和文件名本身。我决定使用4个文件中的3个作为测试数据,最后一个作为验证/测试集来度量模型的性能,为后者留下最小的文件。由于每个文件的所有记录设备都设置的比较近(在伊萨卡的同一个城市),我认为绕过随机分割不会引入大量的偏差。
root_dir = '/notebooks/storage/'
fnames = ['BirdVox-70k_unit03.hdf5',
'BirdVox-70k_unit07.hdf5',
'BirdVox-70k_unit10.hdf5']
train_ds = BirdVox70kDS(root_dir, fnames)
val_ds = BirdVox70kDS(root_dir, ['BirdVox-70k_unit01.hdf5'])
在我们的数据集之后,下面就是使用dataloaders了:
batch_size = 128
train_dl = DataLoader(train_ds, batch_size, shuffle=True, pin_memory=True)
val_dl = DataLoader(val_ds, batch_size * 2, pin_memory=True)
# having `num_workers > 1` will crash dataloader when working w/ h5 files
# ^^https://github.com/h5py/h5py/blob/master/examples/multiprocessing_example.py#L17-L21
定义dataloaders,它将分批返回数据。在使用PyTorch和HDF5文件时,我尝试过设置多个“num_workers”,但发现存在一个bug
模型
我为我的模型设置了必要的辅助函数,以便以后进行训练:
class ModelBase(nn.Module):
# defines mechanism when training each batch in dl
def train_step(self, batch):
xb, labels = batch
outs = self(xb)
loss = F.cross_entropy(outs, labels)
return loss
# similar to `train_step`, but includes acc calculation & detach
def val_step(self, batch):
xb, labels = batch
outs = self(xb)
loss = F.cross_entropy(outs, labels)
acc = accuracy(outs, labels)
return {'loss': loss.detach(), 'acc': acc.detach()}
# average out losses & accuracies from validation epoch
def val_epoch_end(self, outputs):
batch_loss = [x['loss'] for x in outputs]
batch_acc = [x['acc'] for x in outputs]
avg_loss = torch.stack(batch_loss).mean()
avg_acc = torch.stack(batch_acc).mean()
return {'avg_loss': avg_loss, 'avg_acc': avg_acc}
# print all data once done
def epoch_end(self, epoch, avgs, test=False):
s = 'test' if test else 'val'
print(f'Epoch #{epoch + 1}, {s}_loss:{avgs["avg_loss"]}, {s}_acc:{avgs["avg_acc"]}')
定义多个函数,以后可以使用这些函数训练继承这个类的PyTorch模型。
def accuracy(outs, labels):
_, preds = torch.max(outs, dim=1)
return torch.tensor(torch.sum(preds == labels).item() / len(preds))
这个函数在上述类的val_step函数中被用来确定验证dataloader上模型的%准确性。
并定义用于拟合/训练模型和在验证数据集上测试模型的主要功能
@torch.no_grad()
def evaluate(model, val_dl):
# eval mode
model.eval()
outputs = [model.val_step(batch) for batch in val_dl]
return model.val_epoch_end(outputs)
def fit(epochs, lr, model, train_dl, val_dl, opt_func=torch.optim.Adam):
torch.cuda.empty_cache()
history = []
# define optimizer
optimizer = opt_func(model.parameters(), lr)
# for each epoch...
for epoch in range(epochs):
# training mode
model.train()
