之前写过一篇关于Scrapy安装的博客
,这里用一个简单的案例来熟悉一下Scrapy的初阶使用。完整代码已经上传至GitHub
。
先看一下创建好的项目的目录结构:
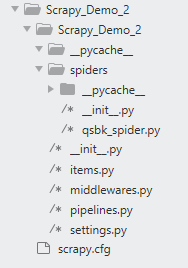
其中最外层的Scrapy_Demo_2目录是项目名;qsbk_spider.py是创建的爬虫名,在这里面写解析页面的代码;items.py里面定义要爬取的页面元素;pipelines.py里面写下载解析后的内容的代码;settings.py写的是爬虫的一些设置,比如请求头,爬取间隔等。其余的文件暂时还用不着,因为这只是一个初阶的案例。
案例开始:
① 在settings.py进行一些初始设置。其实这些内容在创建好项目的时候已经生成了,我们只要打开注释,稍作修改就行了。
# 不遵循robot规则
ROBOTSTXT_OBEY = False
# 下载间隔,反正爬取太快导致被拉黑
DOWNLOAD_DELAY = 1
# 请求头,加上一行User-Agent
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36',
}
# 下载优先级,数字越小,优先级越高。
ITEM_PIPELINES = {
'Scrapy_Demo.pipelines.ScrapyDemoPipeline': 300,
}
② 在items.py中定义要爬取的页面元素:
import scrapy
class ScrapyDemoItem(scrapy.Item):
# 要爬取的item,在这里定义,固定格式,遵循scrapy框架规范
author = scrapy.Field()
content = scrapy.Field()
③ 在qsbk_spider.py中写解析页面的内容:
import scrapy
from Scrapy_Demo.items import ScrapyDemoItem
class QsbkSpiderSpider(scrapy.Spider):
name = 'qsbk_spider'
allowed_domains = ['qiushibaike.com']
# 这是一个列表,可以添加多个,但是一般只写一个就够了
start_urls = ['https://www.qiushibaike.com/text/page/1/']
def parse(self, response):
# duanzidivs是一个SelectorList对象
duanzidivs = response.xpath("//div[@class='col1 old-style-col1']/div")
for duanzidiv in duanzidivs:
# get和getall方法是获得Selector对象中文本信息,返回的是str对象
duanzi_author = duanzidiv.xpath(".//h2/text()").get().strip()
print(duanzi_author)
duanzi_content = duanzidiv.xpath(".//div[@class='content']//text()").getall()
duanzi_content = "".join(duanzi_content).strip()
print(duanzi_content)
# 这里的对象是在items中定义好的
item = ScrapyDemoItem(author=duanzi_author, content=duanzi_content)
# 这里的yield是给pipelines.py传递item对象
yield item
next_url = response.xpath("//ul[@class='pagination']/li[last()]/a/@href").get()
next_url = "https://www.qiushibaike.com" + next_url
# 如果是最后一页,就退出爬虫程序
if not next_url:
return
else:
yield scrapy.Request(next_url, callback=self.parse)
④ 在pipelines.py中下载解析好的内容:
这里的三个函数open_spider, process_item, close_spider是固定搭配
from scrapy.exporters import JsonLinesItemExporter
class ScrapyDemoPipeline:
def __init__(self):
self.fp = open("duanzi.json", 'wb')
self.exporter = JsonLinesItemExporter(self.fp, ensure_ascii=False, encoding='utf-8')
def open_spider(self, spider):
print("爬虫开始了...")
def process_item(self, item, spider):
self.exporter.export_item(item)
return item
def close_spider(self,spider):
self.fp.close()
print("爬虫结束了...")
⑤ 运行方式:
在项目目录下进入终端界面,输入:
其中qsbk_spider是爬虫名
scrapy crawl qsbk_spider
或者新建一个.py文件,在里面写:
from scrapy import cmdline
cmdline.execute("scrapy crawl qsbk_spider".split())
运行结果如下,截至目前(2020-05-03)有效:
每页25条,有13页,总共325条数据。
