写在前面:本文是在记录博主在查阅资料理解Faster R-CNN时的理解相关笔记,如有错误请大家及时指出
资料参考b站、原论文
https://www.bilibili.com/video/BV1pt411F73V?p=2
以及其他网络资源
原论文地址
https://arxiv.org/pdf/1506.01497.pdf
综述
- faster rcnn是在rcnn和fast rcnn的基础上发展而来,网络用于目标检测
- faster rcnn与前两者不同的地方主要就是候选框的选取方式,前两者是提前人工提供候选位置,而faster rcnn则是利用另外的网络来生成候选框,这样既减少了误差还可以提高运行速度
RCNN和Fast RCNN
-
RCNN
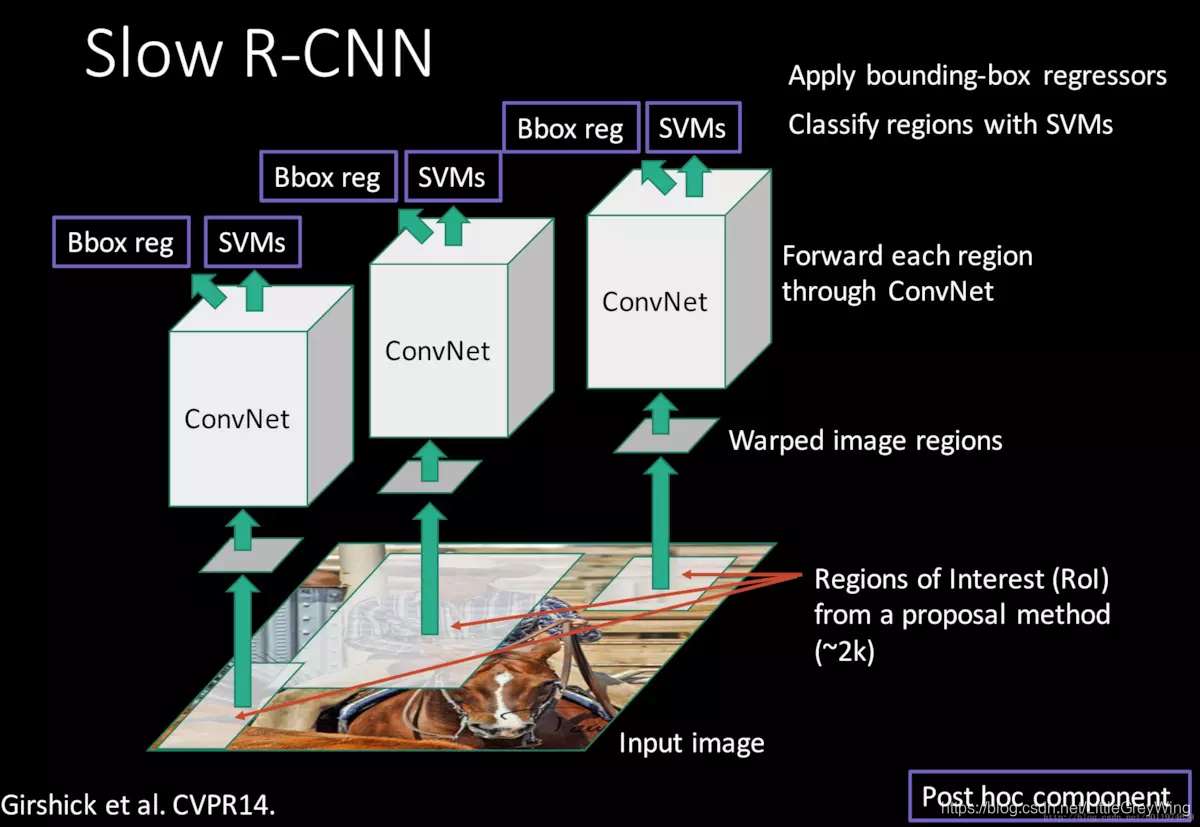
- 第一步输入原始图像,根据selective search算法获得许多候选框(约为2k),每一个候选框上的图片分别进行卷积,这样有了一堆卷积网络,所以比较慢。
- 第二步各候选框经过了卷积网络后分别对结果进行类别的预测(SVM)和Bbox reg(回归器)的回归中分别获得类别和正确的框框
-
SPPnet
- 经过前期的共同卷积层之后,得到的特征图是大小不一的,此时让这些特征图都经过一个"spatial pyramid pooling layer",特征图较大的输出也较大,特征图小的输出也小,但是我们把这些输出连成一串.比如经过这样一个pooling之后会有16256-d、4256-d,1256d,那我们把他们整成一个21256-d的,这样在最后进入全连接层的时候可以确定形状了,不过要记得调整权重的相乘的位置。
-
Fast R-CNN
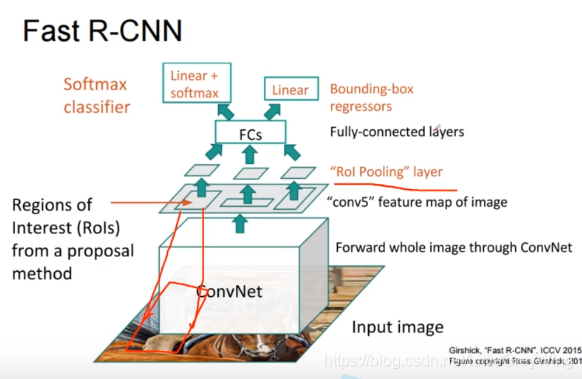
- 与R-CNN输入一致,但是只有一个卷积层,取消了一开始的selective search. 整体做完卷积之后,在特征映射图上选取RoIs(Region of Interests),原因在于在这上面选取的RoI通过感受野可以回归到原来的输入图像的一小块。所以其实在特征映射图上找到的区域其实也反映了原图的区域。而上层的SPPnet则被替换成了RoI Pooling,他可以看做是SPP net的特殊情况。,这样就可以再去统一进入全连接层了。通过全连接层后分两路,一边是分类器,一边是回归器。分别对应类别一边对应框框的位置。问题在于还需要提前选取RoIs,实验也证明其大部分时间用在了RoI的选取。(见下图)
Faster RCNN网络
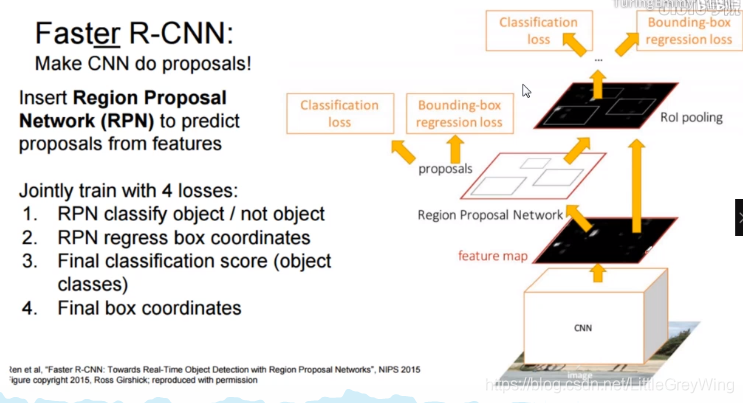
网络是将fast rcnn和RPN网络进行结合,其中RPN就是来实现寻找候选框的网络
- 总体思路
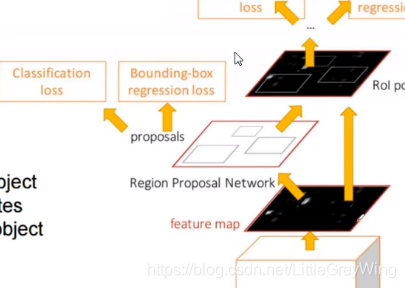
- 看图可知,他从传过来的特征图中经过RPN网络产生了很多很多候选框,然后对候选框执行
-