# (training) for each batch in train_dl...
for batch in tqdm(train_dl):
# pass thru model
loss = model.train_step(batch)
# perform gradient descent
loss.backward()
optimizer.step()
optimizer.zero_grad()
# validation
res = evaluate(model, val_dl)
# print everything useful
model.epoch_end(epoch, res, test=False)
# append to history
history.append(res)
return history
最后,这是我们等待已久的简单CNN模型:
class Classifier(ModelBase):
def __init__(self):
super().__init__() # 1 x 128 x 24
self.conv1 = nn.Conv2d(1, 4, kernel_size=3, padding=1) # 4 x 128 x 24
self.conv2 = nn.Conv2d(4, 8, kernel_size=3, padding=1) # 8 x 128 x 24
self.bm1 = nn.MaxPool2d(2) # 8 x 64 x 12
self.conv3 = nn.Conv2d(8, 8, kernel_size=3, padding=1) # 8 x 64 x 12
self.bm2 = nn.MaxPool2d(2) # 8 x 32 x 6
self.fc1 = nn.Linear(8*32*6, 64)
self.fc2 = nn.Linear(64, 2)
def forward(self, xb):
out = F.relu(self.conv1(xb))
out = F.relu(self.conv2(out))
out = self.bm1(out)
out = F.relu(self.conv3(out))
out = self.bm2(out)
out = torch.flatten(out, 1)
out = F.relu(self.fc1(out))
out = self.fc2(out)
return out
我使用了多个卷积层,正如我们之前的理论推断所建议的那样,我们的模型使用了一些最大池化层,然后使用一个非常简单的全连接网络来进行实际的分类。令人惊讶的是,这个架构后来表现得相当好,甚至超过了我自己的预期。
利用GPU
几乎每个人都需要GPU来训练比一般的前馈神经网络更复杂的东西。幸运的是,PyTorch让我们可以很容易地利用现有GPU的能力。首先,我们将我们的cuda设备定义为关键词设备,以便更容易访问:
device = 'cuda' if torch.cuda.is_available() else 'cpu'
我们还确保如果没有GPU, CPU会被使用。
这里还有另一个技巧:
torch.backends.cudnn.benchmark = True
这可以帮助提高你的训练速度(如果你的输入在大小/形状上没有变化)
显然,你可以“告诉”PyTorch在一次又一次的训练中优化自己,只要训练输入在大小和形状上保持不变。它会知道为你的特定硬件(GPU)使用最快的算法。!
然后我们定义帮助函数来移动dataloaders、tensors和我们的模型到我们的GPU设备。
def to_device(data, device):
"""Move tensor(s) to chosen device"""
if isinstance(data, (list, tuple)):
return [to_device(x, device) for x in data]
return data.to(device, non_blocking=True)
class DeviceDataLoader():
"""Wrap a dataloader to move data to a device"""
def __init__(self, dl, device):
self.dl = dl
self.device = device
def __iter__(self):
"""Yield a batch of data after moving it to device"""
for b in self.dl:
yield to_device(b, self.device)
def __len__(self):
"""Number of batches"""
return len(self.dl)
训练
使用我们的设备辅助功能,我们将一切移动到我们的GPU如下:
train_dl = DeviceDataLoader(train_dl, device)
val_dl = DeviceDataLoader(val_dl, device)
model = to_device(Classifier(), device)
我们还指定了我们的学习速度和我们的训练次数,我花了很长时间来找到一个好的值。
lr = 1e-5
epochs = 8
在进行任何训练之前,我们会发现模型的表现:
history = [evaluate(model, val_dl)]
[{'avg_loss': tensor(0.7133, device='cuda:0'), 'avg_acc': tensor(0.6042)}]
很显然,我们在开始时的准确性上有点幸运,但经过多次试验,最终结果即使不相同,也会非常相似。
接下来,我们使用之前定义的fit函数来训练我们的简单分类器模型实例:
history += fit(epochs, lr, model, train_dl, val_dl)
