哈希表
哈希表就是将 数组值与索引建立关系, 而不考虑待查找值与序列值一个个比较这种方式。 不比较,直接对应。
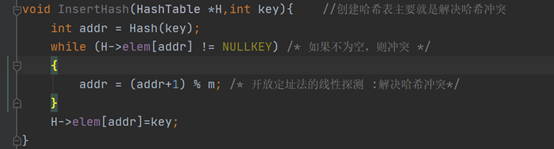
怎么对应: 哈希算法(哈希函数)-- 典例- 取余法,



什么叫基本存储结构:
数组即一块连续的内存存储空间, 在此之上引入了索引这个逻辑来定位数组元素,所以底层使用数组的数据结构, 逻辑都是建立在数组索引这个逻辑结构上的(索引间存在逻辑关系) 一块连续的内存存储空间 + 索引 = 数组, 其实基本存储结构就是一块连续的内存存储空间
链表就是不连续的几块内存存储空间, 在此之上引入指针这个逻辑来把 不连续的内存连接起来 然后约定俗成将: 不连续的几块内存存储空间+ 指针 = 链表
数组的存储结构是一块连续的内存存储空间, 逻辑结构是连续的索引 ,
链表的存储结构是几块不连续的内存存储空间, 逻辑结构是指针
广义上的数组和链表,已经加了一层逻辑了。 本质上的数组和链表,就是内存条上的连续或不连续块 连续的索引,本身就是一种逻辑了, 数组索引只是表达地址的一种方法, 大可以把数组写成 a[0],a[3],a[7]
存储结构解决的是存到哪里的问题, 任何逻辑结构都可以用两种基本存储结构来存储
逻辑结构解决的是 元素之间有怎么的关系的问题(通过一个元素,怎么找到其他元素)

哈希表就是建立在本质数组上的不同逻辑, 描述的是元素的地址与元素的值之间的关系
而不是其他数据结构,描述的是 各个元素间地址的关系
任何数据结构与算法,都有两个个基本对象
元素内容,元素地址,
不同元素内容之间的逻辑,不同元素地址之间的逻辑(即索引之前的关系),同一个元素自身内容与地址之间的逻辑(哈希函数)
不同元素内容之间的逻辑:
1.搜索二叉树就对元素内容间的逻辑有规定,一定要大中下这么排。 元素内容关系决定了 元素地址之间的关系(比较元素大小,从而确定元素存储到哪里)
2.排序算法解决的也是内容间的逻辑, 要求内容从小到大, 元素的内容关系决定了元素地址之间的逻辑
不同元素地址之间的逻辑(索引之间的逻辑):
总结: 对象(4)-关系(3)-逻辑(3)-内存(2)
最基本的就是 一块连续内存条 和几块不连续内存条
在此之上建立四个对象(元素A的内容,元素A的地址,元素B的内容,元素B的地址),存在三个关系(数据的内容,数据的地址),
然后建立三种逻辑来描述四个对象之间的关系
所以问一个数据结构
1.根据需求,确定是哪两个对象间的关系 (排序,描述的就是元素A内容与元素B内容间的关系) – 内容关系
2.根据需求,确定是哪种逻辑: 内容的排序逻辑
3.根据元素A内容与元素B内容之间的逻辑,确定元素A地址与元素B地址之间的逻辑(用什么样的地址去实现这种内容逻辑?)
4.存在连续内存条上 还是 不连续内存条上?
需求: 查询
1.对象确定关系:元素A内容与元素A地址间的关系
2.逻辑描述关系: 哈希函数 (元素A的内容与元素A的地址之间的逻辑)
3.存储在连续内存条上(由处理冲突的方式决定)
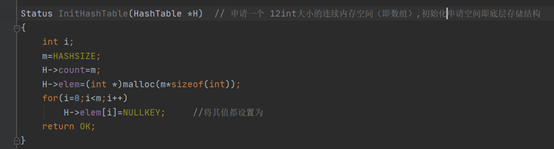
初始化申请空间即声明底层存储结构: 连续的一块内存空间
递归
递归和循环的共同点:都是 EIP 在同一段代码段内反复。
两者在模型,重复代码段之间的层次结构,和流程控制方面的差异:
递归是自相似的,两次重复代码段之间,是有结构,层次上的“父子”关系的。
循环,是在同一个层次之内的
递归可以回到数据中点,再向反方向推进
两者在流程控制上有差别: 放到汇编层次,两者的不同就显示出来了
递归通过 ret 可以回到重复代码段的中间位置(由 stack 负责记忆),这个跳转,就是递归相对于循环比较特殊的地方,也导致,递归改成循环的困难点。
必须有序,我们很难保证我们的数组都是有序的。当然可以在构建数组的时候进行排序,可是又落到了第二个瓶颈上:它必须是数组。
数组读取效率是O(1),可是它的插入和删除某个元素的效率却是O(n)。因而导致构建有序数组变成低效的事情。 所以引入二分查找树的概念来解决这些问题
二分查找法是递归定义的,因为相同代码片段间,是有父子的层次结构的
所以二分查找法最好用递归写,才是最符合逻辑的
用循环也可以写,但深层次的思维模型中是不契合的
以递归形式定义,但二分查找是尾递归,可改写为循环
如果一个函数中所有递归形式的调用都出现在函数的末尾,我们称这个递归函数是尾递归的。尾递归函数的特点是在回归过程中不用做任何操作。 尾递归都可以改写为循环。
https://www.zhihu.com/question/20418254