- 做分类,这是个二分类,看他是物体还是不是物体
-
- 如果是一个物体的框那么做一个微调,让这个框和距离他最近的一个ground-truth标签框做一个回归任务来调整他的位置。
- 现在还有个问题,我现在只知道他是物体还是不是物体,但是不知道他是什么物体呀,所以最后一层的分类任务则是一个多分类任务,同时呢再一次回归,再精确一下框的位置。
- 这样他已经成为一个end to end 的网络了,并且可以做任何物体的检测了。
论文部分
摘要
- RPN层是一个全卷积的层,没有全连接的层。
- 很容易训练
- 一秒5帧
- 利用GPU提取候选框,核心是RPN层
- RPN层做两件事,一个是分类任务,是否为物体,另一个是对是物体的部分进行框回归
- 为了既检测出小物体又检测出大物体,传统方法是图片金字塔增加了输入,另一个方法是采用不同的filter的size,不过也增加了输入,现在的方法是利用RPN网络
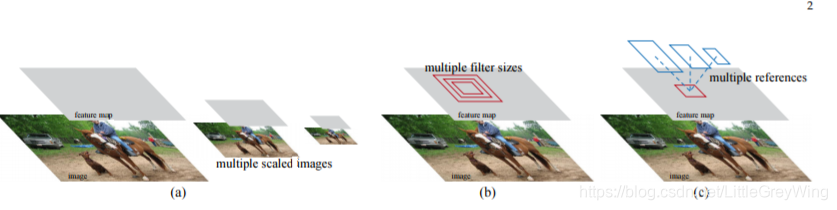
- 其中的VGG网络可以替换,比如残差网络,而且用到了许多商业的应用。
RPN网络(Region Proposal network)
一个RPN网络把一个任意大小的图片作为输入(全卷积),输出是一系列的框
- 他不是最终的结果,他输出的是框以及这个框是不是物体的一个得分,而不是属于哪个类的得分
- 为了产生候选框,需要一个滑动的网络。其实也可以就看做是另外一个卷积层,因为卷积操作就是在滑动一个filter

- 假设网络是VGG16,那么其中有4个pooling层,图片被缩小到原来的四分之一,那现在图像上的一个点岂不是涵盖了原来的16个像素点的内容?其实也就是说每个点映射到原图会有一个范围,那么我们怎么去找这个范围呢?可能这一个点映射到原图是一个正方形,现在我们不直接假定他是固定大小的正方形,而是把它变换,基于每个点生成一个框,再把框映射到原图出现不同的区域。在论文中,对每个点回溯映射了9个框,为3*3,第一个3是区域的长宽比有三类,第二个3是框的大小的种类。
- 现在得到了框,将这些框往下先再次进行卷积操作,可以理解为进一步提取特征(并且这样得到的结果中一个点又融合了上一层的9个点的信息),然后对这些anchors(这些框现在也叫做anchor)执行两类任务,一类是分类任务,另一类是回归任务。
- 在分类任务中,对每个框要判断是不是物体,因此有两个得分,前面提到产生了k个anchors,那么会有2k个分数;在回归任务中,每个框的位置由(x,y,w,h)确定,因此会出现4k个坐标,并得到他们回归值。
- 在两类任务中,分支之后分别会经过一个1*1的卷积层,这是在代替一个全连接层。
Anchors
- 为了考虑基础的物体大小,先产生了不同比例和不同初始大小的基础框,但并不是最终结果的比例。
- 假设原始图像是6001000的,那么特征图最后就是类似4060的,有2400个点,每一个点生成了9个anchors,每个anchor可以对应到原图另外的一个区域,于是这样就有了对应于原图的40609有两万多个框,这样的话对于一般的检测已经足够了。(但其实有些是多余的后续有过滤操作)