HBox(children=(FloatProgress(value=0.0, max=352.0), HTML(value='')))
Epoch #1, val_loss:0.6354132294654846, val_acc:0.7176136374473572
HBox(children=(FloatProgress(value=0.0, max=352.0), HTML(value='')))
Epoch #2, val_loss:0.6065077781677246, val_acc:0.7439352869987488
HBox(children=(FloatProgress(value=0.0, max=352.0), HTML(value='')))
Epoch #3, val_loss:0.56722491979599, val_acc:0.77376788854599
HBox(children=(FloatProgress(value=0.0, max=352.0), HTML(value='')))
Epoch #4, val_loss:0.5528884530067444, val_acc:0.7751822471618652
HBox(children=(FloatProgress(value=0.0, max=352.0), HTML(value='')))
Epoch #5, val_loss:0.5130119323730469, val_acc:0.8004600405693054
HBox(children=(FloatProgress(value=0.0, max=352.0), HTML(value='')))
Epoch #6, val_loss:0.4849482774734497, val_acc:0.8157732486724854
HBox(children=(FloatProgress(value=0.0, max=352.0), HTML(value='')))
Epoch #7, val_loss:0.4655478596687317, val_acc:0.8293880224227905
HBox(children=(FloatProgress(value=0.0, max=352.0), HTML(value='')))
Epoch #8, val_loss:0.4765000343322754, val_acc:0.8155447244644165
在发现精确度有一点下降后,我决定再训练一点点,让模型重定向回到正确的方向:
history += fit(3, 1e-6, model, train_dl, val_dl)
HBox(children=(FloatProgress(value=0.0, max=352.0), HTML(value='')))
Epoch #1, val_loss:0.4524107873439789, val_acc:0.8329823613166809
HBox(children=(FloatProgress(value=0.0, max=352.0), HTML(value='')))
Epoch #2, val_loss:0.44666698575019836, val_acc:0.8373703360557556
HBox(children=(FloatProgress(value=0.0, max=352.0), HTML(value='')))
Epoch #3, val_loss:0.4442901611328125, val_acc:0.8412765860557556
忽略“HBox”工件,这是tqdm提供的,请多关注准确性!
总结一下,以下是我们过去11个时期的训练统计数据:
plt.plot([x['avg_loss'] for x in history])
plt.title('Losses over epochs')
plt.xlabel('epochs')
plt.ylabel('loss')
plt.show()

plt.plot([x['avg_acc'] for x in history])
plt.title('Accuracy over epochs')
plt.xlabel('epochs')
plt.ylabel('acc')
plt.show()

总的来说,我们的模型训练得相当好,从它的外观来看,我们可能已经为我们的模型的损失找到了一个相对最小的值。
等等,一个更复杂的模型或者使用不同的转换怎么样?
相信我,在我的simple Classifier()第一次尝试成功之后不久,我也尝试过这两种方法。我决定不包括这两个细节,因为我发现他们的结果实际上比我们已经取得的结果更糟糕,这很奇怪。
对于额外的谱图转换,我尝试了随机时移和噪声注入。长话短说,它似乎根本没有提高验证的准确性。此后,我认为是这样,因为数据集规范明确表示,所有啾啾将位于中间的录音,因此随机变化的光谱图的目的允许更好的模型泛化实际上可能已经作为损害的表现。然而,我还没有尝试过随机噪声注入。
我还尝试训练一个ResNet50模型,希望进一步提高验证的准确性。这是最令人难以置信的部分:我的模型从来没有超过50%的准确率!直到今天我写这篇文章的时候,我还不确定我做错了什么,所以如果其他人能看看笔记本并帮助我,我很高兴收到任何建议!
结论
总而言之,这是一个真正有趣的努力,花一些时间进行研究。首先,我得重新审视我去年夏天调查过的东西,无可否认,这有一种怀旧的感觉。更重要的是,我们学习了如何实现一个很可能用于真实场景的PyTorch数据集类,在真实场景中,数据不一定像您预期的那样设置。最后,最终的验证分数为84%,对于我即兴创建的如此简单的网络架构来说,这是相当整洁的!
如果您想要本文中显示的所有代码示例的源代码,您可以访问https://jovian.ml/richardso21/bird-audidetection。包括了上面说到的方法尝试。
作者:Richard So
deephub翻译组