平移不变性
- 可以这样理解平移不变性:由于框足够多,各处都覆盖,那么假如有一个物体原来在A处现在到了B处,通过RPN网络之后计算仍然可以找到。
损失函数
-
对于分类任务来说,我们选了许许多多的框,同时这是有监督学习,提前也给定了许多的框(ground-truth),假如有这样一个图里边有两个标签。现在有两种方式可以去评定候选框的质量,第一种是把和ground-truth的IoU最大的框评定为正例,第二种则是把IoU值大于某个值比如0.7的框标定为正例。
-
IoU比较小的比如小于0.3当做负例,而0.3-0.7间的直接扔掉。
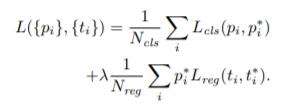
-
可以这样理解,pi是一个anchor,pi* 是一个ground-truth的框,第一项为分类的损失,第二项为位置的损失。并且当pi为正例时pi* =1,pi为负例时pi*=0,这样如果pi为负例,后面就没必要做位置的回归,前一项的损失也是在和0来做损失。
-
lamba的值则是调整权重,论文中取得为10
-
看一下回归的损失函数:

x为预测值,xa代表anchor的值,x是ground-truth的值。(以下为个人理解)通过tx获得anchor box和ground-truth box得到一个变换的指标,再通过这个变换的指标获得预测值。
训练RPN
- 网络通过SGD的下降法来训练
- 每次训练时只需要一张(mini batch=1)因为每张图产生的框足够多了
- 在图中随机选256个框(一开始我们提到有2万个框),我们这样做原因一是减少计算量,另外是过滤重复的东西并且能够能正确反映整体规律。一般选择128个正样本和128个负样本,但是负样本其实占绝大多数,所以如果正样本不够那就用负样本填充
- 权重初始化用高斯初始化,并且标准差为0.01
其他细节
- 一张图片传入的时候不是直接进入网络的,还是要进行调整的,会把短边resize成600左右
- anchor的比例会有128、256、512
- 有些框对应到原图上如果产生越界情况是不进行采用的,这样大概剩下6000个
- 测试的时候越界的框不会ignore而是裁剪一下
- 有很多框会重叠在一起,那么如果一堆重叠的框都在一起,这样重复了,没什么用还增加了计算量,对于重复的框进行非极大值抑制操作,假如现有一个A框有一个B框,IoU都大于0.7那么都是正例,假如A框得分0.75,B框得分0.9,那么抑制这个非极大值,即A框最后不要了,如果还有一个C框得分是0.95,那么A、B框都不要了,保留C框。这样的操作进一步筛选了有效的框。现在从6000变成2000左右个了。
- 对于剩下的框还可以取一个topn,只有前n个得分更高的分数的框会被留下来,其他的则不要了。
RPN与Fast R-CNN的融汇
- RPN网络得到了许多的框,接下来把框框到刚刚的feature map上,进行分类和回归任务即可